简介
本文介绍一下机器学习和深度学习中常用的优化算法和优化器以及一些其他我知道的优化算法,部分算法我也没有搞懂,就先记录下来以后慢慢研究吧.*_*.
1.梯度下降算法(Gradient Descent)
梯度下降法可以参考我另一篇文章机器学习-线性回归里的讲解,这里就不在重复叙述.这里需要强调一下,深度学习里常用的SGD,翻译过来是随机梯度下降,但是实质是mini-batch梯度下降(mini-batch-gd),或者说是两者的结合更准确一些.
SGD的优点是,算法简单,计算量小,在函数为凸函数时可以找到全局最优解.所以是最常用的优化算法.缺点是如果函数不是凸函数的话,很容易进入到局部最优解而无法跳出来.同时SGD在选择学习率上也是比较困难的.
2.牛顿法
牛顿法和拟牛顿法都是求解无约束最优化问题的常用方法,其中牛顿法是迭代算法,每一步需要求解目标函数的海森矩阵的逆矩阵,计算比较复杂.
牛顿法在求解方程根的思想:在二维情况下,迭代的寻找某一点x,寻找方法是随机一个初始点x_0,目标函数在该点x_0的切线与x坐标轴的交点就是下一个x点,也就是x_1.不断迭代寻找x.其中切线的斜率为目标函数在点x_0的导数(梯度),切必过点(x_0,f(x_0)).所以迭代的方程式如图1,为了求该方程的极值点,还需要令其导数等于0,也就是又求了一次导数,所以需要用到f(x)的二阶导数.
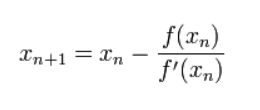
在最优化的问题中,牛顿法提供了一种求解的办法. 假设任务是优化一个目标函数f, 求函数ff的极大极小问题, 可以转化为求解函数f导数等于0的问题, 这样求可以把优化问题看成方程求解问题(f的导数等于0). 剩下的问题就和牛顿法求解方程根的思想很相似了.
目标函数的泰勒展开式:

化简后:
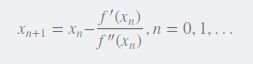
这样就得到了与图1相似的公式,这里是二维的,在多维空间上,求二阶导数就是求海森矩阵,因为是分母,所以还需要求海森矩阵的逆矩阵.
牛顿法和SGD的区别:
牛顿法是二阶求导,SGD是一阶求导,所以牛顿法要收敛的更快一些.SGD只考虑当前情况下梯度下降最快的方向,而牛顿法不仅考虑当前梯度下降最快,还有考虑下一步下降最快的方向.
牛顿法的优点是二阶求导下降速度快,但是因为是迭代算法,每一步都需要求解海森矩阵的逆矩阵,所以计算复杂.
3.拟牛顿法(没搞懂,待定)
考虑到牛顿法计算海森矩阵比较麻烦,所以它使用正定矩阵来代替海森矩阵的逆矩阵,从而简化了计算过程.
常用的拟牛顿法有DFP算法和BFGS算法.
4.共轭梯度法(Conjugate Gradient)
共轭梯度法是介于最速下降法与牛顿法之间的一个方法,它仅需利用一阶导数信息,但克服了最速下降法收敛慢的缺点,又避免了牛顿法计算海森矩阵并求逆的缺点.共轭梯度法不仅是解决大型线性方程组最有用的方法之一,也是解大型非线性最优化最有效的算法之一.
5.拉格朗日法
参考SVM里的讲解机器学习-SVM
6.动量优化法(Momentum)
动量优化法主要是在SGD的基础上,加入了历史的梯度更新信息或者说是加入了速度更新.SGD虽然是很流行的优化算法,但是其学习过程很慢,因为总是以同样的步长沿着梯度下降的方向.所以动量是为了加速学习的方法.
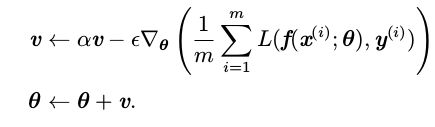
其中第一行的减号部分是计算当前的梯度,第一行是根据梯度更新速度v,而α是新引进的参数,在实践中,α的一般取值为 0.5,0.9 和 0.99.和学习率一样,α 也会随着时间不断调整.一般初始值是一个较小的值,随后会慢慢变大.
7.Nesterov加速梯度(NAG, Nesterov accelerated gradient)
NAG是在动量优化算法的基础上又进行了改进.根据下图可以看出,Nesterov 动量和标准动量之间的区别体现在梯度计算上, Nesterov 动量中,梯度计算在施加当前速度之后.因此,Nesterov 动量可以解释为往标准动量方法中添加了一个校正因子
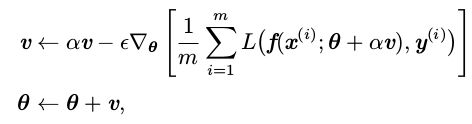
8.AdaGrad算法
AdaGrad算法,自适应优化算法的一种,独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平均值总和的平方根.具有代价函数最大梯度的参数相应地有个快速下降的学习率,而具有小梯度的参数在学习率上有相对较小的下降.通俗一点的讲,就是根据实际情况更改学习率,比如模型快要收敛的时候,学习率步长就会小一点,防止跳出最优解.
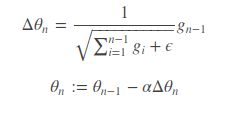
其中g是梯度,第一行的分母是计算累计梯度的平方根,是为了防止分母为0加上的极小常数项,α是学习率.
Adagrad的主要优点是不需要人为的调节学习率,它可以自动调节.但是依然需要设置一个初始的全局学习率.缺点是随着迭代次数增多,学习率会越来越小,最终会趋近于0.
9.RMSProp算法
RMSProp修改 AdaGrad 以在非凸设定下效果更好,改变梯度积累为指数加权的移动平均.AdaGrad旨在应用于凸问题时快速收敛.
10.AdaDelta算法
11.Adam算法
Adam是Momentum和RMSprop的结合体,也就是带动量的自适应优化算法.
12.Nadam算法
13.模拟退火算法
14.蚁群算法
15.遗传算法
总结:
动量是为了加快学习速度,而自适应是为了加快收敛速度,注意学习速度快不一定收敛速度就快,比如步长大学习速度快,但是很容易跳出极值点,在极值点附近波动,很难达到收敛.
未完待定....
参考:
《统计学习方法》 李航 著
《深度学习》 花书