SQL语句整理二
文章目录
- SqlServer
- DATEDIFF() 函数返回两个日期之间的时间:
- 将表数据改造成insert语句:
- Mysql
- 分组之前进行排序:
- 查询媒体名称为"小强日报"的数据量:
- 内连接:
- 去重:
- beauty_article_view视图:
- 创建表:
- 日期和字符相互转换:
- 开窗函数:
- 需要注意的点:
- Hive
- 创建数据库:
- 使用数据库:
- 重命名表名:
- 建表时判断该表是否存在:
查看版本号:
mysql数据库: select version()
oracle数据库: select * from v$instance
sqlserver数据库: SELECT @@VERSION
SqlServer
DATEDIFF() 函数返回两个日期之间的时间:
SELECT DATEDIFF(day,'2008-12-29','2008-12-30') AS DiffDate
结果:1
语法:
DATEDIFF(datepart,startdate,enddate)
startdate 和 enddate 参数是合法的日期表达式。
datepart 参数可以是下列的值:
| datepart | 缩写 |
|---|---|
| 年 | yy, yyyy |
| 季度 | qq, q |
| 月 | mm, m |
| 年中的日 | dy, y |
| 日 | dd, d |
| 周 | wk, ww |
| 星期 | dw, w |
| 小时 | hh |
| 分钟 | mi, n |
| 秒 | ss, s |
| 毫秒 | ms |
| 微妙 | mcs |
| 纳秒 | ns |
将表数据改造成insert语句:
方法一:
select
'INSERT INTO t_jczc_cbqktj(id,tjrq,sjlx,xzqbm,xzqmc,sybxfhj,sybxfjx,sybxfzdts,sybxffjx,sybxfqt) VALUES('+cast(id as varchar)+','''+tjrq+''','''+sjlx+''','''+xzqbm+''','''+xzqmc+''','''+sybxfhj+''','''+sybxfjx+''','''+sybxfzdts+''','''+sybxffjx+''','''+sybxfqt+''');'
from
[dbo].[zb_xssybxfry_xzq];
运行结果:
INSERT INTO t_jczc_cbqktj(id,tjrq,sjlx,xzqbm,xzqmc,sybxfhj,sybxfjx,sybxfzdts,sybxffjx,sybxfqt) VALUES(1081,'201907','1a','110101','东城区','0','0','0','0','0');
INSERT INTO t_jczc_cbqktj(id,tjrq,sjlx,xzqbm,xzqmc,sybxfhj,sybxfjx,sybxfzdts,sybxffjx,sybxfqt) VALUES(1082,'201907','1a','110102','西城区','0','0','0','0','0');

备注:
(1).经测试,该用法在SQLserver上可以,在gaussDb上不行
(2).这张表id字段为bigint类型,其他字段都为varchar类型,用+号拼接的时候会要求所有字段的数据类型一致,不一致的话它会自动强转
(3).两个单引号表示一个引号,如果用一个引号的话会导致成多列而不是一列

方法二:
select
concat('INSERT INTO t_jczc_cbqktj(id,tjrq,sjlx,xzqbm,xzqmc,sybxfhj,sybxfjx,sybxfzdts,sybxffjx,sybxfqt) VALUES(',id,',''',tjrq,''',''',sjlx,''',''',xzqbm,''',''',xzqmc,''',''',sybxfhj,''',''',sybxfjx,''',''',sybxfzdts,''',''',sybxffjx,''',''',sybxfqt,''');')
from
[dbo].[zb_xssybxfry_xzq];
备注:
(1).经测试,该用法在SQLserver上可以,在gaussDb上也适用
Mysql
分组之前进行排序:
SELECT * FROM(SELECT * FROM biz_messageboard ORDER BY CREATETIME DESC) a GROUP BY a.USERID;
select * from goonie_article_view where id%2=1 and id < 3094578 ORDER BY id DESC limit 50
查询媒体名称为"小强日报"的数据量:
SELECT COUNT(*) FROM goonie_article_view WHERE SUBSTRING_INDEX(`goonie_article_view`.`mediaNameZh`,'-',1) = "小强日报";
SELECT * FROM beauty_article_view WHERE SUBSTRING_INDEX(`beauty_article_view`.`mediaNameZh`,'-',-1) = "旅游";
SELECT * FROM goonie_article_view WHERE author LIKE "张%";
