行人重识别数据集转换--统一为market1501数据集进行多数据集联合训练
https://www.codetd.com/article/10334372
行人reid 常用数据集以及转换成market1501感谢作者,
行人重识别数据集转换--统一为market1501数据集进行多数据集联合训练
其他
2020-03-31 10:58:29
阅读次数: 0
0 前言
常用的reID数据集如图所示

下载好数据集,我的数据集一开始是这样的
第一步 创建出来market1501的数据集文件夹格式
market1501数据集的具体介绍可以看看这个 http://blog.fangchengjin.cn/reid-market-1501.html
import os
def make_market_dir(dst_dir=’./’):
market_root = os.path.join(dst_dir, ‘market1501’)
train_path = os.path.join(market_root, ‘bounding_box_train’)
query_path = os.path.join(market_root, ‘query’)
test_path = os.path.join(market_root, ‘bounding_box_test’)
if not os.path.exists(train_path):
os.makedirs(train_path)
if not os.path.exists(query_path):
os.makedirs(query_path)
if not os.path.exists(test_path):
os.makedirs(test_path)
if name == ‘main’:
make_market_dir(dst_dir=‘E:/reID’)
这样就创建出来我们需要的几个文件夹了

第二步 将market1501数据集抽取出来
import re
import os
import shutil
def extract_market(src_path, dst_dir):
img_names = os.listdir(src_path)
pattern = re.compile(r’([-\d]+)_c(\d)’)
pid_container = set()
for img_name in img_names:
if ‘.jpg’ not in img_name:
continue
print(img_name)
# pid: 每个人的标签编号 1
# _ : 摄像头号 2
pid, _ = map(int, pattern.search(img_name).groups())
# 去掉没用的图片
if pid == 0 or pid == -1:
continue
shutil.copy(os.path.join(src_path, img_name), os.path.join(dst_dir, img_name))
if name == ‘main’:
src_train_path = r’D:\data\market1501\bounding_box_train’
src_query_path = r’D:\data\market1501\query’
src_test_path = r’D:\data\market1501\bounding_box_test’
# 将整个market1501数据集作为训练集
dst_dir = r’E:\reID\market1501\bounding_box_train’
extract_market(src_train_path, dst_dir)
extract_market(src_query_path, dst_dir)
extract_market(src_test_path, dst_dir)
抽取的结果如图所示,现在一共有 29419 张图片, ID从0001到1501一共1501 个不同ID的行人。

第三步 将CUHK数据集抽取出来
具体介绍看这个:http://blog.fangchengjin.cn/reid-cuhk03.html
import glob
import re
import os.path as osp
import shutil
import re
import os
import shutil
def extract_cuhk03(src_path, dst_dir):
img_names = os.listdir(src_path)
pattern = re.compile(r’([-\d]+)c(\d)([\d]+)’)
pid_container = set()
for img_name in img_names:
if ‘.png’ not in img_name and ‘.jpg’ not in img_name:
continue
print(img_name)
# pid: 每个人的标签编号 1
# camid : 摄像头号 2
pid, camid, fname = map(int, pattern.search(img_name).groups())
# 这里注意需要加上前面的market1501数据集的最后一个ID 1501
# 在前面数据集的最后那个ID基础上继续往后排
pid += 1501
dst_img_name = str(pid).zfill(6) + ‘_c’ + str(camid) + ‘_CUHK’ + str(fname) + ‘.jpg’
shutil.copy(os.path.join(src_path, img_name), os.path.join(dst_dir, dst_img_name))
if name == ‘main’:
src_train_path = r’D:\data\cuhk03-np\detected\bounding_box_train’
src_query_path = r’D:\data\cuhk03-np\detected\query’
src_test_path = r’D:\data\cuhk03-np\detected\bounding_box_test’
dst_dir = r’E:\reID\market1501\bounding_box_train’
extract_cuhk03(src_train_path, dst_dir)
extract_cuhk03(src_query_path, dst_dir)
extract_cuhk03(src_test_path, dst_dir)
转换结果如图所示,CUHK03一共有 14097 张图片, ID从001502到002968一共1467个不同ID的行人。

