Kerberos原理和工作机制
1.Kerberos原理和工作机制
概述:Kerberos的工作围绕着票据展开,票据类似于人的驾驶证,驾驶证标识了人的信息,以及其可以驾驶的车辆等级。
1.1 客户机初始验证
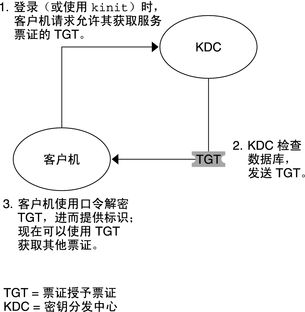
1.2获取对服务的访问

2.kerberos中的几个概念
2.1 KDC:密钥分发中心,负责管理发放票据,记录授权。
2.2 域:kerberos管理领域的标识。
2.3 principal:当每添加一个用户或服务的时候都需要向kdc添加一条principal,principl的形式为 主名称/实例名@领域名。
2.4 主名称:主名称可以是用户名或服务名,还可以是单词host,表示是用于提供各种网络服务(如ftp,rcp,rlogin)的主体。
2.5 实例名:实例名简单理解为主机名。
2.6 领域:Kerberos的域。
3.Kerberos 安装和配置
3.1 kerberos安装
KDC服务器:yum install -y krb5-server krb5-lib krb5-workstation
客户机(hadoop集群中所有服务器):yum install -y krb5-libs krb5-workstation krb5-appl-clients
(安装前应先配置yum)
3.2 kerberos配置
KDC服务器配置:
vi /etc/krb5.conf
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
default_realm = HADOOP.COM
dns_lookup_realm = false
dns_lookup_kdc = false
ticket_lifetime = 2000d
renew_lifetime = 2000d
max_life = 2000d
forwardable = true
[realms]
HADOOP.COM = {
kdc = KDC服务器主机名
admin_server = KDC服务器主机名
}
[domain_realm]
.example.com = HADOOP.COM
example.com = HADOOP.COM
vi /var/kerberos/krb5kdc/kdc.conf
[kdcdefaults]
kdc_ports = 88
kdc_tcp_ports = 88
[realms]
HADOOP.COM= {
acl_file = /var/kerberos/krb5kdc/kadm5.acl
dict_file = /usr/share/dict/words
admin_keytab = /var/kerberos/krb5kdc/kadm5.keytab
max_renewable_life=10d
supported_enctypes = aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal
}
注:supported_enctypes为java的加密方式
vi /var/kerberos/krb5kdc/kadm5.acl
/[email protected]
客户机配置:
只需要将服务器的/etc/krb5.conf分发即可
3.3 添加principal
创建KDC的principal库
root用户下直接执行此语句:kdb5_util create -r HADOOP.COM -s
创建完成时会提示键入密码,输入即可创建完成
注:创建完成后会在/var/kerberos/krb5kdc生成如下文件
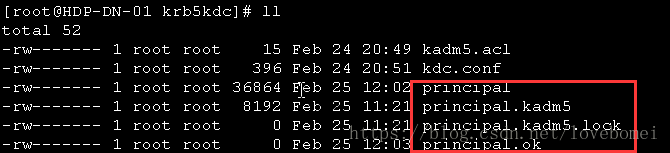
若想重新创建删除这四个文件即可
添加principal
Hadoop的kerberos认证需要添加三种principal:host,HTTP,用户(此处配置hadoop)
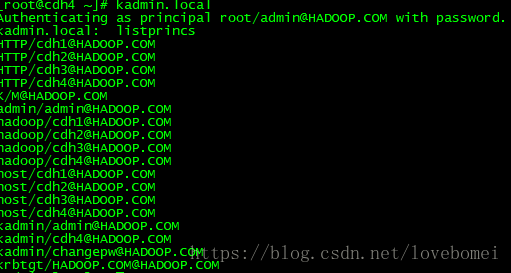
[root@hddn001 hadoop]# kadmin.local
Authenticating as principal hadoop/[email protected] with password.