SELECT COUNT(*) FROM goonie_article_view WHERE pubdate > "2018-05-09 18:00:00";
SELECT * FROM beauty_article_view WHERE codename='礼仪' AND id BETWEEN 1216 AND 1318;
SELECT * FROM beauty_article_view WHERE codename='语录' OR codename='礼仪' AND id < 24658 ORDER BY id DESC LIMIT 50;
内连接:
SELECT COUNT(*) FROM goonie_article_view w INNER JOIN gooniewechat_key t ON w.`creator`=t.`weixin_name` WHERE w.`gather_time`>="2019-01-29";
去重:
SELECT COUNT(DISTINCT(codename)) FROM beauty_article_view;
SELECT DISTINCT(codename) FROM beauty_article_view;
UPDATE afacebooktoken SET token='EAACEdEose0' where id=1;
DELETE FROM afacebooktoken WHERE id=1;
INSERT INTO afacebooktoken VALUES(1,'EAAL7AMi5Z');
beauty_article_view视图:
CREATE ALGORITHM=UNDEFINED DEFINER=`woman`@`%` SQL SECURITY DEFINER VIEW `beauty1_article_view` AS
select
`a`.`id` AS `id`,
`a`.`creator` AS `author`,
`a`.`publish_time` AS `pubdate`,
`a`.`site_code` AS `media_level`,
`a`.`source` AS `trans_from_m`,
`a`.`title` AS `titleZh`,
`a`.`depth` AS `depth`,
`a`.`location` AS `page_place_src`,
`a`.`url` AS `url`,
`a`.`content_finger` AS `finger`,
`a`.`url_hash` AS `url_hash`,
`d`.`content` AS `textZh`,
`d`.`summary` AS `abstractZh`,
`d`.`keywords` AS `keywordsZh`,
`e`.`description` AS `codename`,
`a`.`detriment` AS `detriment`,
#`c`.`name` AS `mediaNameZh`,
`a`.`gather_time` AS `gather_time`
from ((`gooniearticle` `a`
join `gooniearticledetailed` `d`)
join `goonienewssort` `e`)
where (`a`.`id` = `d`.`pid`)
and (`d`.`infoid` = `e`.`id`)
order by `a`.`id`
创建表:
CREATE TABLE `biz_reply` (
`id` BIGINT(64) NOT NULL AUTO_INCREMENT,
`userid` VARCHAR(255) DEFAULT NULL COMMENT '用户id',
`shopid` VARCHAR(200) DEFAULT '' COMMENT '商家id',
`recontent` VARCHAR(1000) DEFAULT '' COMMENT '留言内容',
`createId` VARCHAR(32) DEFAULT NULL COMMENT '创建人',
`createTime` DATETIME DEFAULT NULL COMMENT '创建时间',
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
CHARSET=utf8mb4能存储Emoji表情
日期和字符相互转换:
date_format(date,'%Y-%m-%d') -------------->oracle中的to_char();
str_to_date(date,'%Y-%m-%d') -------------->oracle中的to_date();
%Y:代表4位的年份
%y:代表2为的年份
%m:代表月, 格式为(01……12)
%c:代表月, 格式为(1……12)
%d:代表月份中的天数,格式为(00……31)
%e:代表月份中的天数, 格式为(0……31)
%H:代表小时,格式为(00……23)
%k:代表 小时,格式为(0……23)
%h: 代表小时,格式为(01……12)
%I: 代表小时,格式为(01……12)
%l :代表小时,格式为(1……12)
%i: 代表分钟, 格式为(00……59)
%r:代表 时间,格式为12 小时(hh:mm:ss [AP]M)
%T:代表 时间,格式为24 小时(hh:mm:ss)
%S:代表 秒,格式为(00……59)
