常见网络编程问题
1:tcp和udp的区别
2:流量控制和拥塞控制的实现机制
3:滑动窗口的实现机制
4:多线程如何同步。
5:进程间通讯的方式有哪些,各有什么优缺点
6:tcp连接建立的时候3次握手的具体过程,以及其中的每一步是为什么
7:tcp断开连接的具体过程,其中每一步是为什么那么做
8:tcp建立连接和断开连接的各种过程中的状态转换细节
9:epool与select的区别
10:epool中et和lt的区别与实现原理
11:写一个server程序需要注意哪些问题
12:项目中遇到的难题,你是如何解决的
1.tcp和udp的区别:
TCP与UDP区别
TCP---传输控制协议,提供的是面向连接、可靠的字节流服务。当客户和服务器彼此交换数据前,必须先在双方之间建立一个TCP连接,之后才能传输数据。TCP提供超时重发,丢弃重复数据,检验数据,流量控制等功能,保证数据能从一端传到另一端。
UDP---用户数据报协议,是一个简单的面向数据报的运输层协议。UDP不提供可靠性,它只是把应用程序传给IP层的数据报发送出去,但是并不能保证它们能到达目的地。由于UDP在传输数据报前不用在客户和服务器之间建立一个连接,且没有超时重发等机制,故而传输速度很快
Overview
TCP (Transmission Control Protocol) is the most commonly used protocol on the Internet. The reason for this is because TCP offers error correction. When the TCP protocol is used there is a "guaranteed delivery." This is due largely in part to a method called "flow control." Flow control determines when data needs to be re-sent, and stops the flow of data until previous packets are successfully transferred. This works because if a packet of data is sent, a collision may occur. When this happens, the client re-requests the packet from the server until the whole packet is complete and is identical to its original.
UDP (User Datagram Protocol) is anther commonly used protocol on the Internet. However, UDP is never used to send important data such as webpages, database information, etc; UDP is commonly used for streaming audio and video. Streaming media such as Windows Media audio files (.WMA) , Real Player (.RM), and others use UDP because it offers speed! The reason UDP is faster than TCP is because there is no form of flow control or error correction. The data sent over the Internet is affected by collisions, and errors will be present. Remember that UDP is only concerned with speed. This is the main reason why streaming media is not high quality.


On the contrary, UDP has been implemented among some trojan horse viruses. Hackers develop scripts and trojans to run over UDP in order to mask their activities. UDP packets are also used in DoS (Denial of Service) attacks. It is important to know the difference between TCP port 80 and UDP port 80. If you don't know what ports are go here.
Frame Structure
As data moves along a network, various attributes are added to the file to create a frame. This process is called encapsulation. There are different methods of encapsulation depending on which protocol and topology are being used. As a result, the frame structure of these packets differ as well. The images below show both the TCP and UDP frame structures.
TCP FRAME STRUCTURE

UDP FRAME STRUCTURE

The payload field contains the actually data. Notice that TCP has a more complex frame structure. This is largely due to the fact the TCP is a connection-oriented protocol. The extra fields are need to ensure the "guaranteed delivery" offered by TCP.
UDP
UDP 与 TCP 的主要区别在于 UDP 不一定提供可靠的数据传输。事实上,该协议不能保证数据准确无误地到达目的地。UDP 在许多方面非常有效。当某个程序的目标是尽快地传输尽可能多的信息时(其中任意给定数据的重要性相对较低),可使用 UDP。ICQ 短消息使用 UDP 协议发送消息。
许多程序将使用单独的TCP连接和单独的UDP连接。重要的状态信息随可靠的TCP连接发送,而主数据流通过UDP发送。
TCP
TCP的目的是提供可靠的数据传输,并在相互进行通信的设备或服务之间保持一个虚拟连接。TCP在数据包接收无序、丢失或在交付期间被破坏时,负责数据恢复。它通过为其发送的每个数据包提供一个序号来完成此恢复。记住,较低的网络层会将每个数据包视为一个独立的单元,因此,数据包可以沿完全不同的路径发送,即使它们都是同一消息的组成部分。这种路由与网络层处理分段和重新组装数据包的方式非常相似,只是级别更高而已。
为确保正确地接收数据,TCP要求在目标计算机成功收到数据时发回一个确认(即 ACK)。如果在某个时限内未收到相应的 ACK,将重新传送数据包。如果网络拥塞,这种重新传送将导致发送的数据包重复。但是,接收计算机可使用数据包的序号来确定它是否为重复数据包,并在必要时丢弃它。
TCP与UDP的选择
如果比较UDP包和TCP包的结构,很明显UDP包不具备TCP包复杂的可靠性与控制机制。与TCP协议相同,UDP的源端口数和目的端口数也都支持一台主机上的多个应用。一个16位的UDP包包含了一个字节长的头部和数据的长度,校验码域使其可以进行整体校验。(许多应用只支持UDP,如:多媒体数据流,不产生任何额外的数据,即使知道有破坏的包也不进行重发。)
很明显,当数据传输的性能必须让位于数据传输的完整性、可控制性和可靠性时,TCP协议是当然的选择。当强调传输性能而不是传输的完整性时,如:音频和多媒体应用,UDP是最好的选择。在数据传输时间很短,以至于此前的连接过程成为整个流量主体的情况下,UDP也是一个好的选择,如:DNS交换。把SNMP建立在UDP上的部分原因是设计者认为当发生网络阻塞时,UDP较低的开销使其有更好的机会去传送管理数据。TCP丰富的功能有时会导致不可预料的性能低下,但是我们相信在不远的将来,TCP可靠的点对点连接将会用于绝大多数的网络应用。
2:流量控制和拥塞控制的实现机制
|
拥塞控制
网络拥塞现象是指到达通信子网中某一部分的分组数量过多,使得该部分网络来不及处理,以致引起这部分乃至整个网络性能下降的现象,严重时甚至会导致网络通信业务陷入停顿,即出现死锁现象。拥塞控制是处理网络拥塞现象的一种机制。 流量控制 数据的传送与接收过程当中很可能出现收方来不及接收的情况,这时就需要对发方进行控制,以免数据丢失。 流量控制机制:流量控制用于防止在端口阻塞的情况下丢帧,这种方法是当发送或接收缓冲区开始溢出时通过将阻塞信号发送回源地址实现的。流量控制可以有效的防止由于网络中瞬间的大量数据对网络带来的冲击,保证用户网络高效而稳定的运行。 TCP的拥塞控制
|
TCP窗口和拥塞控制实现机制
TCP数据包格式
| Source Port |
Destination port |
||
| Sequence Number |
|||
| Acknowledgement Number |
|||
| Length |
Reserved |
Control Flags |
Window Size |
| Check sum |
Urgent Pointer |
||
| Options |
|||
| DATA |
|||
注:校验和是对所有数据包进行计算的。
TCP包的处理流程
接收:
ip_local_deliver
↓
tcp_v4_rcv() (tcp_ipv4.c)→_tcp_v4_lookup()
↓
tcp_v4_do_rcv(tcp_ipv4.c)→tcp_rcv_state_process (OTHER STATES)
↓Established
tcp_rcv_established(tcp_in→tcp_ack_snd_check,(tcp_data_snd_check,tcp_ack (tcp_input.c)
↓ ↓ ↓ ↓
tcp_data tcp_send_ack tcp_write_xmit
↓ (slow) ↓(Fast) ↓
tcp_data_queue tcp_transmit_skb
↓ ↓ ↓
sk->data_ready (应用层) ip_queque_xmit
发送:
send
↓
tcp_sendmsg
↓
__tcp_push_pending_frames tcp_write_timer
↓ ↓
tcp_ retransmit_skb
↓
tcp_transmit_skb
↓
ip_queue_xmit
TCP段的接收
_tcp_v4_lookup()用于在活动套接字的散列表中搜索套接字或SOCK结构体。
tcp_ack (tcp_input.c)用于处理确认包或具有有效ACK号的数据包的接受所涉及的所有任务:
调整接受窗口(tcp_ack_update_window())
删除重新传输队列中已确认的数据包(tcp_clean_rtx_queue())
对零窗口探测确认进行检查
调整拥塞窗口(tcp_may_raise_cwnd())
重新传输数据包并更新重新传输计时器
tcp_event_data_recv()用于处理载荷接受所需的所有管理工作,包括最大段大小的更新,时间戳的更新,延迟计时器的更新。
tcp_data_snd_check(sk)检查数据是否准备完毕并在传输队列中等待,且它会启动传输过程(如果滑动窗口机制的传输窗口和拥塞控制窗口允许的话),实际传输过程由tcp_write_xmit()启动的。(这里进行流量控制和拥塞控制)
tcp_ack_snd_check()用于检查可以发送确认的各种情形,同样它会检查确认的类型(它应该是快速的还是应该被延迟的)。
tcp_fast_parse_options(sk,th,tp)用于处理TCP数据包报头中的Timestamp选项。
tcp_rcv_state_process()用于在TCP连接不处在ESTABLISHED状态的时候处理输入段。它主要用于处理该连接的状态变换和管理工作。
Tcp_sequence()通过使用序列号来检查所到达的数据包是否是无序的。如果它是一个无序的数据包,测激活QuickAck模式,以尽可能快地将确认发送出去。
Tcp_reset()用来重置连接,且会释放套接字缓冲区。
TCP段的发送
tcp_sendmsg()(TCP.C)用于将用户地址空间中的载荷拷贝至内核中并开始以TCP段形式发送数据。在发送启动前,它会检查连接是否已经建立及它是否处于TCP_ESTABLISHED状态,如果还没有建立连接,那么系统调用会在wait_for_tcp_connect()一直等待直至有一个连接存在。
tcp_select_window() 用来进行窗口的选择计算,以此进行流量控制。
tcp_send_skb()(tcp_output.c)用来将套接字缓冲区SKB添加到套接字传输队列(sk->write_queue)并决定传输是否可以启动或者它必须在队列中等待。它通过tcp_snd_test()例程来作出决定。如果结果是负的,那么套接字缓冲区就仍留在传输队列中; 如果传输成功的话,自动传输的计时器会在tcp_reset_xmit_timer()中自动启动,如果某一特定时间后无该数据包的确认到达,那么计时器就会启动。(尚未找到调用之处)(只有在发送FIN包时才会调用此函数,其它情况下都不会调用此函数2007,06,15)
tcp_snd_test()(tcp.h) 它用于检查TCP段SKB是否可以在调用时发送。
tcp_write_xmit()(tcp_output.c)它调用tcp_transmit_skb()函数来进行包的发送,它首先要查看此时TCP是否处于CLOSE状态,如果不是此状态则可以发送包.进入循环,从SKB_BUF中取包,测试是否可以发送包(),接下来查看是否要分片,分片完后调用tcp_transmit_skb()函数进行包的发送,直到发生拥塞则跳出循环,然后更新拥塞窗口.
tcp_transmits_skb()(TCP_OUTPUT.C)负责完备套接字缓冲区SKB中的TCP段以及随后通过Internet协议将其发送。并且会在此函数中添加TCP报头,最后调用tp->af_specific->queue_xmit)发送TCP包.
tcp_push_pending_frames()用于检查是否存在传输准备完毕而在常规传输尝试期间无法发送的段。如果是这样的情况,则由tcp_write_xmit()启动这些段的传输过程。
TCP实例的数据结构
Struct tcp_opt sock.h
包含了用于TCP连接的TCP算法的所有变量。主要由以下部分算法或协议机制的变量组成:
序列和确认号
流控制信息
数据包往返时间
计时器
数据包头中的TCP选项
自动和选择性数据包重传
TCP状态机
tcp_rcv_state_process()主要处理状态转变和连接的管理工作,接到数据报的时候不同状态会有不同的动作。
tcp_urg()负责对紧急数据进行处理
建立连接
tcp_v4_init_sock()(tcp_ipv4.c)用于运行各种初始化动作:初始化队列和计时器,初始化慢速启动和最大段大小的变量,设定恰当的状态以及设定特定于PF_INET的例程的指针。
tcp_setsockopt()(tcp.c)该函数用于设定TCP协议的服务用户所选定的选项:TCP_MAXSEG,TCP_NODELAY, TCP_CORK, TCP_KEEPIDLE, TCP_KEEPINTVL, TCP_KEEPCNT, TCP_SYNCNT, TCP_LINGER2, TCP_DEFER_ACCEPT和TCP_WINDOW_CLAMP.