kadmin.local: addprinc -randkey hadoop/[email protected]
kadmin.local: addprinc -randkey host/[email protected]
kadmin.local: addprinc -randkey HTTP/[email protected]
每台主机需添加用户,host,HTTP三种认证,如果此主机已经添加了HTTP、host认证,则仅添加用户认证即可。
其他主机自行添加,访问集群的所有机器。
使用listprincs查看一下结果
删除principle:
Kadmin.local:delprinc debugo/[email protected]
3.4创建Keytab文件
kadmin.local: ktadd -norandkey -k /root/hadoop.keytab hadoop/[email protected]
kadmin.local: ktadd -norandkey -k /root/hadoop.keytab hadoop/cdh2@@HADOOP.COM
kadmin.local: ktadd -norandkey -k /root/hadoop.keytab hadoop/cdh3@@HADOOP.COM
其他principal自行添加,执行完成之后会在指定文件/root/hadoop.keytab生成keytab信息。
使用klist查看keytab内容
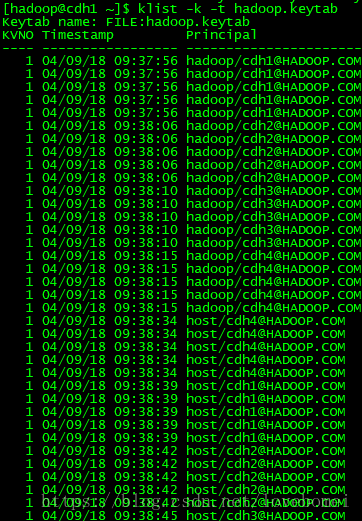
3.5分发keytab文件
分发keytab文件到其他服务器,建议保存位置保持一致方便管理。
Scp hadoop.keytab 主机名:/home/hadoop/hadoop.keytab
注:将其赋给hadoop用户 chown hadoop:hadoop hadoop.keytab
3.6 kerberos服务启动
service krb5kdc start
chkconfig krb5kdc on
service kadmin start
chkconfig kadmin on
查看日志是否启动成功:/var/log/krb5kdc.log
/var/log/kadmin.log
3.7 客户机获取票据
kinit -kt /opt/beh/data/keytab/hadoop.keytab hadoop/主机名@HADOOP.COM
获取完成后会在/tmp/目录下生成一个krb5xx的文件
可用查看票据情况klist/klist -e

至此,kerberos的搭建已经完成,可以开始hadoop集群的安装工作
4.hadoop和kerberos集成
a. zookeeper配置
Hadoop和kerberos集成需要zk同时启用kerberos认证
zookeeper 配置文件
修改zoo.cfg 文件,添加下面内容:
authProvider.1=org.apache.zookeeper.server.auth.SASLAuthenticationProvider
jaasLoginRenew=3600000创建 /conf/jaas.conf 配置文件
Server {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="path to keytab "
storeKey=true
useTicketCache=false
principal="自行修改";
};创建 /conf/java.env配置文件
export JVMFLAGS="-Djava.security.auth.login.config=“$ZOOKEEPER_HOME/conf/jaas.conf"b.hadoop配置文件
1.core-site.xml
<property>
<name>fs.defaultFSname>
<value>hdfs://cluster1value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/opt/beh/data/tmpvalue>
property>
<property>
<name>ha.zookeeper.quorumname>
<value>cdh1:2181,cdh2:2181,cdh3:2181value>
property>
<property>
<name>hadoop.security.authenticationname>
<value>kerberosvalue>
property>
<property>
<name>hadoop.security.authorizationname>
<value>truevalue>
property>
2.hdfs-site.xml
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
<property>
<name>dfs.nameservicesname>
<value>cluster1value>
property>
<property>
<name>dfs.ha.namenodes.cluster1name>
<value>cdh1,cdh2value>
property>
<property>
<name>dfs.namenode.rpc-address.cluster1.cdh1name>
<value>cdh1:9000value>
property>
<property>
<name>dfs.namenode.http-address.cluster1.cdh1name>
<value>cdh1:50070value>
property>
<property>
<name>dfs.namenode.rpc-address.cluster1.cdh2name>
<value>cdh2:9000value>
property>
<property>
<name>dfs.namenode.http-address.cluster1.cdh2name>
<value>cdh2:50070value>
property>
<property>
<name>dfs.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.namenode.shared.edits.dirname>
<value>qjournal://cdh1:8485;cdh2:8485;cdh3:8485/myclustervalue>
property>
<property>
<name>dfs.client.failover.proxy.provider.cluster1name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvidervalue>
property>
<property>
<name>dfs.journalnode.edits.dirname>
<value>/opt/beh/data/journaldata/jnvalue>
property>
<property>
<name>dfs.ha.fencing.methodsname>
<value>shell(/bin/true)value>
property>
<property>
<name>dfs.ha.fencing.ssh.private-key-filesname>
<value>/home/hadoop/.ssh/id_rsavalue>
property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeoutname>
<value>10000value>
property>
<property>
<name>dfs.namenode.handler.countname>
<value>100value>
property>
<property>
<name>dfs.block.access.token.enablename>
<value>truevalue>
property>
<property>
<name>dfs.https.enablename>
<value>HTTP_AND_HTTPSvalue>
property>
<property>
<name>dfs.http.policyname>
<value>HTTP_ONLYvalue>
property>
<property>
<name>dfs.namenode.keytab.filename>
<value>/home/hadoop/hadoop.keytabvalue>
property>
<property>
<name> dfs.namenode.kerberos.principal name>
<value>hadoop/[email protected]value>
property>
<property>
<name> dfs.namenode.kerberos.internal.spnego.principal name>
<value>HTTP/[email protected]value>
property>
<property>
<name> dfs.datanode.data.dir.perm name>