%s:代表 秒,格式为(00……59)
SELECT DATE_FORMAT(20130111191640,'%Y-%m-%d %H:%i:%s')
DATE_FORMAT(20130111191640,'%Y-%m-%d %H:%i:%s')
开窗函数:
说明:开窗函数与聚合函数一样,也是对行集组进行聚合计算,但是它不像普通聚合函数那样每组只返回一个值,开窗函数可以为每组返回多个值,因为开窗函数所执行聚合计算的行集组是窗口。
语法:
主要是over( PARTITION BY (根据某条件分组,形成一个小组)….ORDER BY(再组内进行排序) …. )
常用函数:
参考:https://www.bbsmax.com/A/q4zVkPLxJK/
1、row_number() over(partition by … order by …)
2、rank() over(partition by … order by …)
3、dense_rank() over(partition by … order by …)
rank(): 跳跃排序,如果有两个第一级时,接下来就是第三级。
dense_rank(): 连续排序,如果有两个第一级时,接下来仍然是第二级。
4、count() over(partition by … order by …)
5、max() over(partition by … order by …)
6、min() over(partition by … order by …)
7、sum() over(partition by … order by …)
8、avg() over(partition by … order by …)
9、first_value() over(partition by … order by …)
10、last_value() over(partition by … order by …)
11、lag() over(partition by … order by …)
12、lead() over(partition by … order by …)
lag 和lead 可以 获取结果集中,按一定排序所排列的当前行的上下相邻若干offset 的某个行的某个列(不用结果集的自关联);
lag ,lead 分别是向前,向后;
lag 和lead 有三个参数,第一个参数是列名,第二个参数是偏移的offset,第三个参数是 超出记录窗口时的默认值)
但是:mysql 8.0版本以下并不支持,只能通过变通的方法实现相同的功能
(1)实现自增:
SELECT
@num := @num+1 score_ranking,
id
FROM
`user`, (SELECT @num := 0) t1
ORDER BY
id DESC;
(2)实现rank():
参考:https://blog.csdn.net/justry_deng/article/details/80597916
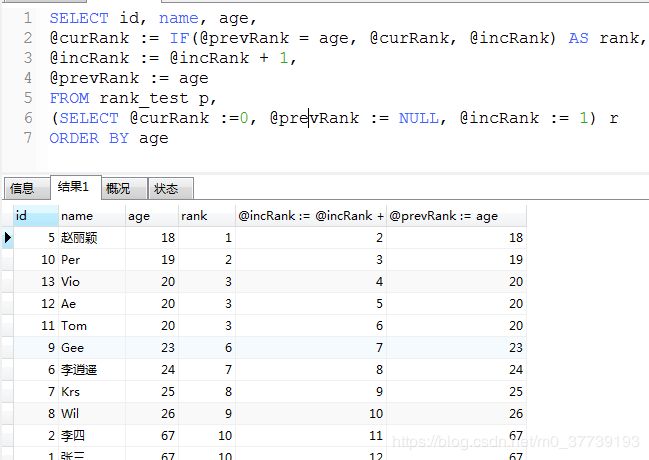
(3)8.0版本以上实现rank():rank()、row_number()、dense_rank()
参考:https://blog.csdn.net/sqsltr/article/details/94408487
create table students(
id int(4) auto_increment primary key,
name varchar(50) not null,
score int(4) not null
);
insert into students(name,score) values('curry', 100),
('klay', 99),
('KD', 100),
('green', 90),
('James', 99),
('AD', 96);
select id, name, rank() over(order by score desc) as r from students;
select id, name, DENSE_RANK() OVER(order by score desc) as dense_r from students;
select id, name, row_number() OVER(order by score desc) as row_r from students;
需要注意的点:
1.在做多表查询,或者查询的时候产生新的表的时候会出现这个错误:Every derived table must have its own alias(每一个派生出来的表都必须有一个自己的别名)。
2.同级生成的别名字段不可以使用,只能嵌套使用(这样感觉增加了语句量,在Gauss是可以做到的)
mysql:
SELECT
a.hehe heheda,
heheda*12
FROM
haha a;
报错:Unknown column 'heheda' in 'field list'
Gauss:
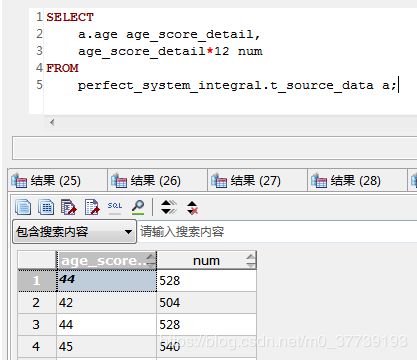
Hive
创建数据库:
create database jiuyebu;
使用数据库:
use jiuyebu;
重命名表名:
ALTER TABLE FaRen_JiChuShuJu141 RENAME TO FaRen_JiChuShuJu;
建表时判断该表是否存在:
create table if not exists zb_xsgsbqy_xzq。。。