tcp_connect()(tcp_output.c)该函数用于初始化输出连接:它为sk_buff结构体中的数据单元报头预留存储空间,初始化滑动窗口变量,设定最大段长度,设定TCP报头,设定合适的TCP状态,为重新初始化计时器和控制变量,最后,将一份初始化段的拷贝传递给tcp_transmit_skb()例程,以便进行连接建立段的重新传输发送并设定计时器。
从发送方和接收方角度看字节序列域
如下图示:
| snd_una |
| snd_nxt |
| snd_una+snd+wnd |
| rcv_wup |
| rcv_nxt |
| rcv_wup+rcv_wnd |
| 数据以经确认 |
| 数据尚未确认 |
| 剩余传输窗口 |
| 右窗口边界 |
| 数据以经确认 |
| 数据尚未确认 |
| 剩余传输窗口 |
流控制
流控制用于预防接受方TCP实例的接受缓冲区溢出。为了实现流控制,TCP协议使用了滑动窗口机制。该机制以由接受方所进行的显式传输资信分配为基础。
滑动窗口机制提供的三项重要作业:
分段并发送于若干数据包中的数据集初始顺序可以在接收方恢复。
可以通过数据包的排序来识别丢失的或重复的数据包。
两个TCP实例之间的数据流可以通过传输资信赋值来加以控制。
Tcp_select_window()
当发送一个TCP段用以指定传输资信大小的时候就会在tcp_transmit_skb()方法中调用tcp_select_window()。当前通告窗口的大小最初是由tcp_receive_window()指定的。随后通过tcp_select_window()函数来查看该计算机中还有多少可用缓冲空间。这就够成了哪个提供给伙伴实例的新传输资信的决定基础。
一旦已经计算出新的通告窗口,就会将该资信(窗口信息)存储在该连接的tcp_opt结构体(tp->rcv_wnd)中。同样,tp->rcv_wup也会得到调整;它会在计算和发送新的资信的时候存储tp->rcv_nxt变量的当前值,这也就是通常所说的窗口更新。这是因为,在通告窗口已发送之后到达的每一个数据包都必须冲销其被授予的资信(窗口信息)。
另外,该方法中还使用另一种TCP算法,即通常所说的窗口缩放算法。为了能够使得传输和接收窗口的16位数字运作起来有意义,就必须引入该算法。基于这个原因,我们引入了一个缩放因子:它指定了用以将窗口大小移至左边的比特数目,利用值Fin tp->rcv_wscale, 这就相当于因子为2F 的通告窗口增加。
Tcp_receive_window()(tcp.c)用于计算在最后一段中所授予的传输资信还有多少剩余,并将自那时起接收到的数据数量考虑进去。
Tcp_select_window()(tcp_output.c)用于检查该连接有多少存储空间可以用于接收缓冲区以及可以为接收窗口选择多大的尺寸。
Tcp_space()确定可用缓冲区存储空间有多大。在所确定的缓冲区空间进行一些调整后,它最后检查是否有足够的缓冲区空间用于最大尺寸的TCP段。如果不是这样,则意味着已经出现了痴呆窗口综合症(SWS)。为了避免SWS的出现,在这种情形下所授予的资信就不会小于协议最大段。
如果可用缓冲区空间大于最大段大小,则继续计算新的接收窗口。该窗口变量被设定为最后授予的那个资信的值(tcp->rcv_wnd)。如果旧的资信大于或小于多个段大小的数量,则窗口被设定为空闲缓冲区空间最大段大小的下一个更小的倍数。以这种方式计算的窗口值是作为新接收资信的参考而返回的。
Tcp_probe_timer()(tcp_timer.c)是零窗口探测计时器的处理例程。它首先检查同位体在一段较长期间上是否曾提供了一个有意义的传输窗口。如果有若干个窗口探测发送失败,则输出一个错误消息以宣布该TCP连接中存在严重并通过tcp_done()关闭该连接。主要是用来对方通告窗口为0,则每隔定时间探测通告窗口是否有效.
如果还未达到该最大窗口探测数目,则由tcp_send_probe0()发送一个没有载荷的TCP段,且确认段此后将授予一个大于NULL的资信。
Tcp_send_probe0()(tcp_output.c)利用tcp_write_wakeup(sk)来生成并发送零窗口探测数据包。如果不在需要探测计时器,或者当前仍旧存在途中数据包且它们的ACK不含有新的资信,那么它就不会得到重新启动,且probes_out和backoff 参数会得到重置。
否则,在已经发送一个探测数据包后这些参数会被增量,且零窗口探测计时器会得到重新启动,这样它在某一时间后会再次到期。
Tcp_write_wakeup()(tcp_output.c)用于检查传输窗口是否具有NULL大小以及SKB中数据段的开头是否仍旧位于传输窗口范围以内。到目前为止所讨论的零窗口问题的情形中,传输窗口具有NULL大小,所以tcp_xmit_probe_skb()会在else分支中得到调用。它会生成所需的零窗口探测数据包。如果满足以上条件,且如果该传输队列中至少存在一个传输窗口范围以内的数据包,则我们很可能就碰到了痴呆综合症的情况。和当前传输窗口的要求对应的数据包是由tcp_transmit_skb()生成并发送的。
Tcp_xmit_probe_skb(sk,urgent)(tcp_output.c)会创建一个没有载荷的TCP段,因为传输窗口大小NULL,且当前不得传输数据。Alloc_skb()会取得一个具有长度MAX_TCP_HEADER的套接字缓冲区。如前所述,将无载荷发送,且数据包仅仅由该数据包报头组成。
Tcp_ack_probe() (tcp_input.c) 当接收到一个ACK标记已设定的TCP段且如果怀疑它是对某一零窗口探测段的应答的时候,就会在tcp_ack()调用tcp_ack_probe()。根据该段是否开启了接受窗口,由tcp_clear_xmit_timer()停止该零窗口探测计时器或者由tcp_reset_xmit_timer()重新起用该计时器。
拥塞检测、回避和处理
流控制确保了发送到接受方TCP实例的数据数量是该实例能够容纳的,以避免数据包在接收方端系统中丢失。然而,该转发系统中可能会出现缓冲区益处——具体来说,是在Internet 协议的队列中,当它们清空的速度不够快且到达的数据多于能够通过网络适配器得到发送的数据量的时候,这种情况称为拥塞。
TCP拥塞控制是通过控制一些重要参数的改变而实现的。TCP用于拥塞控制的参数主要有:
(1) 拥塞窗口(cwnd):拥塞控制的关键参数,它描述源端在拥塞控制情况下一次最多能发送的数据包的数量。
(2) 通告窗口(awin):接收端给源端预设的发送窗口大小,它只在TCP连接建立的初始阶段发挥作用。
(3) 发送窗口(win):源端每次实际发送数据的窗口大小。
(4) 慢启动阈值(ssthresh):拥塞控制中慢启动阶段和拥塞避免阶段的分界点。初始值通常设为65535byte。
(5) 回路响应时间(RTT):一个TCP数据包从源端发送到接收端,源端收到接收端确认的时间间隔。
(6) 超时重传计数器(RTO):描述数据包从发送到失效的时间间隔,是判断数据包丢失与否及网络是否拥塞的重要参数。通常设为2RTT或5RTT。
(7) 快速重传阈值(tcprexmtthresh)::能触发快速重传的源端收到重复确认包ACK的个数。当此个数超过tcprexmtthresh时,网络就进入快速重传阶段。tcprexmtthresh缺省值为3。
四个阶段
1.慢启动阶段
旧的TCP在启动一个连接时会向网络发送许多数据包,由于一些路由器必须对数据包进行排队,因此有可能耗尽存储空间,从而导致TCP连接的吞吐量(throughput)急剧下降。避免这种情况发生的算法就是慢启动。当建立新的TCP连接时,拥塞窗口被初始化为一个数据包大小(一个数据包缺省值为536或512byte)。源端按cwnd大小发送数据,每收到一个ACK确认,cwnd就增加一个数据包发送量。显然,cwnd的增长将随RTT呈指数级(exponential)增长:1个、2个、4个、8个……。源端向网络中发送的数据量将急剧增加。
2.拥塞避免阶段
当发现超时或收到3个相同ACK确认帧时,网络即发生拥塞(这一假定是基于由传输引起的数据包损坏和丢失的概率小于1%)。此时就进入拥塞避免阶段。慢启动阈值被设置为当前cwnd的一半;超时时,cwnd被置为1。如果cwnd≤ssthresh,则TCP重新进入慢启动过程;如果cwnd>ssthresh,则TCP执行拥塞避免算法,cwnd在每次收到一个ACK时只增加1/cwnd个数据包(这里将数据包大小segsize假定为1)。
3.快速重传和恢复阶段
当数据包超时时,cwnd被设置为1,重新进入慢启动,这会导致过大地减小发送窗口尺寸,降低TCP连接的吞吐量。因此快速重传和恢复就是在源端收到3个或3个以上重复ACK时,就断定数据包已经被丢失,并重传数据包,同时将ssthresh设置为当前cwnd的一半,而不必等到RTO超时。图2和图3反映了拥塞控制窗口随时间在四个阶段的变化情况。
TCP用来检测拥塞的机制的算法:
1、 超时。
一旦某个数据包已经发送,重传计时器就会等待一个确认一段时间,如果没有确认到达,就认为某一拥塞导致了该数据包的丢失。对丢失的数据包的初始响应是慢速启动阶段,它从某个特定点起会被拥塞回避算法替代。
2、 重复确认
重复确认的接受表示某个数据段的丢失,因为,虽然随后的段到达了,但基于累积ACK段的原因它们却不能得到确认,。在这种情形下,通常认为没有出现严重的拥塞问题,因为随后的段实际上是接收到了。基于这个原因,更为新近的TCP版本对经由慢速启动阶段的丢失问题并不响应,而是对经由快速传输和快速恢复方法的丢失作出反应。
慢速启动和拥塞回避
Tcp_cong_avoid() (tcp_input.c)用于在慢速启动和拥塞回避算法中实现拥塞窗口增长。当某个具有有效确认ACK的输入TCP段在tcp_ack()中进行处理时就会调用tcp_cong_avoid()
首先,会检查该TCP连接是否仍旧处于慢速启动阶段,或者已经处于拥塞回避阶段:
在慢速启动阶段拥塞窗口会增加一个单位。但是,它不得超过上限值,这就意味着,在这一阶段,伴随每一输入确认,拥塞窗口都会增加一个单位。在实践中,这意味着可以发送的数据量每次都会加倍。
在拥塞回避阶段,只有先前已经接收到N个确认的时候拥塞窗口才会增加一个单位,其中N等于当前拥塞窗口值。要实现这一行为就需要引入补充变量tp->snd_cwnd_cnt;伴随每一输入确认,它都会增量一个单位。下一步,当达到拥塞窗口值tp->snd_cwnd的时候,tp->snd_cwnd就会最终增加一个单位,且tp->snd_cwnd_cnt得到重置。通过这一方法就能完成线形增长。
总结:拥塞窗口最初有一个指数增长,但是,一旦达到阈值,就存在线形增长了。
Tcp_enter_loss(sk,how) (tcp_input.c)是在重传计时器的处理例程中进行调用的,只有重传超时期满时所传输的数据段还未得到确认,该计时器就会启动。这里假定该数据段或它的确认已丢失。在除了无线网络的现代网络中,数据包丢失仅仅出现在拥塞情形中,且为了处理缓冲区溢出的问题将不得不在转发系统中丢弃数据包。重传定时器定时到时调用,用来计算CWND和阈值重传丢失数据,并且进入慢启动状态.