第四步 将MSMT17数据集抽取出来
import glob
import re
import os.path as osp
import shutil
def msmt2market(dir_path, list_path, dst_dir, prev_pid):
with open(list_path, ‘r’) as txt:
lines = txt.readlines()
pid_container = set()
for img_idx, img_info in enumerate(lines):
img_path, pid = img_info.split(’ ‘)
pid = int(pid) + prev_pid + 1 # 2969 5121
camid = int(img_path.split(’_’)[2])
img_path = osp.join(dir_path, img_path)
name = img_path.split(’/’)[-1] # ‘0001_c2_f0046182.jpg’
Newdir = osp.join(dst_dir, str(pid).zfill(6) + ‘c’ + str(camid) + '’ + name) # 用字符串函数zfill 以0补全所需位数
shutil.copy(img_path, Newdir) # 复制一个文件到一个文件或一个目录
# check if pid starts from 0 and increments with 1
for idx, pid in enumerate(pid_container):
assert idx == pid, "See code comment for explanation"
if name == ‘main’:
dataset_dir = r’D:\data\MSMT17_V2’
train_dir = osp.join(dataset_dir, ‘mask_train_v2’)
test_dir = osp.join(dataset_dir, ‘mask_test_v2’)
list_train_path = osp.join(dataset_dir, ‘list_train.txt’)
list_val_path = osp.join(dataset_dir, ‘list_val.txt’)
list_query_path = osp.join(dataset_dir, ‘list_query.txt’)
list_gallery_path = osp.join(dataset_dir, ‘list_gallery.txt’)
dst_dir = r'E:\reID\market1501\bounding_box_train'
msmt2market(train_dir, list_train_path, dst_dir, 2968)
msmt2market(train_dir, list_val_path, dst_dir, 2968)
msmt2market(test_dir, list_query_path, dst_dir, 4009)
msmt2market(test_dir, list_gallery_path, dst_dir, 4009)
转换结果如图所示,MSMT17一共有 126441 张图片, ID从002969到007069一共1467个不同ID的行人。

