两行代码玩转Google BERT句向量词向量
转自:https://zhuanlan.zhihu.com/p/50582974

两行代码玩转Google BERT句向量词向量
PaperWeekly
微信公众号PaperWeekly
262 人赞同了该文章
关于作者:肖涵博士,bert-as-service 作者。现为腾讯 AI Lab 高级科学家、德中人工智能协会主席。 肖涵的 Fashion-MNIST 数据集已成为机器学习基准集,在 Github 上超过 4.4K 星,一年来其学术引用数超过 300 篇。
肖涵在德国慕尼黑工业大学计算机系取得了计算机博士(2014)和硕士学位(2011),在北邮取得了信息通信学士学位(2009)。他曾于 2014-2018 年初就职于位于德国柏林的 Zalando 电商,先后在其推荐组、搜索组和 Research 组担任高级数据科学家。肖涵所创办的德中人工智能协会(GCAAI)如今拥有 400 余名会员,致力于德中两国 AI 领域的合作与交流,是德国最具影响力的新型团体之一。
WeChat: hxiao1987
Blog: https://hanxiao.github.io
德中人工智能协会: https://gcaai.org
Google AI 几周前发布的 BERT (Bidirectional Encoder Representations from Transformers) 模型在 NLP 圈掀起了轩然大波,其使用超多层 Transformer + 双任务预训练 + 后期微调的训练策略,在 11 个不同类型的 NLP 任务上刷新了纪录。
Google 随后在 Github 上开源了 BERT 的代码,并提供了在维基百科语料上使用 TPU 预训练好的模型供大家下载。这其中也包括了基于字符级别的中文 BERT 预训练模型。

bert-as-service 能让你简单通过两行代码,即可使用预训练好的模型生成句向量和 ELMo 风格的词向量:
你可以将 bert-as-service 作为公共基础设施的一部分,部署在一台 GPU 服务器上,使用多台机器从远程同时连接实时获取向量,当做特征信息输入到下游模型。
回顾:BERT的训练机制
BERT 模型的训练分为预训练(Pre-training)和微调(Fine-tunning)两步。预训练和下游任务无关,却是一个非常耗时耗钱的过程。Google 坦言,对 BERT 的预训练一般需要 4 到 16 块 TPU 和一周的时间,才可以训练完成。
庆幸的是,大部分 NLP 研究者只需使用 Google 发布的预训练模型,而不需要重复这一过程。你可以把预训练模型想象成一个 Prior,是对语言的先验知识,一旦拥有就不需要重复构造。
微调取决于下游的具体任务。不同的下游任务意味着不同的网络扩展结构:比如一个对句子进行情感分类的任务,只需要在 BERT 的输出层句向量上接入几个 Dense 层,走个 softmax。而对于 SQuAD 上的阅读理解任务,需要对 BERT 输出的词向量增加 match 层和 softmax。
总体来说,对 BERT 的微调是一个轻量级任务,微调主要调整的是扩展网络而非 BERT 本身。换句话说,我们完全可以固定住 BERT 的参数,把 BERT 输出的向量编码当做一个特征(feature)信息,用于各种下游任务。
无论下游是什么任务,对于 NLP 研究者来说,最重要的就是获取一段文字或一个句子的定长向量表示,而将变长的句子编码成定长向量的这一过程叫做 sentence encoding/embedding。
bert-as-service 正是出于此设计理念,将预训练好的 BERT 模型作为一个服务独立运行,客户端仅需通过简单的 API 即可调用服务获取句子、词级别上的向量。在实现下游任务时,无需将整个 BERT 加载到 tf.graph 中,甚至不需要 TensorFlow 也不需要 GPU,就可以在 scikit-learn, PyTorch, Numpy 中直接使用 BERT。
bert-as-service
bert-as-service 将 BERT模型作为一个独立的句子编码(sequence encoding/embedding)服务,在客户端仅用两行代码就可以对句子进行高效编码。其主要特色如下:
- state-of-the-art:基于 Google 最新发布的 BERT 模型;
- 易用:客户端仅需简单两行代码即可调用;
- 快速:每秒 780 个句子(见详细评测);
- 并发性:自动扩展到多块 GPU,多客户端,高效任务调度,无延迟(见针对多客户端并发的评测)。
使用方法
1. 下载 Google 发布的预训练 BERT 模型
从下方链接下载 Google 发布的预训练模型,解压到某个路径下,比如: /tmp/english_L-12_H-768_A-12/
你可以使用包括 BERT-Base, Multilingual 和 BERT-Base, Chinese 在内的任意模型。
2. 开启 BERT 服务
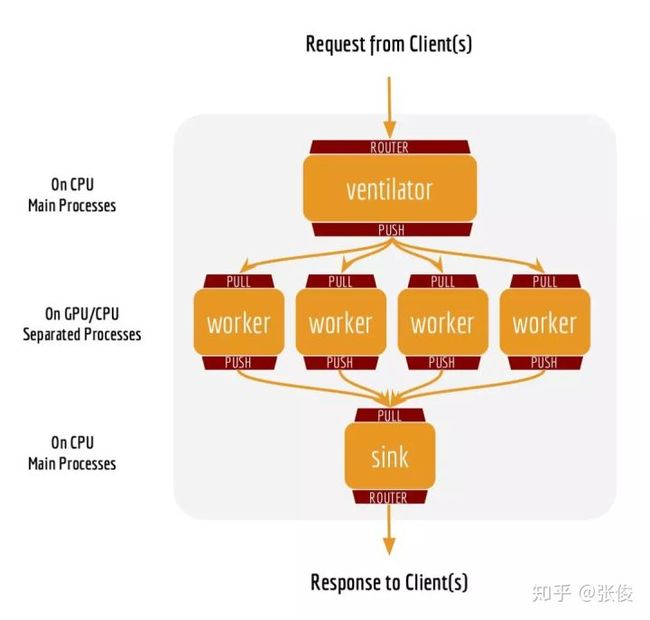
python app.py -model_dir /tmp/english_L-12_H-768_A-12/ -num_worker=4这个代码将开启一个 4 进程的 BERT 服务,意味着它可以最高处理来自 4 个客户端的并发请求。虽然同一时刻连接服务的客户端数量没有限制,但在某时刻多余 4 个的并发请求将被暂时放到一个负载均衡中,等待执行。有关 bert-as-service 背后的架构可以参考 FAQ 和并发客户端性能评测。
3. 使用客户端获取句子向量编码
对于客户端来说,你唯一需要的文件就是 service/client.py ,因为我们需要从中导入 BertClient。
from service.client import BertClient
bc = BertClient()
bc.encode(['First do it', 'then do it right', 'then do it better'])这会返回一个 3 x 768 的 ndarray 结构,每一行代表了一句话的向量编码。你也可以通过设置,让其返回 Python 类型的 List[List[float]] 。
在另一台机器上使用 BERT 服务
客户端也可以从另一台机器上连接 BERT 服务,只需要一个 IP 地址和端口号:
# on another CPU machine
from service.client import BertClient
bc = BertClient(ip='xx.xx.xx.xx', port=5555) # ip address of the GPU machine
bc.encode(['First do it', 'then do it right', 'then do it better'])你还可以把服务架设在 docker container 中使用,详情可以参考项目的 README.md。bert-as-service 所支持的 C/S 模式可以用下图总结:

性能评测
作为一个基础服务,速度和伸缩性(scalability)非常关键。只有当下游的模型能够通过其快速流畅地获取数据时,该服务的意义才能得到最大体现。BERT 的网络复杂度众所周知,那么 bert-as-service 能否达到工程级别的速度?为了验证这一点,我们做了如下方面的评测。
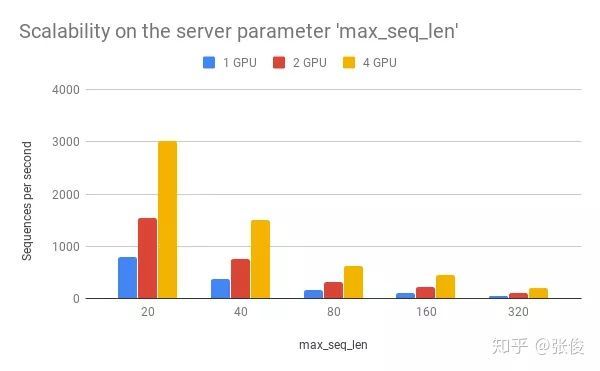
max_seq_len 对速度的影响
max_seq_len 是服务端的一个参数,用来控制 BERT 模型所接受的最大序列长度。当输入的序列长度长于 max_seq_len 时,右侧多余字符将被直接截断。所以如果你想处理很长的句子,服务器端正确设置 max_seq_len 是其中一个关键指标。而从性能上来讲,过大的 max_seq_len 会拖慢计算速度,并很有可能造成内存 OOM。

client_batch_size 对速度的影响
client_batch_size 是指每一次客户端调用 encode() 时所传给服务器 List 的大小。出于性能考虑,请尽可能每次传入较多的句子而非一次只传一个。比如,使用下列方法调用:
# prepare your sent in advance
bc = BertClient()
my_sentences = [s for s in my_corpus.iter()]
# doing encoding in one-shot
vec = bc.encode(my_sentences)而不要使用:
bc = BertClient()
vec = []
for s in my_corpus.iter():
vec.append(bc.encode(s))如果你把 bc = BertClient() 放在了循环之内,则性能会更差。当然在一些时候,一次仅传入一个句子无法避免,尤其是在小流量在线环境中。


num_client 对并发性和速度的影响
num_client 指同时连接服务的客户端数量。当把 bert-as-service 作为公共基础设施时,可能会同时有多个客户端连接到服务获取向量。


可以看到一个客户端、一块 GPU 的处理速度是每秒 381 个句子(句子的长度为 40),两个客户端、两个 GPU 是每秒 402 个,四个客户端、四个 GPU 的速度是每秒 413 个。这体现了 bert-as-service 良好的伸缩性:当 GPU 的数量增多时,服务对每个客户端请求的处理速度保持稳定甚至略有增高(因为空隙时刻被更有效地利用)。