Tcp_recal_ssthresh() (tcp.h)一旦检测到了某个拥塞情形,就会在tcp_recalc_ssthresh(tp)中重新计算慢速启动阶段中指数增长的阈值。因此,一旦检测到该拥塞,当前拥塞窗口tp->snd_cwnd的大小就会被减半,并作为新的阈值被返回。该阈值不小于2。
快速重传和快速恢复
TCP协议中集成可快速重传算法以快速检测出单个数据包的丢失。先前检测数据包丢失的唯一依据是重传计时器的到期,且TCP通过减少慢速启动阶段中的传输速率来响应这一问题。新的快速重传算法使得TCP能够在重传计时器到期之前检测出数据包丢失,这也就是说,当一连串众多段中某一段丢失的时候。接收方通过发送重复确认的方法来响应有一个段丢失的输入数据段。
LINUX内核的TCP实例中两个算法的协作方式:
▉ 当接收到了三个确认复本时,变量tp->snd_ssthresh就会被设定为当前传办理窗口的一半.丢失的段会得到重传,且拥塞窗口tp->snd_cwnd会取值tp->ssthresh+3*MSS,其中MSS表示最大段大小.
▉ 每接收到一个重复确认,拥塞窗口tp->snd_cwnd 就会增加一个最大段大小的值,且会发送一个附加段(如果传输窗口大小允许的话)
▉ 当新数据的第一个确认到达时,此时tp->snd_cwnd就会取tp->snd_ssthresh的原如值,它存储在tp->prior_ssthresh中.这一确认应该对最初丢失的那个数据段进行确认.另外还应该确认所有在丢失数据包和第三个确认复本之间发送的段.
TCP中的计时器管理
Struct timer_list
{ struct timer_head list;
unsigned long expires;
unsigned long data;
void (*function) (unsighed long);
volatile int running;
}
tcp_init_xmit_timers()(tcp_timer.c)用于初始化一组不同的计时器。Timer_list会被挂钩进来,且函数指针被转换到相应的行为函数。
Tcp_clear_xmit_timer()(tcp.h)用于删除timer_list结构体链表中某个连接的所有计时器组。
Tcp_reset_xmit_timer(sk,what,when)(tcp.h)用于设定在what到时间when中指定的计时器。
TCP数据发送流程具体流程应该是这样的:
tcp_sendmsg()----->tcp_push_one()/tcp_push()----
| |
| \|/
|--------------->__tcp_push_pending_frames()
|
\|/
tcp_write_xmit()
|
\|/
tcp_transmit_skb()
tcp_sendmsg()-->__tcp_push_pending_frames() --> tcp_write_xmit()-->tcp_transmit_skb()
write_queue 是发送队列,包括已经发送的但还未确认的和还从未发送的,send_head指向其中的从未发送之第一个skb。 另外,仔细看了看tcp_sendmsg(),觉得它还是希望来一个skb 就发送一个skb,即尽快发送的策略。
有两种情况,
一,mss > tp->max_window/2,则forced_push()总为真,这样, 每来一个skb,就调用__tcp_push_pending_frames(),争取发送。
二,mss < tp->max_window/2,因此一开始forced_push()为假, 但由于一开始send_head==NULL,因此会调用tcp_push_one(), 而它也是调用__tcp_push_pending_frames(),如果此时网络情况 良好,数据会顺利发出,并很快确认,从而send_head又为NULL,这样下一次数据拷贝时,又可以顺利发出。这就是说, 在网络情况好时,tcp_sendmsg()会来一个skb就发送一个skb。
只有当网络情况出现拥塞或延迟,send_head不能及时发出, 从而不能走tcp_push_one()这条线,才会看数据的积累,此时, 每当数据积累到tp->max_window/2时,就尝试push一下。
而当拷贝数据的总量很少时,上述两种情况都可能不会满足,
这样,在循环结束时会调用一次tcp_push(),即每次用户的完整
一次发送会有一次push。
TCP包接收器(tcp_v4_rcv)将TCP包投递到目的套接字进行接收处理. 当套接字正被用户锁定, TCP包将暂时排入该套接字的后备队列(sk_add_backlog). 这时如果某一用户线程企图锁定该套接字(lock_sock), 该线程被排入套接字的后备处理等待队列(sk->lock.wq). 当用户释放上锁的套接字时(release_sock), 后备队列中的TCP包被立即注入TCP包处理器(tcp_v4_do_rcv)进行处理, 然后唤醒等待队列中最先的一个用户来获得其锁定权. 如果套接字未被上锁, 当用户正在读取该套接字时, TCP包将被排入套接字的预备队列(tcp_prequeue), 将其传递到该用户线程上下文中进行处理.
TCP定时器(TCP/IP详解2)
TCP为每条连接建立七个定时器:
1、 连接建立定时器在发送SYN报文段建立一条新连接时启动。如果没有在75秒内收到响 应,连接建立将中止。
当TCP实例将其状态从LISTEN更改为SYN_RECV的时侯就会使用这一计时器.服务端的TCP实例最初会等待一个ACK三秒钟.如果在这一段时间没有ACK到达,则认为该连接请求是过期的.
2、 重传定时器在TCP发送数据时设定.如果定时器已超时而对端的确认还未到达,TCP将重传数据.重传定时器的值(即TCP等待对端确认的时间)是动态计算的,取决于TCP为该 连接测量的往返时间和该报文段已重传几次.
3、 延迟ACK定时器在TCP收到必须被确认但无需马上发出确认的数据时设定.TCP等 待时间200MS后发送确认响应.如果,在这200MS内,有数据要在该连接上发送,延迟的ACK响应就可随着数据一起发送回对端,称为稍带确认.
4、 持续定时器在连接对端通告接收窗口为0,阻止TCP继续发送数据时设定.由于连接对端发送的窗口通告不可靠,允许TCP继续发送数据的后续窗口更新有可能丢失.因此,如果TCP有数据要发送,但对端通告接收窗口为0,则持续定时器启动,超时后向对端发送1字节的数据,判定对端接收窗口是否已打开.与重传定时器类似,持续定时器的值也是动态计算的,取决于连接的往返时间,在5秒到60秒之间取值.
5、 保活定时器在应用进程选取了插口的SO_KEEPALIVE选项时生效.如果连接的连续空闲时间超过2小时,保活定时器超时,向对端发送连接探测报文段,强迫对端响应.如果收到了期待的响应,TCP确定对端主机工作正常,在该连接再次空闲超过2小时之前,TCP不会再进行保活测试,.如果收到的是其它响应,TCP确定对端主要已重启.如果连纽若干次保活测试都未收到响应,TCP就假定对端主机已崩溃,尽管它无法区分是主机帮障还是连接故障.
6、 FIN_WAIT-2定时器,当某个连接从FIN_WAIT-1状态变迁到FIN_WAIN_2状态,并且不能再接收任何数据时,FIN_WAIT_2定时器启动,设为10分钟,定时器超时后,重新设为75秒,第二次超时后连接被关闭,加入这个定时器的目的为了避免如果对端一直不发送FIN,某个连接会永远滞留在FIN_WAIT_2状态.
7、 TIME_WAIT定时器,一般也称为2MSL定时器.2MS指两倍MSL.当连接转移到TIME_WAIT状态,即连接主动关闭时,定时器启动.连接进入TIME_WAIT状态时,定时器设定为1分钟,超时后,TCP控制块和INTERNET PCB被删除,端口号可重新使用.
TCP包含两个定时器函数:一个函数每200MS调用一次(快速定时器);另一个函数每500MS调用一次.延迟定时器与其它6个定时器有所不同;如果某个连接上设定了延迟ACK定时器,那么下一次200MS定时器超时后,延迟的ACK必须被发送.其它的定时器每500MS递减一次,计数器减为0时,就触发相应的动作.
3:滑动窗口的实现机制
TCP的滑动窗口机制
TCP这个协议是网络中使用的比较广泛,他是一个面向连接的可靠的传输协议。既然是一个可靠的传输协议就需要对数据进行确认。TCP协议里窗口机制有2种一种是固定的窗口大小。一种是滑动的窗口。这个窗口大小就是我们一次传输几个数据。
我们可以看下面一张图来分析一下固定窗口大小有什么问题。

这里我们可以看到假设窗口的大小是1,也是就每次只能发送一个数据只有接受方对这个数据进行确认了以后才能发送第2个数据。我们可以看到发送方每发送一个数据接受方就要给发送方一个ACK对这个数据进行确认。只有接受到了这个确认数据以后发送方才能传输下个数据。
这样我们考虑一下如果说窗口过小,那么当传输比较大的数据的时候需要不停的对数据进行确认,这个时候就会造成很大的延迟。如果说窗口的大小定义的过大。我们假设发送方一次发送100个数据。但是接收方只能处理50个数据。这样每次都会只对这50个数据进行确认。发送方下一次还是发送100个数据,但是接受方还是只能处理50个数据。这样就避免了不必要的数据来拥塞我们的链路。所以我们就引入了滑动窗口机制,窗口的大小并不是固定的而是根据我们之间的链路的带宽的大小,这个时候链路是否拥护塞。接受方是否能处理这么多数据了。
我们看看滑动窗口是如何工作的。我们看下面几张图。

首先是第一次发送数据这个时候的窗口大小是根据链路带宽的大小来决定的。我们假设这个时候窗口的大小是3。这个时候接受方收到数据以后会对数据进行确认告诉发送方我下次希望手到的是数据是多少。这里我们看到接收方发送的ACK=3。这个时候发送方收到这个数据以后就知道我第一次发送的3个数据对方只收到了2个。就知道第3个数据对方没有收到。下次在发送的时候就从第3个数据开始发。这个时候窗口大小就变成了2 。

这个时候发送方发送2个数据。
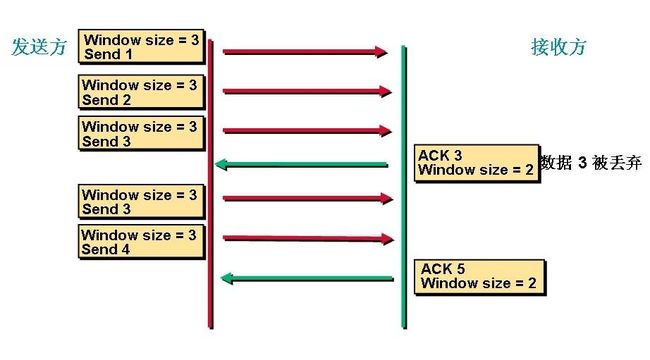
看到接收方发送的ACK是5就表示他下一次希望收到的数据是5,发送方就知道我刚才发送的2个数据对方收了这个时候开始发送第5个数据。
这就是滑动窗口的工作机制,当链路变好了或者变差了这个窗口还会发生变话,并不是第一次协商好了以后就永远不变了。
滑动窗口协议
滑动窗口协议,是TCP使用的一种流量控制方法。该协议允许发送方在停止并等待确认前可以连续发送多个分组。由于发送方不必每发一个分组就停下来等待确认,因此该协议可以加速数据的传输。