<value>700value>
property>
<property>
<name> dfs.datanode.address name>
<value>0.0.0.0:1027value>
property>
<property>
<name> dfs.datanode.http.address name>
<value>0.0.0.0:1026value>
property>
<property>
<name> dfs.datanode.https.address name>
<value>0.0.0.0:1025value>
property>
<property>
<name> dfs.datanode.keytab.file name>
<value>/home/hadoop/hadoop.keytabvalue>
property>
<property>
<name> dfs.datanode.kerberos.principal name>
<value>hadoop/[email protected]value>
property>
<property>
<name> dfs.web.authentication.kerberos.principal name>
<value>HTTP/[email protected]value>
property>
<property>
<name> dfs.web.authentication.kerberos.keytab name>
<value>/home/hadoop/hadoop.keytabvalue>
property>
<property>
<name>dfs.journalnode.keytab.filename>
<value>/home/hadoop/hadoop.keytabvalue>
property>
<property>
<name>dfs.journalnode.kerberos.principalname>
<value>hadoop/[email protected]value>
property>
<property>
<name>dfs.journalnode.kerberos.internal.spnego.principalname>
<value>HTTP/[email protected]value>
property>
<property>
<name>ignore.secure.ports.for.testingname>
<value>truevalue>
property> 3.mapred-site.xml
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.keytabname>
<value>/home/hadoop/hadoop.keytabvalue>
property>
<property>
<name>mapreduce.jobhistory.principalname>
<value>hadoop/[email protected]value>
property>
<property>
<name>mapreduce.jobhistory.http.policyname>
<value>HTTPS_ONLYvalue>
property>4.yarn-site.xml
<property>
<name>yarn.resourcemanager.connect.retry-interval.msname>
<value>2000value>
property>
<property>
<name>yarn.resourcemanager.ha.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embeddedname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.cluster-idname>
<value>yarn-rm-clustervalue>
property>
<property>
<name>yarn.resourcemanager.ha.rm-idsname>
<value>rm1,rm2value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm1name>
<value>cdh1value>
property>
<property>
<name>yarn.resourcemanager.hostname.rm2name>
<value>cdh2value>
property>
<property>
<name>yarn.resourcemanager.recovery.enabledname>
<value>truevalue>
property>
<property>
<name>yarn.resourcemanager.zk.state-store.addressname>
<value>cdh1:2181,cdh2:2181,cdh3:2181value>
property>
<property>
<name>yarn.resourcemanager.zk-addressname>
<value>cdh1:2181,cdh2:2181,cdh3:2181value>
property>
<property>
<name>yarn.resourcemanager.address.rm1name>
<value>cdh1:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1name>
<value>cdh1:8034value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1name>
<value>cdh1:8088value>
property>
<property>
<name>yarn.resourcemanager.address.rm2name>
<value>cdh2:8032value>
property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2name>
<value>cdh2:8034value>
property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2name>
<value>cdh2:8088value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
<property>
<name>yarn.resourcemanager.keytabname>
<value>/home/hadoop/hadoop.keytabvalue>
property>
<property>
<name>yarn.resourcemanager.principalname>
<value>hadoop/[email protected]value>
property>
<property>
<name>yarn.nodemanager.keytabname>
<value>/home/hadoop/hadoop.keytabvalue>
property>
<property>
<name>yarn.nodemanager.principalname>
<value>hadoop/[email protected]value>
property>
<property>
<name>yarn.nodemanager.container-executor.classname>
<value>org.apache.hadoop.yarn.server.nodemanager.LinuxContainerExecutorvalue>
property>
<property>
<name>yarn.nodemanager.linux-container-executor.groupname>
<value>hadoopvalue>
property>
<property>
<name>yarn.https.policyname>
<value>HTTPS_ONLYvalue>
property>5.container-executor.cfg
yarn.nodemanager.linux-container-executor.group=hadoop
banned.users=hdfs
min.user.id=0
allowed.system.users=wmg,zjk,zb
LinuxContainerExecutor通过container-executor来启动容器,但是出于安全的考虑,要求其所依赖的配置文件container-executor.cfg及其各级父路径所有者必须是root用户。源码中的判断如下:
/**
* Ensure that the configuration file and all of the containing directories
* are only writable by root. Otherwise, an attacker can change the
* configuration and potentially cause damage.
