xxl-job执行器集群部署及路由策略实践
1.前言
建立多个执行器时,定时任务会不会受到影响。集群部署执行器,定时任务选定执行器后,任何一样由选定的执行器执行,如果执行器异常、忙碌,定时任务的路由策略不同的处理方式,下面就是实践的内容:
2.集群部署
- 搭建集群执行器
第一步:配置第一台执行器,在application.properties文件配置如下内容:项目端口serve.port=8082,执行器注册端口:xxl-job.executor.port=9999
# web port
server.port=8082
server.servlet.context-path=/xxl-job-executor-sample
# log config
logging.config=classpath:logback.xml
### xxl-job admin address list, such as "http://address" or "http://address01,http://address02"
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
### xxl-job executor address
xxl.job.executor.appname=xxl-job-executor-sample
xxl.job.executor.ip=
xxl.job.executor.port=9999
### xxl-job, access token
xxl.job.accessToken=
### xxl-job log path
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
### xxl-job log retention days
xxl.job.executor.logretentiondays=30
第二步:配置第二台执行器,在application.properties文件配置如下内容:项目端口serve.port=8083,执行器注册端口:xxl-job.executor.port=9998
#项目端口号
server.port=8083
#日志文件
logging.config=classpath:logback.xml
#调度中心部署跟地址:如调度中心集群部署存在多个地址则用逗号分隔。
#执行器将会使用该地址进行"执行器心跳注册"和"任务结果回调"。
xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin
#分别配置执行器的名称、ip地址、端口号
#注意:如果配置多个执行器时,防止端口冲突
xxl.job.executor.appname=xxl-job-executor-sample
xxl.job.executor.ip=127.0.0.1
xxl.job.executor.port=9998
xxl.job.accessToken=
#执行器运行日志文件存储的磁盘位置,需要对该路径拥有读写权限
xxl.job.executor.logpath=/data/applogs/xxl-job/jobhandler
#执行器Log文件定期清理功能,指定日志保存天数,日志文件过期自动删除。限制至少保持3天,否则功能不生效;
#-1表示永不删除
xxl.job.executor.logretentiondays=30
- 在调度任务中心添加执行器
启动调度任务中心xxl-job-admin工程,在执行器管理中添加执行器:

注意:注册方式为手动录入,机器地址为上面配置两个执行器的地址。
- 添加任务
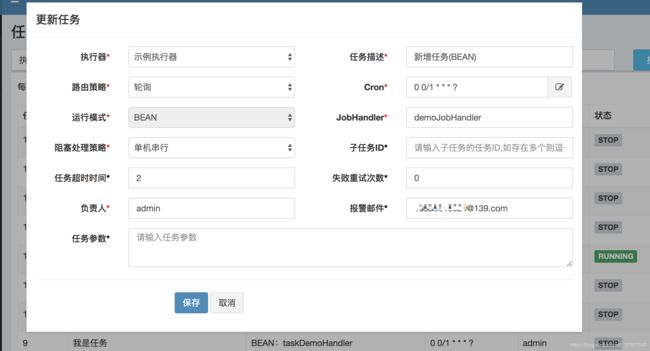
- 在执行器中编写定时任务并启动项目
第一台执行器任务类:
package com.xxl.job.executor.service.jobhandler;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.annotation.XxlJob;
import com.xxl.job.core.log.XxlJobLogger;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
@Component
public class SampleXxlJob {
private static Logger logger = LoggerFactory.getLogger(SampleXxlJob.class);
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("demoJobHandler")
public ReturnT demoJobHandler(String param) throws Exception {
XxlJobLogger.log("第一台执行器执行了!");
return ReturnT.SUCCESS;
}
}
第二台执行器任务类
package com.example.taskdemo.service.jobhandler;
import com.xxl.job.core.biz.model.ReturnT;
import com.xxl.job.core.handler.IJobHandler;
import com.xxl.job.core.handler.annotation.XxlJob;
import com.xxl.job.core.log.XxlJobLogger;
import org.springframework.stereotype.Component;
/**
* @Description 调度任务类
* @Date Created in 下午8:19 2020/2/22
* @Version 1.0
*/
@Component
public class TaskHandler extends IJobHandler {
@XxlJob("demoJobHandler")
@Override
public ReturnT execute(String param) throws Exception {
XxlJobLogger.log("第二台执行器执行");
return SUCCESS;
}
}
- 演示效果:
由于刚才新建时选择的路由策略是轮询的,所以调度中心随机调用其中一台。

 3.路由策略
3.路由策略
1.第一个:当选择该策略时,会选择执行器注册地址的第一台机器执行,如果第一台机器出现故障,则调度任务失败。
2.第二个:当选择该策略时,会选择执行器注册地址的第二台机器执行,如果第二台机器出现故障,则调度任务失败。
3.轮询:当选择该策略时,会按照执行器注册地址轮询分配任务,如果其中一台机器出现故障,调度任务失败,任务不会转移。
4.随机:当选择该策略时,会按照执行器注册地址随机分配任务,如果其中一台机器出现故障,调度任务失败,任务不会转移。
5.一致性HASH:当选择该策略时,每个任务按照Hash算法固定选择某一台机器。如果那台机器出现故障,调度任务失败,任务不会转移。
6.最不经常使用:当选择该策略时,会优先选择使用频率最低的那台机器,如果其中一台机器出现故障,调度任务失败,任务不会转移。(实践表明效果和轮询策略一致)
7.最近最久未使用:当选择该策略时,会优先选择最久未使用的机器,如果其中一台机器出现故障,调度任务失败,任务不会转移。(实践表明效果和轮询策略一致)
8.故障转移:当选择该策略时,按照顺序依次进行心跳检测,如果其中一台机器出现故障,则会转移到下一个执行器,若心跳检测成功,会选定为目标执行器并发起调度。
9.忙碌转移:当选择该策略时,按照顺序依次进行空闲检测,如果其中一台机器出现故障,则会转移到下一个执行器,若空闲检测成功,会选定为目标执行器并发起调度。
10.分片广播:当选择该策略时,广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务。如果其中一台机器出现故障,则该执行器执行失败,不会影响其他执行器。
4.阻塞策略
- 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;