只有在接收窗口向前滑动时(与此同时也发送了确认),发送窗口才有可能向前滑动。
收发两端的窗口按照以上规律不断地向前滑动,因此这种协议又称为滑动窗口协议。
当发送窗口和接收窗口的大小都等于 1时,就是停止等待协议。
当发送窗口大于1,接收窗口等于1时,就是回退N步协议。
当发送窗口和接收窗口的大小均大于1时,就是选择重发协议。
协议中规定,对于窗口内未经确认的分组需要重传。这种分组的数量最多可以等于发送窗口的大小,即滑动窗口的大小n减去1(因为发送窗口不可能大于(n-1),起码接收窗口要大于等于1)。
工作原理
TCP协议在工作时,如果发送端的TCP协议软件每传输一个数据分组后,必须等待接收端的确认才能够发送下一个分组,由于网络传输的时延,将有大量时间被用于等待确认,导致传输效率低下。为此TCP在进行数据传输时使用了滑动窗口机制。
TCP滑动窗口用来暂存两台计算机问要传送的数据分组。每台运行TCP协议的计算机有两个滑动窗口:一个用于数据发送,另一个用于数据接收。发送端待发数据分组在缓冲区排队等待送出。被滑动窗口框入的分组,是可以在未收到接收确认的情况下最多送出的部分。滑动窗口左端标志X的分组,是已经被接收端确认收到的分组。随着新的确认到来,窗口不断向右滑动。
TCP协议软件依靠滑动窗口机制解决传输效率和流量控制问题。它可以在收到确认信息之前发送多个数据分组。这种机制使得网络通信处于忙碌状态,提高了整个网络的吞吐率,它还解决了端到端的通信流量控制问题,允许接收端在拥有容纳足够数据的缓冲之前对传输进行限制。在实际运行中,TCP滑动窗口的大小是可以随时调整的。收发端TCP协议软件在进行分组确认通信时,还交换滑动窗口控制信息,使得双方滑动窗口大小可以根据需要动态变化,达到在提高数据传输效率的同时,防止拥塞的发生。 称窗口左边沿向右边沿靠近为窗口合拢,这种现象发生在数据被发送和确认时。
当窗口右边沿向右移动时将允许发送更多的数据,称之为窗口张开。这种现象发生在另一端的接收进程读取已经确认的数据并释放了TCP的接收缓存时。 当右边沿向左移动时,称为窗口收缩。Host Requirements RFC强烈建议不要使用这种方式。但TCP必须能够在某一端产生这种情况时进行处理。
如果左边沿到达右边沿,则称其为一个零窗口。
注意事项
(1)发送方不必发送一个全窗口大小的数据。 (2)来自接收方的一个报文段确认数据并把窗口向右边滑动,这是因为窗口的大小事相对于确认序号的。 (3)窗口的大小可以减小,但是窗口的右边沿却不能够向左移动。 (4)接收方在发送一个ACK前不必等待窗口被填满。
滑动窗口
滑动窗口(Sliding window )是一种流量控制技术。早期的网络通信中,通信双方不会考虑网络的拥挤情况直接发送数据。由于大家不知道网络拥塞状况,一起发送数据,导致中间结点阻塞掉包,谁也发不了数据。所以就有了滑动窗口机制来解决此问题。参见滑动窗口如何根据网络拥塞发送数据仿真视频。图片是一个滑动窗口的实例:
滑动窗口协议是用来改善吞吐量的一种技术,即容许发送方在接收任何应答之前传送附加的包。接收方告诉发送方在某一时刻能送多少包(称窗口尺寸)。
TCP中采用滑动窗口来进行传输控制,滑动窗口的大小意味着接收方还有多大的缓冲区可以用于接收数据。发送方可以通过滑动窗口的大小来确定应该发送多少字节的数据。当滑动窗口为0时,发送方一般不能再发送数据报,但有两种情况除外,一种情况是可以发送紧急数据,例如,允许用户终止在远端机上的运行进程。另一种情况是发送方可以发送一个1字节的数据报来通知接收方重新声明它希望接收的下一字节及发送方的滑动窗口大小。
(1).窗口机制
滑动窗口协议的基本原理就是在任意时刻,发送方都维持了一个连续的允许发送的帧的序号,称为发送窗口;同时,接收方也维持了一个连续的允许接收的帧的序号,称为接收窗口。发送窗口和接收窗口的序号的上下界不一定要一样,甚至大小也可以不同。不同的滑动窗口协议窗口大小一般不同。发送方窗口内的序列号代表了那些已经被发送,但是还没有被确认的帧,或者是那些可以被发送的帧。下面举一个例子(假设发送窗口尺寸为2,接收窗口尺寸为1): 分析:①初始态,发送方没有帧发出,发送窗口前后沿相重合。接收方0号窗口打开,等待接收0号帧;②发送方打开0号窗口,表示已发出0帧但尚确认返回信息。此时接收窗口状态不变;③发送方打开0、1号窗口,表示0、1号帧均在等待确认之列。至此,发送方打开的窗口数已达规定限度,在未收到新的确认返回帧之前,发送方将暂停发送新的数据帧。接收窗口此时状态仍未变;④接收方已收到0号帧,0号窗口关闭,1号窗口打开,表示准备接收1号帧。此时发送窗口状态不变;⑤发送方收到接收方发来的0号帧确认返回信息,关闭0号窗口,表示从重发表中删除0号帧。此时接收窗口状态仍不变;⑥发送方继续发送2号帧,2号窗口打开,表示2号帧也纳入待确认之列。至此,发送方打开的窗口又已达规定限度,在未收到新的确认返回帧之前,发送方将暂停发送新的数据帧,此时接收窗口状态仍不变;⑦接收方已收到1号帧,1号窗口关闭,2号窗口打开,表示准备接收2号帧。此时发送窗口状态不变;⑧发送方收到接收方发来的1号帧收毕的确认信息,关闭1号窗口,表示从重发表中删除1号帧。此时接收窗口状态仍不变。 若从滑动窗口的观点来统一看待1比特滑动窗口、后退n及选择重传三种协议,它们的差别仅在于各自窗口尺寸的大小不同而已。1比特滑动窗口协议:发送窗口=1,接收窗口=1;后退n协议:发送窗口>1,接收窗口=1;选择重传协议:发送窗口>1,接收窗口>1。 (2).1比特滑动窗口协议 当发送窗口和接收窗口的大小固定为1时,滑动窗口协议退化为停等协议(stop-and-wait)。该协议规定发送方每发送一帧后就要停下来,等待接收方已正确接收的确认(acknowledgement)返回后才能继续发送下一帧。由于接收方需要判断接收到的帧是新发的帧还是重新发送的帧,因此发送方要为每一个帧加一个序号。由于停等协议规定只有一帧完全发送成功后才能发送新的帧,因而只用一比特来编号就够了。其发送方和接收方运行的流程图如图所示。 (3).后退n协议 由于停等协议要为每一个帧进行确认后才继续发送下一帧,大大降低了信道利用率,因此又提出了后退n协议。后退n协议中,发送方在发完一个数据帧后,不停下来等待应答帧,而是连续发送若干个数据帧,即使在连续发送过程中收到了接收方发来的应答帧,也可以继续发送。且发送方在每发送完一个数据帧时都要设置超时定时器。只要在所设置的超时时间内仍收到确认帧,就要重发相应的数据帧。如:当发送方发送了N个帧后,若发现该N帧的前一个帧在计时器超时后仍未返回其确认信息,则该帧被判为出错或丢失,此时发送方就不得不重新发送出错帧及其后的N帧。 从这里不难看出,后退n协议一方面因连续发送数据帧而提高了效率,但另一方面,在重传时又必须把原来已正确传送过的数据帧进行重传(仅因这些数据帧之前有一个数据帧出了错),这种做法又使传送效率降低。由此可见,若传输信道的传输质量很差因而误码率较大时,连续测协议不一定优于停止等待协议。此协议中的发送窗口的大小为k,接收窗口仍是1。 (4).选择重传协议 在后退n协议中,接收方若发现错误帧就不再接收后续的帧,即使是正确到达的帧,这显然是一种浪费。另一种效率更高的策略是当接收方发现某帧出错后,其后继续送来的正确的帧虽然不能立即递交给接收方的高层,但接收方仍可收下来,存放在一个缓冲区中,同时要求发送方重新传送出错的那一帧。一旦收到重新传来的帧后,就可以原已存于缓冲区中的其余帧一并按正确的顺序递交高层。这种方法称为选择重发(SELECTICE REPEAT),其工作过程如图所示。显然,选择重发减少了浪费,但要求接收方有足够大的缓冲区空间。 滑动窗口功能:确认、差错控制、流量控制。
流量控制
TCP的特点之一是提供体积可变的滑动窗口机制,支持端到端的流量控制。TCP的窗口以字节为单位进行调整,以适应接收方的处理能力。处理过程如下: 减小窗口尺寸
(1)TCP连接阶段,双方协商窗口尺寸,同时接收方预留数据缓存区; (2)发送方根据协商的结果,发送符合窗口尺寸的数据字节流,并等待对方的确认; (3)发送方根据确认信息,改变窗口的尺寸,增加或者减少发送未得到确认的字节流中的字节数。调整过程包括:如果出现发送拥塞,发送窗口缩小为原来的一半,同时将超时重传的时间间隔扩大一倍。 滑动窗口机制为端到端设备间的数据传输提供了可靠的流量控制机制。然而,它只能在源端设备和目的端设备起作用,当网络中间设备(例如路由器等)发生拥塞时,滑动窗口机制将不起作用。
4:多线程如何同步:
在这里简单说一下linux多线程同步的方法吧(win上有一定的差别,也有一定的累似)
1:线程数据,每个线程数据创建一个键,它和这个键相关联,在各个线程里,都使用这个键来指代线程数据,但在不同的线程里,这个键代表的数据是不同的,在同一个线程里,它代表同样的数据内容。以此来达到线程安全的目的。
2:互斥锁,就是在各个线程要使用的一些公共数据之前加锁,使用之后释放锁,这个是非常常用的线程安全控制的方法,而频繁的加解锁也对效率有一定的影响。
3:条件变量,而条件变量通过允许线程阻塞和等待另一个线程发送信号的方法弥补了互斥锁的不足,它常和互斥锁一起使用。使用时,条件变量被用来阻塞一个线程,当条件不满足时,线程往往解开相应的互斥锁并等待条件发生变化。一旦其它的某个线程改变了条件变量,它将通知相应的条件变量唤醒一个或多个正被此条件变量阻塞的线程。这些线程将重新锁定互斥锁并重新测试条件是否满足。一般说来,条件变量被用来进行线程间的同步。
4:信号量,信号量本质上是一个非负的整数计数器,它被用来控制对公共资源的访问。当公共资源增加时,调用函数sem_post()增加信号量。只有当信号量值大于0时,才能使用公共资源,使用后,函数sem_wait()减少信号量。函数sem_trywait()和函数pthread_ mutex_trylock()起同样的作用,它是函数sem_wait()的非阻塞版本
另外pthread_join也可以等待一个线程的终止。可能还有一些其他我暂时没有想到的方法,欢迎补充
5:进程间通讯的方式有哪些,各有什么优缺点
进程间通信主要包括管道, 系统IPC(包括消息队列,信号量,共享存储), socket.
管道包括三种:1)普通管道PIPE, 通常有种限制,一是半双工,只能单向传输;二是只能在父子进程间使用. 2)流管道s_pipe: 去除了第一种限制,可以双向传输. 3)命名管道:name_pipe, 去除了第二种限制,可以在许多并不相关的进程之间进行通讯.
系统IPC的三种方式类同,都是使用了内核里的标识符来识别
管道: 优点是所有的UNIX实现都支持, 并且在最后一个访问管道的进程终止后,管道就被完全删除;缺陷是管道只允许单向传输或者用于父子进程之间
系统IPC: 优点是功能强大,能在毫不相关进程之间进行通讯; 缺陷是关键字KEY_T使用了内核标识,占用了内核资源,而且只能被显式删除,而且不能使用SOCKET的一些机制,例如select,epoll等.
socket可以跨网络通讯,其他进程间通讯的方式都不可以,只能是本机进程通讯。
6:tcp连接建立的时候3次握手的具体过程,以及其中的每一步是为什么
建立连接采用的3次握手协议,具体是指:
第一次握手是客户端connect连接到server,server accept client的请求之后,向client端发送一个消息,相当于说我都准备好了,你连接上我了,这是第二次握手,第3次握手就是client向server发送的,就是对第二次握手消息的确认。之后client和server就开始通讯了。
7:tcp断开连接的具体过程,其中每一步是为什么那么做
断开连接的4次握手,具体如下:
断开连接的一端发送close请求是第一次握手,另外一端接收到断开连接的请求之后需要对close进行确认,发送一个消息,这是第二次握手,发送了确认消息之后还要向对端发送close消息,要关闭对对端的连接,这是第3次握手,而在最初发送断开连接的一端接收到消息之后,进入到一个很重要的状态time_wait状态,这个状态也是面试官经常问道的问题,最后一次握手是最初发送断开连接的一端接收到消息之后。对消息的确认。
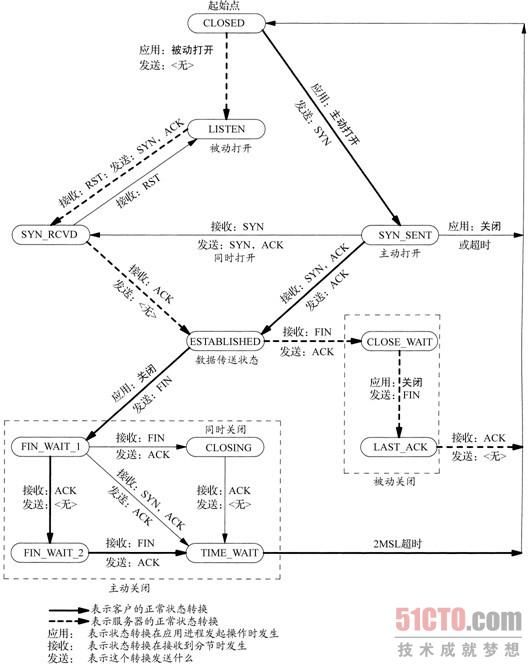
8:tcp建立连接和断开连接的各种过程中的状态转换细节
2.6 TCP连接的建立和终止
为帮助大家理解connect、accept和close这3个函数并使用netstat程序调试TCP应用,我们必须了解TCP连接如何建立和终止,并掌握TCP的状态转换图。
2.6.1 三路握手
建立一个TCP连接时会发生下述情形。
(1) 服务器必须准备好接受外来的连接。这通常通过调用socket、bind和listen这3个函数来完成,我们称之为被动打开(passive open)。
(2) 客户通过调用connect发起主动打开(active open)。这导致客户TCP发送一个SYN(同步)分节,它告诉服务器客户将在(待建立的)连接中发送的数据的初始序列号。通常SYN分节不携带数据,其所在IP数据报只含有一个IP首部、一个TCP首部及可能有的TCP选项(我们稍后讲解)。
(3) 服务器必须确认(ACK)客户的SYN,同时自己也得发送一个SYN分节,它含有服务器将在同一连接中发送的数据的初始序列号。服务器在单个分节中发送SYN和对客户SYN的ACK(确认)。
(4) 客户必须确认服务器的SYN。
这种交换至少需要3个分组,因此称之为TCP的三路握手(three-way handshake)。图2-2展示了所交换的3个分节。

图2-2给出的客户的初始序列号为J,服务器的初始序列号为K。ACK中的确认号是发送这个ACK的一端所期待的下一个序列号。因为SYN占据一个字节的序列号空间,所以每一个SYN的ACK中的确认号就是该SYN的初始序列号加1。类似地,每一个FIN(表示结束)的ACK中的确认号为该FIN的序列号加1。
建立TCP连接就好比一个电话系统[Nemeth 1997]。socket函数等同于有电话可用。bind函数是在告诉别人你的电话号码,这样他们可以呼叫你。listen函数是打开电话振铃,这样当有一个外来呼叫到达时,你就可以听到。connect函数要求我们知道对方的电话号码并拨打它。accept函数发生在被呼叫的人应答电话之时。由accept返回客户的标识(即客户的IP地址和端口号)类似于让电话机的呼叫者ID功能部件显示呼叫者的电话号码。然而两者的不同之处在于accept只在连接建立之后返回客户的标识,而呼叫者ID功能部件却在我们选择应答或不应答电话之前显示呼叫者的电话号码。如果使用域名系统DNS(见第11章),它就提供了一种类似于电话簿的服务。getaddrinfo类似于在电话簿中查找某个人的电话号码,getnameinfo则类似于有一本按照电话号码而不是按照用户名排序的电话簿。
2.6.2 TCP选项
每一个SYN可以含有多个TCP选项。下面是常用的TCP选项。
MSS选项。发送SYN的TCP一端使用本选项通告对端它的最大分节大小(maximum segment size)即MSS,也就是它在本连接的每个TCP分节中愿意接受的最大数据量。发送端TCP使用接收端的MSS值作为所发送分节的最大大小。我们将在7.9节看到如何使用TCP_MAXSEG套接字选项提取和设置这个TCP选项。
窗口规模选项。TCP连接任何一端能够通告对端的最大窗口大小是65535,因为在TCP首部中相应的字段占16位。然而当今因特网上业已普及的高速网络连接(45 Mbit/s或更快,如RFC 1323[Jacobson, Braden, and Borman 1992]所述)或长延迟路径(卫星链路)要求有更大的窗口以获得尽可能大的吞吐量。这个新选项指定TCP首部中的通告窗口必须扩大(即左移)的位数(0~14),因此所提供的最大窗口接近1 GB(65535×214)。在一个TCP连接上使用窗口规模的前提是它的两个端系统必须都支持这个选项。我们将在7.5节看到如何使用SO_RCVBUF套接字选项影响这个TCP选项。
为提供与不支持这个选项的较早实现间的互操作性,需应用如下规则。TCP可以作为主动打开的部分内容随它的SYN发送该选项,但是只在对端也随它的SYN发送该选项的前提下,它才能扩大自己窗口的规模。类似地,服务器的TCP只有接收到随客户的SYN到达的该选项时,才能发送该选项。本逻辑假定实现忽略它们不理解的选项,如此忽略是必需的要求,也已普遍满足,但无法保证所有实现都满足此要求。
时间戳选项。这个选项对于高速网络连接是必要的,它可以防止由失而复现的分组 可能造成的数据损坏。它是一个较新的选项,也以类似于窗口规模选项的方式协商处理。作为网络编程人员,我们无需考虑这个选项。
TCP的大多数实现都支持这些常用选项。后两个选项有时称为"RFC 1323选项",因为它们是在RFC 1323[Jacobson, Braden, and Borman 1992]中说明的。既然高带宽或长延迟的网络被称为"长胖管道"(long fat pipe),这两个选项也称为"长胖管道选项"。TCPv1的第24章对这些选项有详细的叙述。
2.6.3 TCP连接终止
TCP建立一个连接需3个分节,终止一个连接则需4个分节。
(1) 某个应用进程首先调用close,我们称该端执行主动关闭(active close)。该端的TCP于是发送一个FIN分节,表示数据发送完毕。
(2) 接收到这个FIN的对端执行被动关闭(passive close)。这个FIN由TCP确认。它的接收也作为一个文件结束符(end-of-file)传递给接收端应用进程(放在已排队等候该应用进程接收的任何其他数据之后),因为FIN的接收意味着接收端应用进程在相应连接上再无额外数据可接收。
(3) 一段时间后,接收到这个文件结束符的应用进程将调用close关闭它的套接字。这导致它的TCP也发送一个FIN。
(4) 接收这个最终FIN的原发送端TCP(即执行主动关闭的那一端)确认这个FIN。
既然每个方向都需要一个FIN和一个ACK,因此通常需要4个分节。我们使用限定词"通常"是因为:某些情形下步骤1的FIN随数据一起发送;另外,步骤2和步骤3发送的分节都出自执行被动关闭那一端,有可能被合并成一个分节。图2-3展示了这些分组。
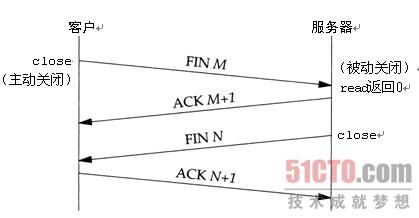
类似SYN,一个FIN也占据1个字节的序列号空间。因此,每个FIN的ACK确认号就是这个FIN的序列号加1。
在步骤2与步骤3之间,从执行被动关闭一端到执行主动关闭一端流动数据是可能的。这称为半关闭(half-close),我们将在6.6节随shutdown函数再详细介绍。
当套接字被关闭时,其所在端TCP各自发送了一个FIN。我们在图中指出,这是由应用进程调用close而发生的,不过需认识到,当一个Unix进程无论自愿地(调用exit或从main函数返回)还是非自愿地(收到一个终止本进程的信号)终止时,所有打开的描述符都被关闭,这也导致仍然打开的任何TCP连接上也发出一个FIN。
图2-3展示了客户执行主动关闭的情形,不过我们指出,无论是客户还是服务器,任何一端都可以执行主动关闭。通常情况是客户执行主动关闭,但是某些协议(譬如值得注意的HTTP/1.0)却由服务器执行主动关闭。
2.6.4 TCP状态转换图
TCP涉及连接建立和连接终止的操作可以用状态转换图(state transition diagram)来说明,如图2-4所示。
TCP为一个连接定义了11种状态,并且TCP规则规定如何基于当前状态及在该状态下所接收的分节从一个状态转换到另一个状态。举例来说,当某个应用进程在CLOSED状态下执行主动打开时,TCP将发送一个SYN,且新的状态是SYN_SENT。如果这个TCP接着接收到一个带ACK的SYN,它将发送一个ACK,且新的状态是ESTABLISHED。这个最终状态是绝大多数数据传送发生的状态。
自ESTABLISHED状态引出的两个箭头处理连接的终止。如果某个应用进程在接收到一个FIN之前调用close(主动关闭),那就转换到FIN_WAIT_1状态。但如果某个应用进程在ESTABLISHED状态期间接收到一个FIN(被动关闭),那就转换到CLOSE_WAIT状态。
我们用粗实线表示通常的客户状态转换,用粗虚线表示通常的服务器状态转换。图中还注明存在两个我们未曾讨论的转换:一个为同时打开(simultaneous open),发生在两端几乎同时发送SYN并且这两个SYN在网络中交错的情形下,另一个为同时关闭(simultaneous close),发生在两端几乎同时发送FIN的情形下。TCPv1的第18章中有这两种情况的例子和讨论,它们是可能发生的,不过非常罕见。
展示状态转换图的原因之一是给出11种TCP状态的名称。这些状态可使用netstat显示,它是一个在调试客户/服务器应用时很有用的工具。我们将在第5章中使用netstat去监视状态的变化。
2.6.5 观察分组
图2-5展示一个完整的TCP连接所发生的实际分组交换情况,包括连接建立、数据传送和连接终止3个阶段。图中还展示了每个端点所历经的TCP状态。
本例中的客户通告一个值为536的MSS(表明该客户只实现了最小重组缓冲区大小),服务器通告一个值为1460的MSS(以太网上IPv4的典型值)。不同方向上MSS值不相同不成问题(见习题2.5)。

一旦建立一个连接,客户就构造一个请求并发送给服务器。这里我们假设该请求适合于单个TCP分节(即请求大小小于服务器通告的值为1460字节的MSS)。服务器处理该请求并发送一个应答,我们假设该应答也适合于单个分节(本例即小于536字节)。图中使用粗箭头表示这两个数据分节。注意,服务器对客户请求的确认是伴随其应答发送的。这种做法称为捎带(piggybacking),它通常在服务器处理请求并产生应答的时间少于200 ms时发生。如果服务器耗用更长时间,譬如说1 s,那么我们将看到先是确认后是应答。(TCP数据流机理在TCPv1的第19章和第20章中详细叙述。)
图中随后展示的是终止连接的4个分节。注意,执行主动关闭的那一端(本例子中为客户)进入我们将在下一节中讨论的TIME_WAIT状态。
图2-5中值得注意的是,如果该连接的整个目的仅仅是发送一个单分节的请求和接收一个单分节的应答,那么使用TCP有8个分节的开销。如果改用UDP,那么只需交换两个分组:一个承载请求,一个承载应答。然而从TCP切换到UDP将丧失TCP提供给应用进程的全部可靠性,迫使可靠服务的一大堆细节从传输层(TCP)转移到UDP应用进程。TCP提供的另一个重要特性即拥塞控制也必须由UDP应用进程来处理。尽管如此,我们仍然需要知道许多网络应用是使用UDP构建的,因为它们需要交换的数据量较少,而UDP避免了TCP连接建立和终止所需的开销。
2.7 TIME_WAIT状态
毫无疑问,TCP中有关网络编程最不容易理解的是它的TIME_WAIT状态。在图2-4中我们看到执行主动关闭的那端经历了这个状态。该端点停留在这个状态的持续时间是最长分节生命期(maximum segment lifetime,MSL)的两倍,有时候称之为2MSL。
任何TCP实现都必须为MSL选择一个值。RFC 1122[Braden 1989]的建议值是2分钟,不过源自Berkeley的实现传统上改用30秒这个值。这意味着TIME_WAIT状态的持续时间在1分钟到4分钟之间。MSL是任何IP数据报能够在因特网中存活的最长时间。我们知道这个时间是有限的,因为每个数据报含有一个称为跳限(hop limit)的8位字段(见图A-1中IPv4的TTL字段和图A-2中IPv6的跳限字段),它的最大值为255。尽管这是一个跳数限制而不是真正的时间限制,我们仍然假设:具有最大跳限(255)的分组在网络中存在的时间不可能超过MSL秒。
分组在网络中"迷途"通常是路由异常的结果。某个路由器崩溃或某两个路由器之间的某个链路断开时,路由协议需花数秒钟到数分钟的时间才能稳定并找出另一条通路。在这段时间内有可能发生路由循环(路由器A把分组发送给路由器B,而B再把它们发送回A),我们关心的分组可能就此陷入这样的循环。假设迷途的分组是一个TCP分节,在它迷途期间,发送端TCP超时并重传该分组,而重传的分组却通过某条候选路径到达最终目的地。然而不久后(自迷途的分组开始其旅程起最多MSL秒以内)路由循环修复,早先迷失在这个循环中的分组最终也被送到目的地。这个原来的分组称为迷途的重复分组(lost duplicate)或漫游的重复分组(wandering duplicate)。TCP必须正确处理这些重复的分组。
TIME_WAIT状态有两个存在的理由:
(1) 可靠地实现TCP全双工连接的终止;
(2) 允许老的重复分节在网络中消逝。
第一个理由可以通过查看图2-5并假设最终的ACK丢失了来解释。服务器将重新发送它的最终那个FIN,因此客户必须维护状态信息,以允许它重新发送最终那个ACK。要是客户不维护状态信息,它将响应以一个RST(另外一种类型的TCP分节),该分节将被服务器解释成一个错误。如果TCP打算执行所有必要的工作以彻底终止某个连接上两个方向的数据流(即全双工关闭),那么它必须正确处理连接终止序列4个分节中任何一个分节丢失的情况。本例子也说明了为什么执行主动关闭的那一端是处于TIME_WAIT状态的那一端:因为可能不得不重传最终那个ACK的就是那一端。
为理解存在TIME_WAIT状态的第二个理由,我们假设在12.106.32.254的1500端口和206.168.112.219的21端口之间有一个TCP连接。我们关闭这个连接,过一段时间后在相同的IP地址和端口之间建立另一个连接。后一个连接称为前一个连接的化身(incarnation),因为它们的IP地址和端口号都相同。TCP必须防止来自某个连接的老的重复分组在该连接已终止后再现,从而被误解成属于同一连接的某个新的化身。为做到这一点,TCP将不给处于TIME_WAIT状态的连接发起新的化身。既然TIME_WAIT状态的持续时间是MSL的2倍,这就足以让某个方向上的分组最多存活MSL秒即被丢弃,另一个方向上的应答最多存活MSL秒也被丢弃。通过实施这个规则,我们就能保证每成功建立一个TCP连接时,来自该连接先前化身的老的重复分组都已在网络中消逝了。
这个规则存在一个例外:如果到达的SYN的序列号大于前一化身的结束序列号,源自Berkeley的实现将给当前处于TIME_WAIT状态的连接启动新的化身。TCPv2第958~959页对这种情况有详细的叙述。它要求服务器执行主动关闭,因为接收下一个SYN的那一端必须处于TIME_WAIT状态。rsh命令具备这种能力。RFC 1185[Jacobson, Braden, and Zhang 1990]讲述了有关这种情形的一些陷阱。
9:epool与select的区别
select在一个进程中打开的最大fd是有限制的,由FD_SETSIZE设置,默认值是2048。不过 epoll则没有这个限制,它所支持的fd上限是最大可以打开文件的数目,这个数字一般远大于2048,一般来说内存越大,fd上限越大,1G内存都能达到大约10w左右。
select的轮询机制是系统会去查找每个fd是否数据已准备好,当fd很多的时候,效率当然就直线下降了,epoll采用基于事件的通知方式,一旦某个fd数据就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,而不需要不断的去轮询查找就绪的描述符,这就是epool高效最本质的原因。
无论是select还是epoll都需要内核把FD消息通知给用户空间,如何避免不必要的内存拷贝就很重要,在这点上,epoll是通过内核于用户空间mmap同一块内存实现的,而select则做了不必要的拷贝
10:epool中et和lt的区别与实现原理
LT:水平触发,效率会低于ET触发,尤其在大并发,大流量的情况下。但是LT对代码编写要求比较低,不容易出现问题。LT模式服务编写上的表现是:只要有数据没有被获取,内核就不断通知你,因此不用担心事件丢失的情况。
ET:边缘触发,效率非常高,在并发,大流量的情况下,会比LT少很多epoll的系统调用,因此效率高。但是对编程要求高,需要细致的处理每个请求,否则容易发生丢失事件的情况。
另一点区别就是设为ET模式的文件句柄必须是非阻塞的
附一个例子:
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#include
#define MAXBUF 1024
#define MAXEPOLLSIZE 10000
/*
setnonblocking - 设置句柄为非阻塞方式
*/
int
setnonblocking(
int
sockfd)
{
if
(fcntl(sockfd, F_SETFL, fcntl(sockfd, F_GETFD, 0)|O_NONBLOCK) == -1)
{
return
-1;
}
return
0;
}
/*
handle_message - 处理每个 socket 上的消息收发
*/
int
handle_message(
int
new_fd)
{
char
buf[MAXBUF + 1];
int
len;
/* 开始处理每个新连接上的数据收发 */
bzero(buf, MAXBUF + 1);
/* 接收客户端的消息 */
len = recv(new_fd, buf, MAXBUF, 0);
if
(len > 0)
{
printf
(
"%d接收消息成功:'%s',共%d个字节的数据\n"
,
new_fd, buf, len);
}
else
{
if
(len < 0)
printf
(
"消息接收失败!错误代码是%d,错误信息是'%s'\n"
,
errno
,
strerror
(
errno
));
close(new_fd);
return
-1;
}
/* 处理每个新连接上的数据收发结束 */
return
len;
}
int
main(
int
argc,
char
**argv)
{
int
listener, new_fd, kdpfd, nfds, n, ret, curfds;
socklen_t len;
struct
sockaddr_in my_addr, their_addr;
unsigned
int
myport, lisnum;
struct
epoll_event ev;
struct
epoll_event events[MAXEPOLLSIZE];
struct
rlimit rt;
myport = 5000;
lisnum = 2;
/* 设置每个进程允许打开的最大文件数 */
rt.rlim_max = rt.rlim_cur = MAXEPOLLSIZE;
if
(setrlimit(RLIMIT_NOFILE, &rt) == -1)
{
perror
(
"setrlimit"
);
exit
(1);
}
else
{
printf
(
"设置系统资源参数成功!\n"
);
}
/* 开启 socket 监听 */
if
((listener = socket(PF_INET, SOCK_STREAM, 0)) == -1)
{
perror
(
"socket"
);
exit
(1);
}
else
{
printf
(
"socket 创建成功!\n"
);
}
setnonblocking(listener);
bzero(&my_addr,
sizeof
(my_addr));
my_addr.sin_family = PF_INET;
my_addr.sin_port = htons(myport);
my_addr.sin_addr.s_addr = INADDR_ANY;
if
(bind(listener, (
struct
sockaddr *) &my_addr,
sizeof
(
struct
sockaddr)) == -1)
{
perror
(
"bind"
);
exit
(1);
}
else
{
printf
(
"IP 地址和端口绑定成功\n"
);
}
if
(listen(listener, lisnum) == -1)
{
perror
(
"listen"
);
exit
(1);
}
else
{
printf
(
"开启服务成功!\n"
);
}
/* 创建 epoll 句柄,把监听 socket 加入到 epoll 集合里 */
kdpfd = epoll_create(MAXEPOLLSIZE);
len =
sizeof
(
struct
sockaddr_in);
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = listener;
if
(epoll_ctl(kdpfd, EPOLL_CTL_ADD, listener, &ev) < 0)
{
fprintf
(stderr,
"epoll set insertion error: fd=%d\n"
, listener);
return
-1;
}
else
{
printf
(
"监听 socket 加入 epoll 成功!\n"
);
}
curfds = 1;
while
(1)
{
/* 等待有事件发生 */
nfds = epoll_wait(kdpfd, events, curfds, -1);
if
(nfds == -1)
{
perror
(
"epoll_wait"
);
break
;
}
/* 处理所有事件 */
for
(n = 0; n < nfds; ++n)
{
if
(events[n].data.fd == listener)
{
new_fd = accept(listener, (
struct
sockaddr *) &their_addr,&len);
if
(new_fd < 0)
{
perror
(
"accept"
);
continue
;
}
else
{
printf
(
"有连接来自于: %d:%d, 分配的 socket 为:%d\n"
,
inet_ntoa(their_addr.sin_addr), ntohs(their_addr.sin_port), new_fd);
}
setnonblocking(new_fd);
ev.events = EPOLLIN | EPOLLET;
ev.data.fd = new_fd;
if
(epoll_ctl(kdpfd, EPOLL_CTL_ADD, new_fd, &ev) < 0)
{
fprintf
(stderr,
"把 socket '%d' 加入 epoll 失败!%s\n"
,
new_fd,
strerror
(
errno
));
return
-1;
}
curfds++;
}
else
{
ret = handle_message(events[n].data.fd);
if
(ret < 1 &&
errno
!= 11)
{
epoll_ctl(kdpfd, EPOLL_CTL_DEL, events[n].data.fd,&ev);
curfds--;
}
}
}
}
close(listener);
return
0;
}
|
11:写一个server程序需要注意哪些问题
1)搜索网络模型;
2)事件模型也可以;
3)完成端口模型;
4)用select或异步select实现都可以;
简单的话多线程就可以解决,即每accept一个客户端就创建一个线程,另外winsock 有5种I/O模型,Select、异步事件、事件选择、重叠IO、完成端口,都可以实现一定数量的并发连接,建议你百度一下,都有现成的代码实例,就几个API调用,蛮简单的,你看一下就会明白!
