CRAFT Objects from Images
《CRAFT Objects from Images》 2016年发表在CVPR上,对于目标检测问题,将网络结构进行了进一步的改进。
目标检测任务通常分为两个子任务:产生proposals以及将proposals分类。
在本文中,作者将两个子任务进一步细分,分别提高精度,以达到提高精确率的目的。
整体框图如下:
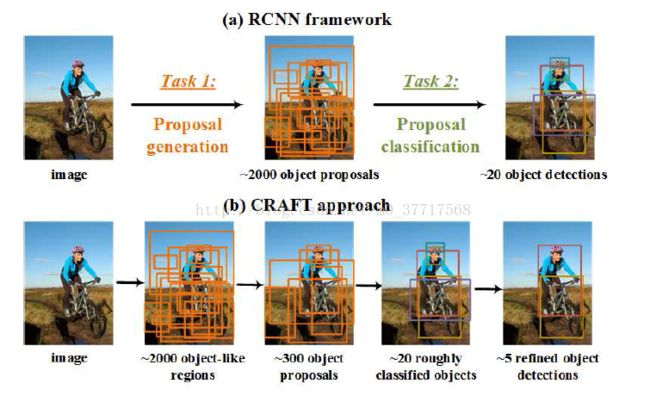
1. 级联的proposal生成结构
理想的proposal生成器应该产生尽量少的proposal,却能覆盖尽量多的目标实例。
由于pooling造成的分辨率损失,以及固定比例的滑动窗口,RPN在处理不同尺度不同比例的物体上仍有不足。
为了观察RPN的效果,作者基于VGG_M,使用PASCAL VOC 2007 train+val训练了RPN网络。在PASCAL VOC 2007 test上进行测试,每张图像产生300个proposals,IoU=0.5,整体的召回率达到94.87%。但在每一个类上的召回率大有不同:

其中召回率低于平均值的类别被highlight。
可以发现:1. object的比例不同、尺度不同的类别难检测(boat、bottle)
2. 外观复杂度较低、有遮挡的类别难检测(plant、tv、chair)
为了改善RPN提取的proposals质量,提出级联的结构,即RPN级联FRCN,用RPN的输出训练FRCN:

其中RPN提取一般的图案,如纹理。FRCN学到更加细致的图案。
分别训练RPN、FRCN网络。RPN网络训练后,每张训练图像上生成2000个初始proposals。用这些proposals训练FRCN网络。
训练时,positive和negative的设定与RPN相同:和任意groundTruth的IoU大于0.7视为positive;和所有groundTruth的IoU小于0.3视为negative。
测试时,RPN生成2000个初始proposals,输入到FRCN,通过合适的阈值抑制策略,可以获得小于300个proposals。这些proposals包含背景的信息更少了,而且不同来源的proposals可以整合输入,从而利用互补信息。
为什么不级联两个RPN网络?因为FRCN能够处理更难的分类问题。
2. 级联的object分类结构
分类任务需要特征能够提取到类间、类内的差异。
在Fast R-CNN中,通过softmax,分类器可以获得多类别的交叉熵损失。
多类别的交叉熵损失能够学习到丰富的类间差异,而在获取类内差异方面较弱。
Fast R-CNN的实验表明,最终检测中,错误分类是一个很大的问题。
Fast R-CNN舍弃了R-CNN中one-vs-rest SVM(训练时依次把某个类别的样本归为一类,其他剩余的样本归为另一类,这样k个类别的样本就构造出了k个SVM。分类时将未知样本分类为具有最大分类函数值的那类)。在本文中,重新应用这种形式。
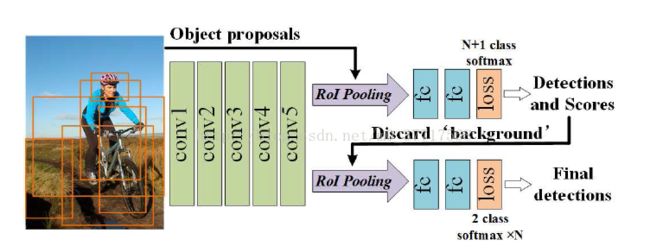
训练时,使用级联的proposals生成器产生的proposals训练FRCN-1结构。之后基于FRCN-1的输出(初步检测结果)训练FRCN-2结构。舍弃“背景”类。
FRCN-2的目标函数是N个的2类交叉熵之和,N为object类别数。
每个2类分类器仅依赖于分配有相应类标签的初始检测结果,positive和negative的判定标准同前。
实际上,大约每张图片只有20个初始检测结果应用于FRCN-2训练,数量相当有限。
为了更有效地训练FRCN-2以及检测,将FRCN-1和FRCN-2权值进行共享。即FRCN-2的卷积权重来自于FRCN-1,并在训练时保持不变。FRCN-2的全连接权重也来自于FRCN-1,它们将产生2N个分数以及4N回归边界框,由高斯分布初始化(?)。
测试时,输入300个proposals,FRCN-1产生大约20个初始检测,每一个都有N个初始得分(N类)。
接着再通过FRCN-2分类,输出的分数(N个类别)与初始分数(N类别)相乘,以获得用于检测的最终N个分数。
3. 实验
3.1 生成proposal的比较
此时不共享全图像的卷积特征。在ILSVRC数据集(200类)上。
为了应对一些小目标,加了两个额外的anchor尺度:64和32,并且将batch-size改为2张图像。

由实验结果可以看出,级联FRCN结构可以在合适的参数设置下得到更好的召回率,仅用300个proposals就可以得到优于SS的结果。
proposals在不同IoU、不同box数量设置下的召回率以及准确率比较:

通过平均准确率的比较可以看出,1)换成大的网络没有用(RPN_L)。
2)提出的级联网络结构能得到更高的准确率。
3)即使添加了额外的anchor尺度,RPN在大规模的检测任务上也不会十分有效。
3.2 object分类比较
首先比较训练FRCN_2时,不同训练策略的影响:

其中,“the same”表示无微调,参数同FRCN_1;“clf”表示微调额外的one-vs-rest 分类器的权重;“fc+clf”表示微调全连接层和分类器层;“conv+fc+clf”表示微调除了conv1的其它所有层。
由实验结果可以看出,1)简单的迭代两次FRCN网络可以通过迭代回归边界框的方式稍稍提高准确率。
2)共享卷积层权重,微调靠后的层能得到最好的准确率。
其次比较分类器不同策略的平均准确率:

由实验可以看出,提出的方法准确率最高。因为one-vs-rest只处理来自FRCN_1输出中的属于同一类object,更细化了。
3.3 object检测
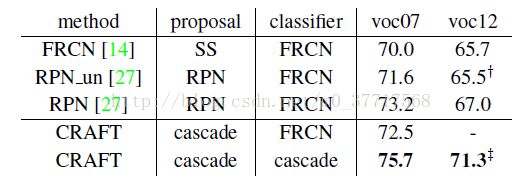
在PASCAL VOC 2007 & 2012数据集上:
在ILSVRC数据集上:

为进一步提高性能,proposal的生成添加一些其他操作:

其中,“Basic”指的是 3.1 生成proposal的比较 中的实验结果;“0.6NMS”代表了更严格的非最大值抑制策略,IoU阈值为0.6;“rescore”指利用级联结构的两次得分重排proposal;“+DeepBox”和“+SS”指的是将DeepBox和SS产生的proposals与RPN的proposal进行融合,再输入到FRCN结构中。数字代表召回率。
由实验结果可以看出,每一个策略都能小幅度地提高召回率。结合DeepBox的方法召回率最优。
最后是CRAFT在ILSVRC detection val2上的检测准确率以及效果展示:

