7.2 内存池的核心逻辑—内存栈
在内存池中,首先要有一个内存块管理的核心模块,来负责所有内存块的申请、分发、回收和释放工作,经过设计,笔者是使用“栈”来完成的这个模块,因此,笔者将其定名为“内存栈”(Memory Stack)。下面我们将详细讨论其设计细节。
7.2.1 内存管理的数学模型
内存块如果要提升可重用性,必须对内存块尺寸进行取模,否则的话,很容易因为几个Bytes的偏差,导致内存块无法重用,被迫向系统频繁申请新的内存空间,那意义就不大了。
取模的主要目的,是减少内存块的种类,以有限几个尺寸的内存块,应对绝大多数内存使用要求。
笔者看过STL的内存管理模块源代码,对其内存块的取模机制深表钦佩,因此,在笔者自己的内存池中,也是按照这种方式取模。
提示:32位系统,有个字节对齐问题,即一个程序变量单元,如一个结构体,一个内存块,如果其尺寸不是4Bytes的整倍数,操作系统会按照比它大的整倍数分配内存,这其实也是操作系统在取模。比如我们的一个结构体为7Bytes,操作系统分配时会分配8Bytes,一个14Bytes的内存块,操作系统会分配16Bytes,这主要是简化内存地址运算,以一定的内存消耗,来提升程序的运行速度。
我们对内存的取模也是这个原理,当然,我们不可能像操作系统那样,机械地以4Bytes为模数,那样,内存块种类还是太多,管理起来压力很大,内存池的效率也不高。
笔者仿造STL的取模方式,在内存池中按照如下逻辑取模,简单说来,就是从16Bytes开始,以两倍方式递增模数。直到 4G 内存为止。当然,实际使用时,超过 1M 的内存块,一般应用很少,即使有,基本上也属于应用程序永久缓冲区,很少会中途频繁释放,因此,笔者的内存池管理,一般模数为16Bytes~ 1M 即可。
| 序号 |
内存块大小模数(Bytes) |
应对申请需求(Bytes) |
| 1 |
16 |
1~16 |
| 2 |
32 |
17~32 |
| 3 |
64 |
33~64 |
| 4 |
128 |
65~128 |
| 5 |
256 |
129~256 |
| 6 |
512 |
257~512 |
| 7 |
1k |
513~1k |
| 8 |
2k |
1k+1~2k |
| 9 |
4k |
2k+1~4k |
| 10 |
8k |
4k+1~8k |
| 11 |
16k |
8k+1~16k |
| 12 |
32k |
16k+1~32k |
| 13 |
64k |
32k+1~64k |
| 14 |
128k |
64k+1~128k |
| 15 |
256k |
128k+1~256k |
| 16 |
512k |
256k+1~512k |
| 17 |
1M |
512k+1~ 1M |
| 图7.1:内存模数表 |
如表7.1所示,内存池实际上是一个树型数据结构在管理,每一种类型的内存块,构成一个链表,形成树的“右枝”,而所有右枝的链头,又是以一个链表在管理,形成树的“左枝”。请注意,这并不是二叉树,还是一颗普通的树结构。如下图所示:
|
图7.2:内存管理树模型 |
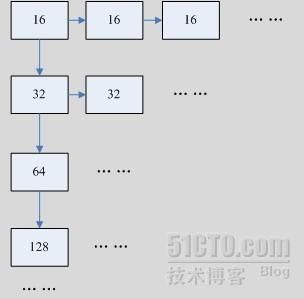
| 我们举个例子,当应用程序申请一块57Bytes的内存块,程序逻辑会沿着树的左枝,从头到尾比对,首先是16Bytes的的管理链,由于57>16,因此,无法在这根右枝进行管理,因此继续往下,32Bytes也不行,64Bytes,比57要大,可以使用,因此,就在64Bytes这根右枝实现内存块管理。 |
管理原则:分配时,首先在合适的右枝寻找可用的内存块,如果有,则直接分配给应用程序重用该块,如果没有,则向系统申请一块64Bytes的内存块,分配给应用程序使用。而当应用程序释放时,内存块本身是64Bytes的,因此,可以直接挂回到64Bytes这根右枝,等待下次重用。
提示:这里面有一个隐含的推论,如果一个应用程序,需要一块57Bytes的内存块,那么,我们分配一块比它大的内存块,比如64Bytes的内存块,是完全可以的,应用程序不关心自己实际获得的内存块大小,同时,这种稍稍超大的分配机制,也不回引发任何的内存溢出bug,反而更安全,因此,这种内存取模分配的思路,是完全可行的。
7.2.2 管理模型的优化
虽然上文我们讨论的是以链表方式管理,不过,在实做中,笔者发现一个问题,即链表效率不高,原因很简单,笔者的链表是以队列方式管理,每次从右枝取出内存块,是从链表头取出,但释放时,将内存块推回右枝,需要循环遍历到链表尾部进行挂链操作。这在高速的内存申请和释放时,会严重影响链表的效率。
