Lucene基础
最近有空就研究研究搜索引擎,写个博客记一下笔记,巩固基础
一.Lucene概述
Lucene是高性能的的信息搜索库,他是一个类库,提供了一套简单而强大的API,我们可以利用它完成文本索引和搜索功能。
Lucene最主要的两个功能是提供建立索引和搜索功能,当然还有好多其他的强大的功能,比如高亮显示等等,我在一本书上看到一个图挺好,照着画个简易版,帮助大家理解:
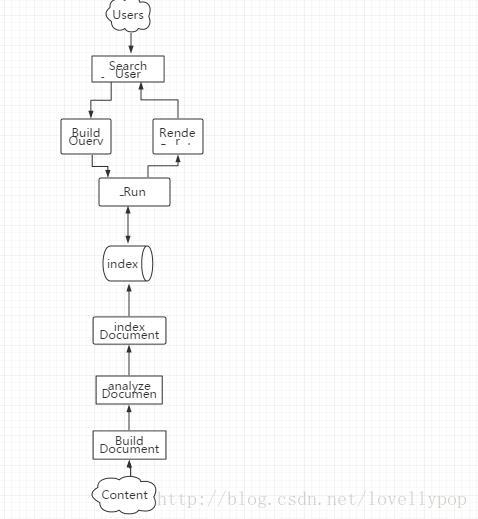
可以主要的过程是我们先根据具体的需要建立索引,这个过程的实现还是很复杂的,这里建立的索引是一种倒排索引,好在Lucene为我们屏蔽了这一切,提供非常人性化的api,我们直接用就好了。索引建立好了之后,用户搜索的时候输入的内容我们给他封装成一个query对象,根据这个对象,在索引库中搜索然后将搜索结果返回给用户。
二.建立索引
1.如果我们要搜索大量的文件,然后找出其中包含的某个词或短语的文件,初级的方法就是顺序扫描每个文件,这样的效率是很低的,对于大量的文件,我们通常采用倒排索引的办法,看一个图:
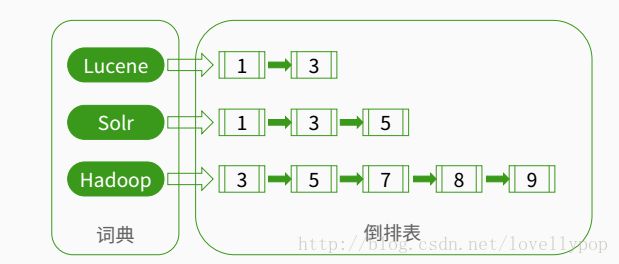
我们首先建立针对文本的索引,将文本内容转换能够进行快速搜索的格式,我们可以将索引看做是一种数据结构,通过搜索他我们就能够得到与他关联的全部文章。
2.Lucene文件结构
index:索引 一个索引放在一个文件夹中
segment: 段 一个索引中可以有很多段,段与段之间是独立的,添加新的文档可能产生新的段,不同的段可以合并成一个段
document:文档是创建索引的基本单位,不同的文档保存在不同的段,一个段包含不同的文档
field:域 一个文档包含不同的信息类型
term:词是索引的基本单位,是经过词法分析和语言处理后的数据
3.Lucene建立索引的三个步骤
将原始文档转换成文本,分析文本,将分析好的文本保存到索引中
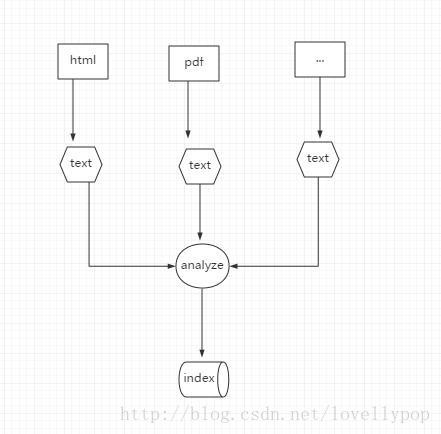
4.索引过程核心类
先直观感受下他们之间关系:
IndexWriter:写索引,是索引过程的核心组件,这个类负责创建新索引或打开已有索引,或则向索引中添加删除更新被索引文档的信息,他可以对索引文件进行写入,不能读取或搜索索引。
Directory:抽象类,子类负责具体指定索引的存储路径,然后传给indexwriter的构造方法
Analyzer:文本分析器,文本文件被索引之前,需要其处理
Document:为一个包含多个Field对象的容器
Field:包含可能被索引的文本内容的类,每个域包含一个域名和域值

5.demo分析
看了官方给的demo,跟自己写的一比,真的是自愧不如,大神就是大神,下面用大神的代码给出例子
public class IndexFiles {
private IndexFiles() {
}
public static void main(String[] args) {
//声明要被索引的文档路径和要建立索引的目录路径
String usage = "java org.apache.lucene.demo.IndexFiles [-index INDEX_PATH] [-docs DOCS_PATH] [-update]\n\nThis indexes the documents in DOCS_PATH, creating a Lucene indexin INDEX_PATH that can be searched with SearchFiles";
String indexPath = "index";
String docsPath = null;
//是否新建索引
boolean create = true;
//根据用户输入的参数设置路径及建立方式
for(int i = 0; i < args.length; ++i) {
if ("-index".equals(args[i])) {
indexPath = args[i + 1];
++i;
} else if ("-docs".equals(args[i])) {
docsPath = args[i + 1];
++i;
} else if ("-update".equals(args[i])) {
create = false;
}
}
//如果文档路径为空,终止程序
if (docsPath == null) {
System.err.println("Usage: " + usage);
System.exit(1);
}
//建立文档对象
File docDir = new File(docsPath);
//如果文档对象不存在或不可读,终止程序
if (!docDir.exists() || !docDir.canRead()) {
System.out.println("Document directory '" + docDir.getAbsolutePath() + "' does not exist or is not readable, please check the path");
System.exit(1);
}
Date start = new Date();
try {
//给出良好的用提示
System.out.println("Indexing to directory '" + indexPath + "'...");
//建立索引
Directory dir = FSDirectory.open(new File(indexPath));
//建立分词器,输入与jar对应的版本,我的jar是新版本所以这里不匹配==
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_40);
//Indexwriter的配置信息,将分词器传入构造方法中
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_40, analyzer);
//根据用户输入的方式设置打开方式
if (create) {
iwc.setOpenMode(OpenMode.CREATE);
} else {
iwc.setOpenMode(OpenMode.CREATE_OR_APPEND);