* returns 0 if permissions are ok
*/
int check_configuration_permissions(const char* file_name) {
// copy the input so that we can modify it with dirname
char* dir = strdup(file_name);
char* buffer = dir;
do {
if (!is_only_root_writable(dir)) {
free(buffer);
return -1;
}
dir = dirname(dir);
} while (strcmp(dir, "/") != 0);
free(buffer);
return 0;
}
/**
* Is the file/directory only writable by root.
* Returns 1 if true
*/
static int is_only_root_writable(const char *file) {
struct stat file_stat;
if (stat(file, &file_stat) != 0) {
fprintf(ERRORFILE, "Can't stat file %s - %s\n", file, strerror(errno));
return 0;
}
if (file_stat.st_uid != 0) {
fprintf(ERRORFILE, "File %s must be owned by root, but is owned by %d\n",
file, file_stat.st_uid);
return 0;
}
if ((file_stat.st_mode & (S_IWGRP | S_IWOTH)) != 0) {
fprintf(ERRORFILE,
"File %s must not be world or group writable, but is %03o\n",
file, file_stat.st_mode & (~S_IFMT));
return 0;
}
return 1;
}在check_configuration_permissions函数中,对配置文件container-executor.cfg路径dir,在一个do循环内循环调用is_only_root_writable函数检测及所有者必须是root用户,否则不予启动容器。
而Hadoop-2.6.0在编译时,是通过如下方式确定配置文件container-executor.cfg的位置的,首先,在hadoop-yarn-server-nodemanager的pom.xml中,设置了一个名为container-executor.conf.dir的properties,其值为yarn.basedir/etc/hadoop,实际上就是$HADOOP_HOME/etc/hadoop/,如下:
<properties>
<yarn.basedir>${project.parent.parent.basedir}yarn.basedir>
<container-executor.conf.dir>../etc/hadoopcontainer-executor.conf.dir>
<container-executor.additional_cflags>container-executor.additional_cflags>
properties>
而在cmake的编译时用到了这个路径,将其赋值给DHADOOP_CONF_DIR并传入cmake编译环境,如下:
<exec executable="cmake" dir="${project.build.directory}/native" failonerror="true">
"${basedir}/src/ -DHADOOP_CONF_DIR=${container-executor.conf.dir} -DJVM_ARCH_DATA_MODEL=${sun.arch.data.model}"/>
"CFLAGS" value="${container-executor.additional_cflags}"/>
exec> 这就有一个问题,要么我们把$HADOOP_HOME各级父目录及其到container-executor.cfg的各级子目录设置其所有者为root,要么我们就得修改源码,重设路径,然后重新编译Hadoop-2.6.0,命令如下:
mvn package -Pdist,native -DskipTests -Dtar -Dcontainer-executor.conf.dir=/etc/hadoop
这两种方案都不是很好,前者隐患太大,后者比较麻烦,需要maven、protobuf等环境。
通过cmake -DHADOOP_CONF_DIR=/etc/hadoop重新编译container-executor即可,步骤如下:
cd /tmp/lp_test
tar -zxf hadoop-2.6.0-src.tar.gz
chown -R root:root hadoop-2.6.0-src
cd /tmp/lp_test/hadoop-2.6.0-src/hadoop-yarn-project/hadoop-yarn/hadoop-yarn-server/hadoop-yarn-server-nodemanager/
cmake src -DHADOOP_CONF_DIR=/etc/hadoop
makecd targe/usr/local/bin/即可获得需要的container-executor文件
切换root用户:
chown root:hadoop /etc/hadoop/container-executor.cfg
把container-executor放到/opt/beh/soft/hadoop/bin
chown root:hadoop container-executor
chmod 6050 container-executorcontainer-executor默认是DefaultContainerExecutor,是以起Nodemanager的用户身份启动container的,切换为LinuxContainerExecutor会以提交application的用户身份来启动,它使用一个setuid可执行文件来启动和销毁container