TCP窗口和拥塞控制实现机制
TCP数据包格式
| Source Port |
Destination port |
||
| Sequence Number |
|||
| Acknowledgement Number |
|||
| Length |
Reserved |
Control Flags |
Window Size |
| Check sum |
Urgent Pointer |
||
| Options |
|||
| DATA |
|||
注:校验和是对所有数据包进行计算的。
TCP包的处理流程
接收:
ip_local_deliver
↓
tcp_v4_rcv() (tcp_ipv4.c)→_tcp_v4_lookup()
↓
tcp_v4_do_rcv(tcp_ipv4.c)→tcp_rcv_state_process (OTHER STATES)
↓Established
tcp_rcv_established(tcp_in→tcp_ack_snd_check,(tcp_data_snd_check,tcp_ack (tcp_input.c)
↓ ↓ ↓ ↓
tcp_data tcp_send_ack tcp_write_xmit
↓ (slow) ↓(Fast) ↓
tcp_data_queue tcp_transmit_skb
↓ ↓ ↓
sk->data_ready (应用层) ip_queque_xmit
发送:
send
↓
tcp_sendmsg
↓
__tcp_push_pending_frames tcp_write_timer
↓ ↓
tcp_ retransmit_skb
↓
tcp_transmit_skb
↓
ip_queue_xmit
TCP段的接收
_tcp_v4_lookup()用于在活动套接字的散列表中搜索套接字或SOCK结构体。
tcp_ack (tcp_input.c)用于处理确认包或具有有效ACK号的数据包的接受所涉及的所有任务:
调整接受窗口(tcp_ack_update_window())
删除重新传输队列中已确认的数据包(tcp_clean_rtx_queue())
对零窗口探测确认进行检查
调整拥塞窗口(tcp_may_raise_cwnd())
重新传输数据包并更新重新传输计时器
tcp_event_data_recv()用于处理载荷接受所需的所有管理工作,包括最大段大小的更新,时间戳的更新,延迟计时器的更新。
tcp_data_snd_check(sk)检查数据是否准备完毕并在传输队列中等待,且它会启动传输过程(如果滑动窗口机制的传输窗口和拥塞控制窗口允许的话),实际传输过程由tcp_write_xmit()启动的。(这里进行流量控制和拥塞控制)
tcp_ack_snd_check()用于检查可以发送确认的各种情形,同样它会检查确认的类型(它应该是快速的还是应该被延迟的)。
tcp_fast_parse_options(sk,th,tp)用于处理TCP数据包报头中的Timestamp选项。
tcp_rcv_state_process()用于在TCP连接不处在ESTABLISHED状态的时候处理输入段。它主要用于处理该连接的状态变换和管理工作。
Tcp_sequence()通过使用序列号来检查所到达的数据包是否是无序的。如果它是一个无序的数据包,测激活QuickAck模式,以尽可能快地将确认发送出去。
Tcp_reset()用来重置连接,且会释放套接字缓冲区。
TCP段的发送
tcp_sendmsg()(TCP.C)用于将用户地址空间中的载荷拷贝至内核中并开始以TCP段形式发送数据。在发送启动前,它会检查连接是否已经建立及它是否处于TCP_ESTABLISHED状态,如果还没有建立连接,那么系统调用会在wait_for_tcp_connect()一直等待直至有一个连接存在。
tcp_select_window() 用来进行窗口的选择计算,以此进行流量控制。
tcp_send_skb()(tcp_output.c)用来将套接字缓冲区SKB添加到套接字传输队列(sk->write_queue)并决定传输是否可以启动或者它必须在队列中等待。它通过tcp_snd_test()例程来作出决定。如果结果是负的,那么套接字缓冲区就仍留在传输队列中; 如果传输成功的话,自动传输的计时器会在tcp_reset_xmit_timer()中自动启动,如果某一特定时间后无该数据包的确认到达,那么计时器就会启动。(尚未找到调用之处)(只有在发送FIN包时才会调用此函数,其它情况下都不会调用此函数2007,06,15)
tcp_snd_test()(tcp.h) 它用于检查TCP段SKB是否可以在调用时发送。
tcp_write_xmit()(tcp_output.c)它调用tcp_transmit_skb()函数来进行包的发送,它首先要查看此时TCP是否处于CLOSE状态,如果不是此状态则可以发送包.进入循环,从SKB_BUF中取包,测试是否可以发送包(),接下来查看是否要分片,分片完后调用tcp_transmit_skb()函数进行包的发送,直到发生拥塞则跳出循环,然后更新拥塞窗口.
tcp_transmits_skb()(TCP_OUTPUT.C)负责完备套接字缓冲区SKB中的TCP段以及随后通过Internet协议将其发送。并且会在此函数中添加TCP报头,最后调用tp->af_specific->queue_xmit)发送TCP包.
tcp_push_pending_frames()用于检查是否存在传输准备完毕而在常规传输尝试期间无法发送的段。如果是这样的情况,则由tcp_write_xmit()启动这些段的传输过程。
TCP实例的数据结构
Struct tcp_opt sock.h
包含了用于TCP连接的TCP算法的所有变量。主要由以下部分算法或协议机制的变量组成:
序列和确认号
流控制信息
数据包往返时间
计时器
数据包头中的TCP选项
自动和选择性数据包重传
TCP状态机
tcp_rcv_state_process()主要处理状态转变和连接的管理工作,接到数据报的时候不同状态会有不同的动作。
tcp_urg()负责对紧急数据进行处理
建立连接
tcp_v4_init_sock()(tcp_ipv4.c)用于运行各种初始化动作:初始化队列和计时器,初始化慢速启动和最大段大小的变量,设定恰当的状态以及设定特定于PF_INET的例程的指针。
tcp_setsockopt()(tcp.c)该函数用于设定TCP协议的服务用户所选定的选项:TCP_MAXSEG,TCP_NODELAY, TCP_CORK, TCP_KEEPIDLE, TCP_KEEPINTVL, TCP_KEEPCNT, TCP_SYNCNT, TCP_LINGER2, TCP_DEFER_ACCEPT和TCP_WINDOW_CLAMP.
tcp_connect()(tcp_output.c)该函数用于初始化输出连接:它为sk_buff结构体中的数据单元报头预留存储空间,初始化滑动窗口变量,设定最大段长度,设定TCP报头,设定合适的TCP状态,为重新初始化计时器和控制变量,最后,将一份初始化段的拷贝传递给tcp_transmit_skb()例程,以便进行连接建立段的重新传输发送并设定计时器。
从发送方和接收方角度看字节序列域
如下图示:
|
snd_una |
|
snd_nxt |
|
snd_una+snd+wnd |
|
rcv_wup |
|
rcv_nxt |
|
rcv_wup+rcv_wnd |
|
数据以经确认 |
|
数据尚未确认 |
|
剩余传输窗口 |
|
右窗口边界 |
|
数据以经确认 |
|
数据尚未确认 |
|
剩余传输窗口 |
流控制
流控制用于预防接受方TCP实例的接受缓冲区溢出。为了实现流控制,TCP协议使用了滑动窗口机制。该机制以由接受方所进行的显式传输资信分配为基础。
滑动窗口机制提供的三项重要作业:
分段并发送于若干数据包中的数据集初始顺序可以在接收方恢复。
可以通过数据包的排序来识别丢失的或重复的数据包。
两个TCP实例之间的数据流可以通过传输资信赋值来加以控制。
Tcp_select_window()
当发送一个TCP段用以指定传输资信大小的时候就会在tcp_transmit_skb()方法中调用tcp_select_window()。当前通告窗口的大小最初是由tcp_receive_window()指定的。随后通过tcp_select_window()函数来查看该计算机中还有多少可用缓冲空间。这就够成了哪个提供给伙伴实例的新传输资信的决定基础。
一旦已经计算出新的通告窗口,就会将该资信(窗口信息)存储在该连接的tcp_opt结构体(tp->rcv_wnd)中。同样,tp->rcv_wup也会得到调整;它会在计算和发送新的资信的时候存储tp->rcv_nxt变量的当前值,这也就是通常所说的窗口更新。这是因为,在通告窗口已发送之后到达的每一个数据包都必须冲销其被授予的资信(窗口信息)。
另外,该方法中还使用另一种TCP算法,即通常所说的窗口缩放算法。为了能够使得传输和接收窗口的16位数字运作起来有意义,就必须引入该算法。基于这个原因,我们引入了一个缩放因子:它指定了用以将窗口大小移至左边的比特数目,利用值Fin tp->rcv_wscale, 这就相当于因子为2F 的通告窗口增加。
Tcp_receive_window()(tcp.c)用于计算在最后一段中所授予的传输资信还有多少剩余,并将自那时起接收到的数据数量考虑进去。
Tcp_select_window()(tcp_output.c)用于检查该连接有多少存储空间可以用于接收缓冲区以及可以为接收窗口选择多大的尺寸。
Tcp_space()确定可用缓冲区存储空间有多大。在所确定的缓冲区空间进行一些调整后,它最后检查是否有足够的缓冲区空间用于最大尺寸的TCP段。如果不是这样,则意味着已经出现了痴呆窗口综合症(SWS)。为了避免SWS的出现,在这种情形下所授予的资信就不会小于协议最大段。
如果可用缓冲区空间大于最大段大小,则继续计算新的接收窗口。该窗口变量被设定为最后授予的那个资信的值(tcp->rcv_wnd)。如果旧的资信大于或小于多个段大小的数量,则窗口被设定为空闲缓冲区空间最大段大小的下一个更小的倍数。以这种方式计算的窗口值是作为新接收资信的参考而返回的。
Tcp_probe_timer()(tcp_timer.c)是零窗口探测计时器的处理例程。它首先检查同位体在一段较长期间上是否曾提供了一个有意义的传输窗口。如果有若干个窗口探测发送失败,则输出一个错误消息以宣布该TCP连接中存在严重并通过tcp_done()关闭该连接。主要是用来对方通告窗口为0,则每隔定时间探测通告窗口是否有效.