到现在以及完成了除了duke以外的几个大型主流数据集的转换,duke数据集想留作测试,体现出模型的泛化能力。
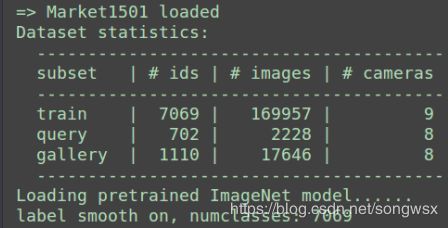
目前的统计结果如下图所示,训练集现在已经有将近17w的图片,ID一共有7069个。
第五步 将viper数据集抽取出来
import re
import os
import shutil
def extract_viper(src_path, dst_dir, camid=1):
img_names = os.listdir(src_path)
pattern = re.compile(r’([\d]+)_([\d]+)’)
pid_container = set()
for img_name in img_names:
if ‘.bmp’ not in img_name:
continue
print(img_name)
pid, fname = map(int, pattern.search(img_name).groups())
# 这里注意需要加上前面的数据集的最后一个ID 7069
# 由于viper数据集ID是从0开始,因此需要+1
pid += 7069 + 1
dst_img_name = str(pid).zfill(6) + ‘_c’ + str(camid) + ‘_viper’ + str(fname) + ‘.jpg’
shutil.copy(os.path.join(src_path, img_name), os.path.join(dst_dir, dst_img_name))
if name == ‘main’:
src_cam_a = r’D:\data\viper\cam_a’
src_cam_b = r’D:\data\viper\cam_b’
dst_dir = r’E:\reID\market1501\bounding_box_train’
extract_viper(src_cam_a, dst_dir, camid=1)
extract_viper(src_cam_b, dst_dir, camid=2)
转换后的viper数据集一共有1264张图片, ID从007070到007943一共1467个不同ID的行人。需要注意这里ID不是连续的,不过只要ID跟之前不重复即可。
第六步 将SenseReID数据集抽取出来
import re
import os
import shutil
def extract_SenseReID(src_path, dst_dir, fname):
img_names = os.listdir(src_path)
pattern = re.compile(r’([\d]+)_([\d]+)’)
pid_container = set()
for img_name in img_names:
if ‘.jpg’ not in img_name:
continue
print(img_name)
pid, camid = map(int, pattern.search(img_name).groups())
pid += 7943 + 1
dst_img_name = str(pid).zfill(6) + ‘_c’ + str(camid + 1) + ‘SenseReID’ + fname + ‘.jpg’
shutil.copy(os.path.join(src_path, img_name), os.path.join(dst_dir, dst_img_name))
if name == ‘main’:
src_cam_a = r’D:\data\SenseReID\test_gallery’
src_cam_b = r’D:\data\SenseReID\test_probe’
dst_dir = r’E:\reID\market1501\bounding_box_train’
extract_SenseReID(src_cam_a, dst_dir, 'gallery')
extract_SenseReID(src_cam_b, dst_dir, 'probe')转换后的SenseReID数据集一共有4428张图片, ID从007944到009661。
第七步 将prid数据集抽取出来
import re
import os
import shutil
def extract_prid(src_path, dst_dir, prevID, camid=1):
pattern = re.compile(r’person_([\d]+)’)
pid_container = set()
sub_dir_names = os.listdir(src_path) # ['person_0001', 'person_0002',...
for sub_dir_name in sub_dir_names: # 'person_0001'
img_names_all = os.listdir(os.path.join(src_path, sub_dir_name))
# 这里我就只取首尾两张,防止重复太多了
img_names = [img_names_all[0], img_names_all[-1]]
for img_name in img_names: # '0001.png'
if '.png' not in img_name:
continue
print(img_name)
# parent.split('\\')[-1] : person_0001
pid = int(pattern.search(sub_dir_name).group(1))
pid += prevID
dst_img_name = str(pid).zfill(6) + '_c' + str(camid) + '_prid' + img_name.replace('.png', '.jpg')
shutil.copy(os.path.join(src_path, sub_dir_name, img_name), os.path.join(dst_dir, dst_img_name))
if name == ‘main’:
src_cam_a = r’D:\data\prid2011\multi_shot\cam_a’
src_cam_b = r’D:\data\prid2011\multi_shot\cam_b’
dst_dir = r’E:\reID\market1501\bounding_box_train’
extract_prid(src_cam_a, dst_dir, 9661)
extract_prid(src_cam_b, dst_dir, 10046)
转换后的prid数据集一共有2268张图片, ID从009662到010795。
第八步 将ilids数据集抽取出来
import re
import os
import shutil
def extract_ilids(src_path, dst_dir, prevID, camid):
pattern = re.compile(r’person([\d]+)’)
pid_container = set()
sub_dir_names = os.listdir(src_path)
for sub_dir_name in sub_dir_names:
img_names = os.listdir(os.path.join(src_path, sub_dir_name))
for img_name in img_names:
if '.png' not in img_name:
continue
print(img_name)
pid = int(pattern.search(sub_dir_name).group(1))
pid += prevID
dst_img_name = str(pid).zfill(6) + '_c' + str(camid) + '_ilids' + '.jpg'
shutil.copy(os.path.join(src_path, sub_dir_name, img_name), os.path.join(dst_dir, dst_img_name))
if name == ‘main’:
src_cam_a = r’D:\data\ilids\i-LIDS-VID\images\cam1’
src_cam_b = r’D:\data\ilids\i-LIDS-VID\images\cam2’
dst_dir = r’E:\reID\market1501\bounding_box_train’
extract_ilids(src_cam_a, dst_dir, 10795, 1)
extract_ilids(src_cam_b, dst_dir, 10795, 2)
转换后的ilids数据集一共有600张图片, ID从010796到011114。
第九步 将grid数据集抽取出来
import re
import os
import shutil
def extract_grid(src_path, dst_dir, camid=1):
img_names = os.listdir(src_path)
pattern = re.compile(r’([\d]+)_’)
pid_container = set()
for img_name in img_names:
if ‘.jpeg’ not in img_name:
continue
print(img_name)
pid = int(pattern.search(img_name).group(1))
if pid == 0:
continue
pid += 11114
dst_img_name = str(pid).zfill(6) + ‘_c’ + str(camid) + ‘_grid’ + ‘.jpg’
shutil.copy(os.path.join(src_path, img_name), os.path.join(dst_dir, dst_img_name))
if name == ‘main’:
src_cam_a = r’D:\data\grid\probe’
src_cam_b = r’D:\data\grid\gallery’
dst_dir = r’E:\reID\market1501\bounding_box_train’
extract_grid(src_cam_a, dst_dir, camid=1)
extract_grid(src_cam_b, dst_dir, camid=2)
转换后的grid数据集一共有500张图片, ID从011115到011364
最终的数据集统计结果如下图所示,一共有将近十八万张图片和11103个不同ID的行人:

- 点赞 4
- 收藏
- 分享
-
- 文章举报


猜你喜欢
转载自
blog.csdn.net/songwsx/article/details/102987787