笔者经过思考,发现一个问题,当一个内存块被推回一个右枝,其实已经是无属性的,比如,64Bytes这个右枝上,挂的都是64Bytes大小的内存块,应用程序申请时,使用任何一块都是可以的,无需考虑这块是在链头还是链尾,同时,申请的内存块,都是需要初始化的,应用程序也不关心这块内存块是否刚刚被使用完,还是已经空闲很久了。笔者理解这个内存树的右枝,其实已经是前文所说的“被动池”逻辑了。
我们知道,在“推”入和“提取”这个逻辑上,“栈”的效率远高于“队列”,通常我们不使用栈的唯一原因,主要是栈是“后进先出”逻辑,而队列是“先进先出”逻辑,而我们常见的应用模型,一般都有数据顺序要求,因此,队列的使用场合,远多于栈结构。
但此处既然我们已经明确论证了,内存块无顺序需求,那么,我们完全可以使用栈模型来管理内存树的右枝,以提高效率。
这在实做时非常简单,当应用程序释放一块内存,我们需要推回右枝时,直接将其挂接到链头即可,取消了无意义的循环遍历链尾的操作,虽然,下次申请时,最后释放的一块内存会被最先分配使用,但这又有什么关系呢?
这个优化看似很小,但实做时威力惊人,经笔者测试,内存块的申请和释放吞吐量,在“队列”管理方式下,每秒仅5万次左右,一旦使用“栈”方式管理,迅速提升到40~50万次,提升了整整一个数量级。
正因为如此,笔者才将内存池最核心的内存管理模块,定名为内存栈(Memory Stack)。
提示:在进行程序开发时,很多时候,需要针对业务需求进行分析,实现针对性优化,很多时候,很小的一点优化,都可以大幅度提升程序的性能。反过来说,通用的优化其实不存在,只有深刻理解了业务需求之后,才有可能实施有效的优化方案。
提示:原则上,程序开发应该遵循“先实现,后优化”的原则,笔者常说的“先解决有无问题,再解决好坏问题”,也是这个意思,本章在此先讨论优化,是因为笔者这个内存池在实践中已经经过了多次优化,有条件讨论此事,并不意味着可以再程序实现前实施优化,请各位读者关注这个细节。事实上,本书展示的内存池,已经是笔者第19个版本,中间经过了十几次优化的结果。
7.2.3 关于链表管理的思考
讨论完上面的问题,我们再来讨论一下基本数据结构管理的问题。我们知道,虽然我们的内存池是树结构管理,但具体到每个右枝上,还是链表,而链表元素是动态申请的,依赖内部指向下一元素的指针,实现链接关系。
具体到我们内存块管理上,我们发现一个基本的链表元素,至少需要定义成如下形式:
| typedef struct _CHAIN_TOKEN_ { struct _CHAIN_TOKEN_* m_pNext; //指向下一链表元素的指针 char* m_pBuffer; //指向真实内存块的指针 }SChainToken; |
这就带来一个问题,链表的元素,应该分为两部分,一部分是实现链表管理的逻辑数据,如:m_pNext,另一部分,是业务相关的数据,如m_pBuffer,这样的数据结构,造成程序开发非常麻烦。
比如一个简单的内存申请和释放动作,以上述数据结构管理,其基本逻辑如下:
| 内存申请: 1、检查链表有无空闲内存单元 2、如果有,提取其中的m_pBuffer,准备返回给应用程序使用 3、从链表中卸载已经为空的链表管理元素,直接释放给系统(注意,无管控的内存块释放,内存碎片的隐患) 内存释放: 1、寻找合适的链,准备做挂链操作 2、申请一个链表管理单元,将内存块的指针放入其中的m_pBuffer 3、执行挂链操作,填充m_pBext指针 |
大家注意到没有,我们本意是内存管理,减小内存碎片,但是,为了实现链表的管理,反而中间引入了一个多余的链表单元申请和释放逻辑,反而增加了内存碎片的产生可能,这种方法当然不可取。
另外,这里还有一个隐患,我们分配给应用程序的内存块,其中所有的内存单元,都是对应用程序透明的,应用程序可以任意使用,这说明,这块内存块中,没有存储任何关于内存块尺寸的信息,当应用程序释放指针时,我们面临一个问题,就是怎么确定这根指针指向的内存块,究竟有多大,应该挂在哪个右枝上,等待下次使用。
这个问题不解决,上述的内存释放逻辑的第一步,寻找合适的链,根本无法完成。
因此,为了记录内存块的尺寸信息,我们必须内部再建立一个映射表,将我们管理的每根内存块指针,在申请时的具体尺寸,都记录下来,等释放时,需要根据指针,逆查其对应的长度数据,才能完成功能。
笔者做开发有个原则:“简单的程序才是好程序”,上述逻辑虽然最终也能完成功能,但无论怎么看,都太复杂了,不是好的解决方案。
为此,笔者经过了较长时间的思考,发现所有问题的核心焦点,无非只有两条:
| 1、如何使链表的管理数据,不要发生新的动态内存分配。 2、如何使分配出去的指针,能够携带相关的缓冲区尺寸信息,避免额外的存储和查询压力。 |
经过分析,笔者突发奇想,既然我们内存池管理的就是内存块,就有存储能力,为什么我们不能利用内存块做一点自己的管理数据存储呢?大不了这个内存块实际可用内存,比我们从操作系统申请的,要小一点,但这又有什么关系呢?应用程序需要的只是自己需要的内存块,这个内存块原来有多大?能给应用程序使用的又有多大?应用程序并不关心。
经过考虑,笔者做了如下一个结构体:
| typedef struct _TONY_MEM_BLOCK_HEAD_ { ULONG m_ulBlockSize; //内存块的尺寸 struct _TONY_MEM_BLOCK_HEAD_* m_pNext; //指向下一链表元素的指针 }STonyMemoryBlockHead; //本结构体的长度,经过计算,恒定为8Bytes const ULONG STonyMemoryBlockHeadSize=sizeof(STonyMemoryBlockHead); |
上述结构体,包含了内存块尺寸信息,来满足释放时查找的需求,同时,包含了指向下一元素的指针,这个指针,在分配给应用程序使用时,是无效的,只有当这个内存块挂接在链表中时,才有意义。
笔者这么思考,当我们向系统申请一个内存块,比如说64Bytes,我们内存池占用其中最开始的8Bytes来存储上述信息,也就是说,实际能给应用程序使用的,只有56Bytes。如图7.3:
|
图7.3:内存块组织结构 |
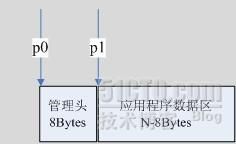
我们假定这个内存块的真实尺寸为N Bytes,我们从系统申请的首指针为p0,那么,我们占用8Bytes作为管理使用,当应用程序申请时,我们真实分配给应用程序的指针为p1=(p0+8)。这样,当应用程序释放时,我们只需要执行p0=(p1-8),即可求出原始首地址,并以此获得所有的管理信息。当最后向系统释放内存时,我们只要记得释放p0即可。
提示:此处可能出于业务考虑,有点违背C和C++无错化程序设计方法中,关于指针不得参与四则运算的原则,不过,没办法,需求如此,只有这条路走了。因此,违背就违背一点了。
唯一需要我们注意的细节,是我们在分析应用程序的内存申请需求时,不能以申请的内存块的真实尺寸进行比对,而应该比对减去8Bytes之后的数据。即64Bytes这个右枝上提供的内存,只有56Bytes大小,如果超过这个值,请找下一链,即到128 Bytes这个右枝处理,当然,此时的128 Byte的右枝,也仅能提供120 Bytes的内存块,以此类推。
有鉴于此,笔者做了如下的宏定义,来界定所有的计算行为:
| //根据一个应用程序数据块的长度,计算一个内存块的真实大小,即n+8 #define TONY_MEM_BLOCK_SIZE(nDataLength) \ (nDataLength+STonyMemoryBlockHeadSize) //根据向系统申请的内存块,计算其应用程序数据内存的真实大小,即n-8 #define TONY_MEM_BLOCK_DATA_SIZE(nBlockSize) \ (nBlockSize-STonyMemoryBlockHeadSize) //根据应用程序释放的指针,逆求真实的内存块指针,即p0=p1-8 #define TONY_MEM_BLOCK_HEAD(pData) \ ((STonyMemoryBlockHead*)(((char*)pData)-STonyMemoryBlockHeadSize)) //根据一个内存块的真实指针,求数据内存块的指针,即p1=p0+8 #define TONY_MEM_BLOCK_DATA(pHead) \ (((char*)pHead)+STonyMemoryBlockHeadSize) //最小内存块长度,16 Bytes,由于我们管理占用8 Bytes,这个最小长度不能再小了, //否则无意义,即使这样,我们最小的内存块,能分配给应用程序使用的,仅有8 Bytes。 #define TONY_XIAO_MEMORY_STACK_BLOCK_MIN 16 //这是管理的最大内存块长度, 1M ,如前文表中所示,超过此限制,内存池停止服务 //改为直接向系统申请和释放。 #define TONY_XIAO_MEMORY_STACK_MAX_SAVE_BLOCK_SIZE (1*1024*1024) |