}
//建立Indexwriter,需要传入directory 对象和配置信息
IndexWriter writer = new IndexWriter(dir, iwc);
//具体创建过程
indexDocs(writer, docDir);
//关闭
writer.close();
Date end = new Date();
System.out.println(end.getTime() - start.getTime() + " total milliseconds");
} catch (IOException var12) {
System.out.println(" caught a " + var12.getClass() + "\n with message: " + var12.getMessage());
}
}
static void indexDocs(IndexWriter writer, File file) throws IOException {
//判断文档是否可读
if (file.canRead()) {
//如果是目录,对里面的文件依次建立索引,迭代调用本方法
if (file.isDirectory()) {
String[] files = file.list();
if (files != null) {
for(int i = 0; i < files.length; ++i) {
indexDocs(writer, new File(file, files[i]));
}
}
} else {
FileInputStream fis;
try {
fis = new FileInputStream(file);
} catch (FileNotFoundException var9) {
return;
}
try {
//根据具体的需求创建域对象
Document doc = new Document();
Field pathField = new StringField("path", file.getPath(), Store.YES);
doc.add(pathField);
doc.add(new LongField("modified", file.lastModified(), Store.NO));
doc.add(new TextField("contents", new BufferedReader(new InputStreamReader(fis, "UTF-8"))));
//根据具体的打开方式创建或更新
if (writer.getConfig().getOpenMode() == OpenMode.CREATE) {
System.out.println("adding " + file);
writer.addDocument(doc);
} else {
System.out.println("updating " + file);
writer.updateDocument(new Term("path", file.getPath()), doc);
}
} finally {
fis.close();
}
}
}
}
}就是很简单的建立索引的过程,必要的地方我都写了注释,应该都能看的懂,研读大神的代码还是有收获的:
一般简单的建立索引相信一般人都会写,但是最主要的是程序是否有很强的健壮性,是否有有良好的用户体验,面向对象的编程思想,对后期的维护可拓展性是否良好等等,这些都是需要我们不断加强体会的,针对本demo,多次判断文件是否存在,是否可读,并且根据用户具体的输入来编写不同的建立方式等等,这些都是我们应该学习的,当然这还是需要大量的练习和经验的。所以,特别推荐大家有空多研读现在开源框架等的源码,一定很有收获
三.搜索索引
1.搜索过程核心类
IndexSeacher: 可以看成以只读方式打开索引的类,用于搜索由IndexWriter类创建的索引
Term:搜索功能的基本单元,Term对象包含一对字符串元素:域名和单词
Query:有许多子类,最常用的是TermQuery
TermQuery:最基本的查询类型,用于匹配指定域中包含特定项的文档
TopDocs:是一个简单的指针容器,指针一般指向前N个排名的搜索结果
2.demo
这里我自己写了个简单的例子,很好理解
public class IndexSearchTest {
public static void main(String[] argcs){
Directory directory = null;
try {
//建立索引
directory = FSDirectory.open(new File("D://Lucene/test"));
//创建Reader对象
DirectoryReader dReader = DirectoryReader.open(directory);
//创建indexSearcher对象
IndexSearcher indexSearcher = new IndexSearcher(dReader);
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_43);
//用queryparser对象解析用户输入的内容
QueryParser queryParser = new QueryParser(Version.LUCENE_43,"content",analyzer);
//通过queryparser得到query
Query query = queryParser.parse("t");
//获得topdocs对象,这个对象包含得到的结果信息
TopDocs topDocs = indexSearcher.search(query,10);
//遍历输出
if(topDocs!=null){
System.out.println("total:"+topDocs.totalHits);
for (int i = 0; i out.println(document.get("id"));
}
}
directory.close();
dReader.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
}