如果还未达到该最大窗口探测数目,则由tcp_send_probe0()发送一个没有载荷的TCP段,且确认段此后将授予一个大于NULL的资信。
Tcp_send_probe0()(tcp_output.c)利用tcp_write_wakeup(sk)来生成并发送零窗口探测数据包。如果不在需要探测计时器,或者当前仍旧存在途中数据包且它们的ACK不含有新的资信,那么它就不会得到重新启动,且probes_out和backoff 参数会得到重置。
否则,在已经发送一个探测数据包后这些参数会被增量,且零窗口探测计时器会得到重新启动,这样它在某一时间后会再次到期。
Tcp_write_wakeup()(tcp_output.c)用于检查传输窗口是否具有NULL大小以及SKB中数据段的开头是否仍旧位于传输窗口范围以内。到目前为止所讨论的零窗口问题的情形中,传输窗口具有NULL大小,所以tcp_xmit_probe_skb()会在else分支中得到调用。它会生成所需的零窗口探测数据包。如果满足以上条件,且如果该传输队列中至少存在一个传输窗口范围以内的数据包,则我们很可能就碰到了痴呆综合症的情况。和当前传输窗口的要求对应的数据包是由tcp_transmit_skb()生成并发送的。
Tcp_xmit_probe_skb(sk,urgent)(tcp_output.c)会创建一个没有载荷的TCP段,因为传输窗口大小NULL,且当前不得传输数据。Alloc_skb()会取得一个具有长度MAX_TCP_HEADER的套接字缓冲区。如前所述,将无载荷发送,且数据包仅仅由该数据包报头组成。
Tcp_ack_probe() (tcp_input.c) 当接收到一个ACK标记已设定的TCP段且如果怀疑它是对某一零窗口探测段的应答的时候,就会在tcp_ack()调用tcp_ack_probe()。根据该段是否开启了接受窗口,由tcp_clear_xmit_timer()停止该零窗口探测计时器或者由tcp_reset_xmit_timer()重新起用该计时器。
拥塞检测、回避和处理
流控制确保了发送到接受方TCP实例的数据数量是该实例能够容纳的,以避免数据包在接收方端系统中丢失。然而,该转发系统中可能会出现缓冲区益处——具体来说,是在Internet 协议的队列中,当它们清空的速度不够快且到达的数据多于能够通过网络适配器得到发送的数据量的时候,这种情况称为拥塞。
TCP拥塞控制是通过控制一些重要参数的改变而实现的。TCP用于拥塞控制的参数主要有:
(1) 拥塞窗口(cwnd):拥塞控制的关键参数,它描述源端在拥塞控制情况下一次最多能发送的数据包的数量。
(2) 通告窗口(awin):接收端给源端预设的发送窗口大小,它只在TCP连接建立的初始阶段发挥作用。
(3) 发送窗口(win):源端每次实际发送数据的窗口大小。
(4) 慢启动阈值(ssthresh):拥塞控制中慢启动阶段和拥塞避免阶段的分界点。初始值通常设为65535byte。
(5) 回路响应时间(RTT):一个TCP数据包从源端发送到接收端,源端收到接收端确认的时间间隔。
(6) 超时重传计数器(RTO):描述数据包从发送到失效的时间间隔,是判断数据包丢失与否及网络是否拥塞的重要参数。通常设为2RTT或5RTT。
(7) 快速重传阈值(tcprexmtthresh)::能触发快速重传的源端收到重复确认包ACK的个数。当此个数超过tcprexmtthresh时,网络就进入快速重传阶段。tcprexmtthresh缺省值为3。
四个阶段
1.慢启动阶段
旧的TCP在启动一个连接时会向网络发送许多数据包,由于一些路由器必须对数据包进行排队,因此有可能耗尽存储空间,从而导致TCP连接的吞吐量(throughput)急剧下降。避免这种情况发生的算法就是慢启动。当建立新的TCP连接时,拥塞窗口被初始化为一个数据包大小(一个数据包缺省值为536或512byte)。源端按cwnd大小发送数据,每收到一个ACK确认,cwnd就增加一个数据包发送量。显然,cwnd的增长将随RTT呈指数级(exponential)增长:1个、2个、4个、8个……。源端向网络中发送的数据量将急剧增加。
2.拥塞避免阶段
当发现超时或收到3个相同ACK确认帧时,网络即发生拥塞(这一假定是基于由传输引起的数据包损坏和丢失的概率小于1%)。此时就进入拥塞避免阶段。慢启动阈值被设置为当前cwnd的一半;超时时,cwnd被置为1。如果cwnd≤ssthresh,则TCP重新进入慢启动过程;如果cwnd>ssthresh,则TCP执行拥塞避免算法,cwnd在每次收到一个ACK时只增加1/cwnd个数据包(这里将数据包大小segsize假定为1)。
3.快速重传和恢复阶段
当数据包超时时,cwnd被设置为1,重新进入慢启动,这会导致过大地减小发送窗口尺寸,降低TCP连接的吞吐量。因此快速重传和恢复就是在源端收到3个或3个以上重复ACK时,就断定数据包已经被丢失,并重传数据包,同时将ssthresh设置为当前cwnd的一半,而不必等到RTO超时。图2和图3反映了拥塞控制窗口随时间在四个阶段的变化情况。
TCP用来检测拥塞的机制的算法:
1、 超时。
一旦某个数据包已经发送,重传计时器就会等待一个确认一段时间,如果没有确认到达,就认为某一拥塞导致了该数据包的丢失。对丢失的数据包的初始响应是慢速启动阶段,它从某个特定点起会被拥塞回避算法替代。
2、 重复确认
重复确认的接受表示某个数据段的丢失,因为,虽然随后的段到达了,但基于累积ACK段的原因它们却不能得到确认,。在这种情形下,通常认为没有出现严重的拥塞问题,因为随后的段实际上是接收到了。基于这个原因,更为新近的TCP版本对经由慢速启动阶段的丢失问题并不响应,而是对经由快速传输和快速恢复方法的丢失作出反应。
慢速启动和拥塞回避
Tcp_cong_avoid() (tcp_input.c)用于在慢速启动和拥塞回避算法中实现拥塞窗口增长。当某个具有有效确认ACK的输入TCP段在tcp_ack()中进行处理时就会调用tcp_cong_avoid()
首先,会检查该TCP连接是否仍旧处于慢速启动阶段,或者已经处于拥塞回避阶段:
在慢速启动阶段拥塞窗口会增加一个单位。但是,它不得超过上限值,这就意味着,在这一阶段,伴随每一输入确认,拥塞窗口都会增加一个单位。在实践中,这意味着可以发送的数据量每次都会加倍。
在拥塞回避阶段,只有先前已经接收到N个确认的时候拥塞窗口才会增加一个单位,其中N等于当前拥塞窗口值。要实现这一行为就需要引入补充变量tp->snd_cwnd_cnt;伴随每一输入确认,它都会增量一个单位。下一步,当达到拥塞窗口值tp->snd_cwnd的时候,tp->snd_cwnd就会最终增加一个单位,且tp->snd_cwnd_cnt得到重置。通过这一方法就能完成线形增长。
总结:拥塞窗口最初有一个指数增长,但是,一旦达到阈值,就存在线形增长了。
Tcp_enter_loss(sk,how) (tcp_input.c)是在重传计时器的处理例程中进行调用的,只有重传超时期满时所传输的数据段还未得到确认,该计时器就会启动。这里假定该数据段或它的确认已丢失。在除了无线网络的现代网络中,数据包丢失仅仅出现在拥塞情形中,且为了处理缓冲区溢出的问题将不得不在转发系统中丢弃数据包。重传定时器定时到时调用,用来计算CWND和阈值重传丢失数据,并且进入慢启动状态.
Tcp_recal_ssthresh() (tcp.h)一旦检测到了某个拥塞情形,就会在tcp_recalc_ssthresh(tp)中重新计算慢速启动阶段中指数增长的阈值。因此,一旦检测到该拥塞,当前拥塞窗口tp->snd_cwnd的大小就会被减半,并作为新的阈值被返回。该阈值不小于2。
快速重传和快速恢复
TCP协议中集成可快速重传算法以快速检测出单个数据包的丢失。先前检测数据包丢失的唯一依据是重传计时器的到期,且TCP通过减少慢速启动阶段中的传输速率来响应这一问题。新的快速重传算法使得TCP能够在重传计时器到期之前检测出数据包丢失,这也就是说,当一连串众多段中某一段丢失的时候。接收方通过发送重复确认的方法来响应有一个段丢失的输入数据段。
LINUX内核的TCP实例中两个算法的协作方式:
▉ 当接收到了三个确认复本时,变量tp->snd_ssthresh就会被设定为当前传办理窗口的一半.丢失的段会得到重传,且拥塞窗口tp->snd_cwnd会取值tp->ssthresh+3*MSS,其中MSS表示最大段大小.
▉ 每接收到一个重复确认,拥塞窗口tp->snd_cwnd 就会增加一个最大段大小的值,且会发送一个附加段(如果传输窗口大小允许的话)
▉ 当新数据的第一个确认到达时,此时tp->snd_cwnd就会取tp->snd_ssthresh的原如值,它存储在tp->prior_ssthresh中.这一确认应该对最初丢失的那个数据段进行确认.另外还应该确认所有在丢失数据包和第三个确认复本之间发送的段.
TCP中的计时器管理
Struct timer_list
{ struct timer_head list;
unsigned long expires;
unsigned long data;
void (*function) (unsighed long);
volatile int running;
}
tcp_init_xmit_timers()(tcp_timer.c)用于初始化一组不同的计时器。Timer_list会被挂钩进来,且函数指针被转换到相应的行为函数。
Tcp_clear_xmit_timer()(tcp.h)用于删除timer_list结构体链表中某个连接的所有计时器组。
Tcp_reset_xmit_timer(sk,what,when)(tcp.h)用于设定在what到时间when中指定的计时器。
TCP数据发送流程具体流程应该是这样的:
tcp_sendmsg()----->tcp_push_one()/tcp_push()----
| |
| \|/
|--------------->__tcp_push_pending_frames()
|
\|/
tcp_write_xmit()
|
\|/
tcp_transmit_skb()
tcp_sendmsg()-->__tcp_push_pending_frames() --> tcp_write_xmit()-->tcp_transmit_skb()
write_queue 是发送队列,包括已经发送的但还未确认的和还从未发送的,send_head指向其中的从未发送之第一个skb。 另外,仔细看了看tcp_sendmsg(),觉得它还是希望来一个skb 就发送一个skb,即尽快发送的策略。
有两种情况,
一,mss > tp->max_window/2,则forced_push()总为真,这样, 每来一个skb,就调用__tcp_push_pending_frames(),争取发送。
二,mss < tp->max_window/2,因此一开始forced_push()为假, 但由于一开始send_head==NULL,因此会调用tcp_push_one(), 而它也是调用__tcp_push_pending_frames(),如果此时网络情况 良好,数据会顺利发出,并很快确认,从而send_head又为NULL,这样下一次数据拷贝时,又可以顺利发出。这就是说, 在网络情况好时,tcp_sendmsg()会来一个skb就发送一个skb。
只有当网络情况出现拥塞或延迟,send_head不能及时发出, 从而不能走tcp_push_one()这条线,才会看数据的积累,此时, 每当数据积累到tp->max_window/2时,就尝试push一下。
而当拷贝数据的总量很少时,上述两种情况都可能不会满足,
这样,在循环结束时会调用一次tcp_push(),即每次用户的完整
一次发送会有一次push。
TCP包接收器(tcp_v4_rcv)将TCP包投递到目的套接字进行接收处理. 当套接字正被用户锁定, TCP包将暂时排入该套接字的后备队列(sk_add_backlog). 这时如果某一用户线程企图锁定该套接字(lock_sock), 该线程被排入套接字的后备处理等待队列(sk->lock.wq). 当用户释放上锁的套接字时(release_sock), 后备队列中的TCP包被立即注入TCP包处理器(tcp_v4_do_rcv)进行处理, 然后唤醒等待队列中最先的一个用户来获得其锁定权. 如果套接字未被上锁, 当用户正在读取该套接字时, TCP包将被排入套接字的预备队列(tcp_prequeue), 将其传递到该用户线程上下文中进行处理.
TCP定时器(TCP/IP详解2)
TCP为每条连接建立七个定时器:
1、 连接建立定时器在发送SYN报文段建立一条新连接时启动。如果没有在75秒内收到响 应,连接建立将中止。
当TCP实例将其状态从LISTEN更改为SYN_RECV的时侯就会使用这一计时器.服务端的TCP实例最初会等待一个ACK三秒钟.如果在这一段时间没有ACK到达,则认为该连接请求是过期的.
2、 重传定时器在TCP发送数据时设定.如果定时器已超时而对端的确认还未到达,TCP将重传数据.重传定时器的值(即TCP等待对端确认的时间)是动态计算的,取决于TCP为该 连接测量的往返时间和该报文段已重传几次.
3、 延迟ACK定时器在TCP收到必须被确认但无需马上发出确认的数据时设定.TCP等 待时间200MS后发送确认响应.如果,在这200MS内,有数据要在该连接上发送,延迟的ACK响应就可随着数据一起发送回对端,称为稍带确认.
4、 持续定时器在连接对端通告接收窗口为0,阻止TCP继续发送数据时设定.由于连接对端发送的窗口通告不可靠,允许TCP继续发送数据的后续窗口更新有可能丢失.因此,如果TCP有数据要发送,但对端通告接收窗口为0,则持续定时器启动,超时后向对端发送1字节的数据,判定对端接收窗口是否已打开.与重传定时器类似,持续定时器的值也是动态计算的,取决于连接的往返时间,在5秒到60秒之间取值.
5、 保活定时器在应用进程选取了插口的SO_KEEPALIVE选项时生效.如果连接的连续空闲时间超过2小时,保活定时器超时,向对端发送连接探测报文段,强迫对端响应.如果收到了期待的响应,TCP确定对端主机工作正常,在该连接再次空闲超过2小时之前,TCP不会再进行保活测试,.如果收到的是其它响应,TCP确定对端主要已重启.如果连纽若干次保活测试都未收到响应,TCP就假定对端主机已崩溃,尽管它无法区分是主机帮障还是连接故障.
6、 FIN_WAIT-2定时器,当某个连接从FIN_WAIT-1状态变迁到FIN_WAIN_2状态,并且不能再接收任何数据时,FIN_WAIT_2定时器启动,设为10分钟,定时器超时后,重新设为75秒,第二次超时后连接被关闭,加入这个定时器的目的为了避免如果对端一直不发送FIN,某个连接会永远滞留在FIN_WAIT_2状态.
7、 TIME_WAIT定时器,一般也称为2MSL定时器.2MS指两倍MSL.当连接转移到TIME_WAIT状态,即连接主动关闭时,定时器启动.连接进入TIME_WAIT状态时,定时器设定为1分钟,超时后,TCP控制块和INTERNET PCB被删除,端口号可重新使用.
TCP包含两个定时器函数:一个函数每200MS调用一次(快速定时器);另一个函数每500MS调用一次.延迟定时器与其它6个定时器有所不同;如果某个连接上设定了延迟ACK定时器,那么下一次200MS定时器超时后,延迟的ACK必须被发送.其它的定时器每500MS递减一次,计数器减为0时,就触发相应的动作.