浏览器工作原理(四):HTML解析器 HTML Parser
HTML解析器的工作是将html标识解析为解析树。
HTML文法定义(The HTML grammar definition)
W3C组织制定规范定义了HTML的词汇表和语法。非上下文无关文法(Not a context free grammar)
正如在解析简介中提到的,上下文无关文法的语法可以用类似BNF的格式来定义。不幸的是,所有的传统解析方式都不适用于html(当然我提出它们并不只是因为好玩,它们将用来解析css和js),html不能简单的用解析所需的上下文无关文法来定义。
Html有一个正式的格式定义——DTD(Document Type Definition文档类型定义)——但它并不是上下文无关文法,html更接近于xml,现在有很多可用的xml解析器,html有个xml的变体——xhtml,它们间的不同在于,html更宽容,它允许忽略一些特定标签,有时可以省略开始或结束标签。总的来说,它是一种soft语法,不像xml呆板、固执。
显然,这个看起来很小的差异却带来了很大的不同。一方面,这是html流行的原因——它的宽容使web开发人员的工作更加轻松,但另一方面,这也使很难去写一个格式化的文法。所以,html的解析并不简单,它既不能用传统的解析器解析,也不能用xml解析器解析。
HTML DTD
Html适用DTD格式进行定义,这一格式是用于定义SGML家族的语言,包括了对所有允许元素及它们的属性和层次关系的定义。正如前面提到的,html DTD并没有生成一种上下文无关文法。
DTD有一些变种,标准模式只遵守规范,而其他模式则包含了对浏览器过去所使用标签的支持,这么做是为了兼容以前内容。最新的标准DTD在http://www.w3.org/TR/html4/strict.dtd
DOM
输出的树,也就是解析树,是由DOM元素及属性节点组成的。DOM是文档对象模型的缩写,它是html文档的对象表示,作为html元素的外部接口供js等调用。
树的根是“document”对象。
DOM和标签基本是一一对应的关系,例如,如下的标签:
Hello DOM

将会被转换为下面的DOM树:
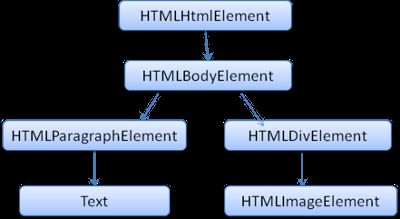
图8:示例标签对应的DOM树
和html一样,DOM的规范也是由W3C组织制定的。访问http://www.w3.org/DOM/DOMTR,这是使用文档的一般规范。一个模型描述一种特定的html元素,可以在http://www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.htm查看html定义。
解析算法(The parsing algorithm)
正如前面章节中讨论的,hmtl不能被一般的自顶向下或自底向上的解析器所解析。
原因是:
1. 这门语言本身的宽容特性
2. 浏览器对一些常见的非法html有容错机制
3. 解析过程是往复的,通常源码不会在解析过程中发生改变,但在html中,脚本标签包含的“document.write”可能添加标签,这说明在解析过程中实际上修改了输入。
不能使用正则解析技术,浏览器为html定制了专属的解析器。
Html5规范中描述了这个解析算法,算法包括两个阶段——符号化及构建树。
符号化是词法分析的过程,将输入解析为符号,html的符号包括开始标签、结束标签、属性名及属性值。
符号识别器识别出符号后,将其传递给树构建器,并读取下一个字符,以识别下一个符号,这样直到处理完所有输入。
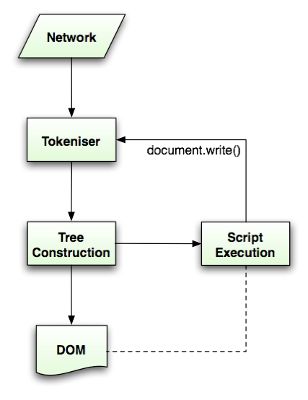
符号识别算法(The tokenization algorithm)
算法输出html符号,该算法用状态机表示。每次读取输入流中的一个或多个字符,并根据这些字符转移到下一个状态,当前的符号状态及构建树状态共同影响结果,这意味着,读取同样的字符,可能因为当前状态的不同,得到不同的结果以进入下一个正确的状态。
这个算法很复杂,这里用一个简单的例子来解释这个原理。
基本示例——符号化下面的html:
Hello world
初始状态为“Data State”,当遇到“<”字符,状态变为“Tag open state”,读取一个a-z的字符将产生一个开始标签符号,状态相应变为“Tag name state”,一直保持这个状态直到读取到“>”,每个字符都附加到这个符号名上,例子中创建的是一个html符号。
当读取到“>”,当前的符号就完成了,此时,状态回到“Data state”,“
”重复这一处理过程。到这里,html和body标签都识别出来了。现在,回到“Data state”,读取“Hello world”中的字符“H”将创建并识别出一个字符符号,这里会为“Hello world”中的每个字符生成一个字符符号。这样直到遇到“”中的“<”。现在,又回到了“Tag open state”,读取下一个字符“/”将创建一个闭合标签符号,并且状态转移到“Tag name state”,还是保持这一状态,直到遇到“>”。然后,产生一个新的标签符号并回到“Data state”。后面的“