Locust 编写简单性能测试脚本
我们以访问百度首页来进行举例:
首先创建一个test.py的文件
from locust import HttpLocust, TaskSet, task
# 定义用户行为
class MyTaskSet(TaskSet):
@task
def baidu_index(self):
self.client.get("/")
class WebsiteUser(HttpLocust):
task_set = MyTaskSet
min_wait = 3000 # 单位为毫秒
max_wait = 6000
脚本说明:
新建一个类MyTaskSet(TaskSet),继承TaskSet,该类下面写需要请求的接口以及相关信息;
self.client调用get和post方法,locust的脚本里,模拟负载的请求和python的requests库使用方法基本一样,在这里因为我们准备访问百度首页,所以指定为根路径;
@task装饰该方法表示为用户行为,可以在括号里填写执行权重,例如@task(1):数值越大,执行频率越高,不设置默认是1;
WebsiteUser()类用于设置生成负载的基本属性:
| 属性 | 说明 |
|---|---|
| task_set | 指向定义了用户行为的类 |
| min_wait | 模拟负载的任务之间执行时的最小等待时间,单位为毫秒 |
| max_wait | 模拟负载的任务之间执行时的最大等待时间,单位为毫秒 |
然后,我们通过以下命令执行脚本
locust -f path/test.py --host=https://www.baidu.com

浏览器访问http://localhost:8089/
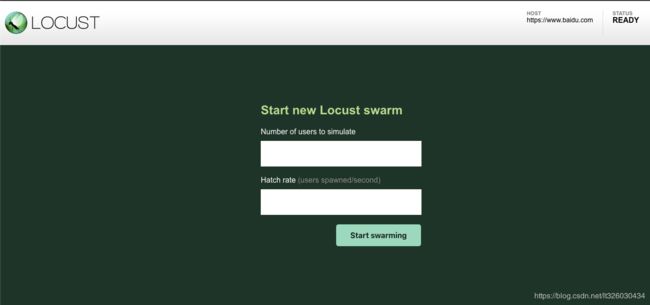
Number of users to simulate 设置模拟用户数。
Hatch rate(users spawned/second) 每秒产生(启动)的虚拟用户数。
点击 “Start swarming” 按钮,开始运行性能测试。
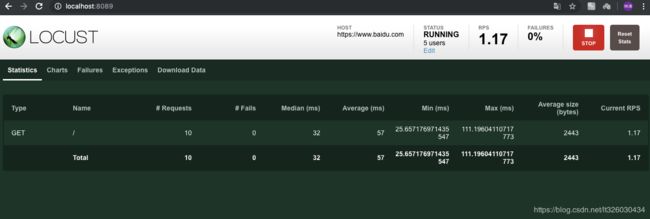
性能测试参数:
-
Type: 请求的类型,例如GET/POST。
-
Name:请求的路径。这里为百度首页,即:https://www.baidu.com/
-
request:当前请求的数量。
-
fails:当前请求失败的数量。
-
Median:中间值,单位毫秒,一半的服务器响应时间低于该值,而另一半高于该值。
-
Average:平均值,单位毫秒,所有请求的平均响应时间。
-
Min:请求的最小服务器响应时间,单位毫秒。
-
Max:请求的最大服务器响应时间,单位毫秒。
-
Content Size:单个请求的大小,单位字节。
-
reqs/sec:是每秒钟请求的个数,即qps。
其他模块:
-
New test:点击该按钮可对模拟的总虚拟用户数和每秒启动的虚拟用户数进行编辑。
-
Statistics:类似于jmeter中Listen的聚合报告。
-
Charts:测试结果变化趋势的曲线展示图,分别为每秒完成的请求数(RPS)、响应时间、不同时间的虚拟用户数。
-
Failures:失败请求的展示界面。
-
Exceptions:异常请求的展示界面。
-
Download Data:测试数据下载模块, 提供三种类型的CSV格式的下载,分别是:Statistics、responsetime、exceptions。