疫情结束,供新同事学习(row_number,rank,dense_rank,ntile) 常用函数排名用法
疫情结束了,长沙要崛起,中部城市,独领风骚,还看长沙。
在使用排名函数的时候需要注意以下三点:
1、排名函数必须有 OVER 子句。
2、排名函数必须有包含 ORDER BY 的 OVER 子句。
3、分组内从1开始排序。
介绍SQL中4个很有意思的函数,我称它的行标函数,它们是row_number,rank,dense_rank和ntile,下面分别进行介绍。
一 row_number:它为数据表加一个叫“行标示”的列,它在数据表中是连续的,我们必须按着某个顺序把表排序之后,才能使用row_number,看下列例子:
SELECT row_number() OVER ( ORDER BY SalePrice ) AS row ,
*
FROM Product结果表被加上了行号:

这个row_number在平常用的最多,它可以用来实现数据表的分页功能,看下面代码
SELECT *
FROM ( SELECT row_number() OVER ( ORDER BY SalePrice ) AS row ,
*
FROM Product
) AS Result
WHERE Result.row BETWEEN 1 AND 2
它的含义是从第一条记录开始,取出2条记录,如果你想一页显示10条记录,可以使用BETWEEN 1 AND 10,如果想得到第二次的10条,那条件就变成BETWEEN 11 AND 20
二 rank:类型于row_number,不同之处在于,它会对order by 的字段进行处理,如果这个字段值相同,那么,行号保持不变,如代码:
SELECT RANK() OVER ( ORDER BY SalePrice ) AS row ,
SalePrice ,
ProductID ,
ProductName
FROM Product结果如下:
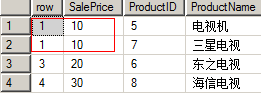
三 dense_rank:与rank类型,不同之处在于行号是否保留一个位置,rank对保留这个位置,即上面图中,row的值由1直接变为3,因为它的1出现了两次,所以为2保留了一个位置,而dense_rank不会保留2这个位置,即实现的行号2其实是排在了第3位,如代码:
SELECT DENSE_RANK() OVER ( ORDER BY SalePrice ) AS row ,
SalePrice ,
ProductID ,
ProductName
FROM Product结果如下:

四 ntile:为装桶操作(此函数很少用,基本用不上,干脆弃之),
ntile(桶数)它在运行之前,先确定产生的桶数,然后根据桶数去生成行标,如代码:
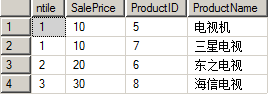
SELECT NTILE(1) OVER ( ORDER BY SalePrice ) AS ntile ,
SalePrice ,
ProductID ,
ProductName
FROM Product结果如下:
如果设为NTILE(3),那结果就为:
当我们面对一个复杂的问题时,考验的不是你是否能解决,而是你采取哪种方式去解决以及代码的性能问题。
ntile函数可以对序号进行分组处理,将有序分区中的行分发到指定数目的组中。 各个组有编号,编号从一开始。 对于每一个行,ntile 将返回此行所属的组的编号。这就相当于将查询出来的记录集放到指定长度的数组中,每一个数组元素存放一定数量的记录。ntile函数为每条记录生成的序号就是这条记录所有的数组元素的索引(从1开始)。也可以将每一个分配记录的数组元素称为“桶”。ntile函数有一个参数,用来指定桶数。下面的SQL语句使用ntile函数对Order表进行了装桶处理:
select NTILE(4) OVER(order by [SubTime] desc) as ntile,* from [Order]
查询结果如下图所示:
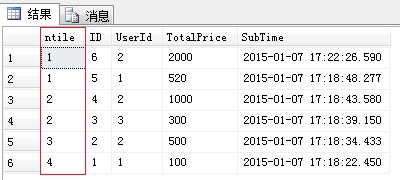
Order表的总记录数是6条,而上面的Sql语句ntile函数指定的组数是4,那么Sql Server2005是怎么来决定每一组应该分多少条记录呢?这里我们就需要了解ntile函数的分组依据(约定)。
ntile函数的分组依据(约定):
1、每组的记录数不能大于它上一组的记录数,即编号小的桶放的记录数不能小于编号大的桶。也就是说,第1组中的记录数只能大于等于第2组及以后各组中的记录数。
2、所有组中的记录数要么都相同,要么从某一个记录较少的组(命名为X)开始后面所有组的记录数都与该组(X组)的记录数相同。也就是说,如果有个组,前三组的记录数都是9,而第四组的记录数是8,那么第五组和第六组的记录数也必须是8。
这里对约定2进行详细说明一下,以便于更好的理解。
首先系统会去检查能不能对所有满足条件的记录进行平均分组,若能则直接平均分配就完成分组了;若不能,则会先分出一个组,这个组分多少条记录呢?就是 (总记录数/总组数)+1 条,之所以分配 (总记录数/总组数)+1 条是因为当不能进行平均分组时,总记录数%总组数肯定是有余的,又因为分组约定1,所以先分出去的组需要+1条。
分完之后系统会继续去比较余下的记录数和未分配的组数能不能进行平均分配,若能,则平均分配余下的记录;若不能,则再分出去一组,这个组的记录数也是(总记录数/总组数)+1条。
然后系统继续去比较余下的记录数和未分配的组数能不能进行平均分配,若能,则平均分配余下的记录;若还是不能,则再分配出去一组,继续比较余下的......这样一直进行下去,直至分组完成。
举个例子,将51条记录分配成5组,51%5==1不能平均分配,则先分出去一组(51/5)+1=11条记录,然后比较余下的 51-11=40 条记录能否平均分配给未分配的4组,能平均分配,则剩下的4组,每组各40/4=10 条记录,分配完成,分配结果为:11,10,10,10,10,我开始就错误的以为他会分配成 11,11,11,11,7。
根据上面的两个约定,可以得出如下的算法:

//mod表示取余,div表示取整.
if(记录总数 mod 桶数==0)
{
recordCount=记录总数 div 桶数;
//将每桶的记录数都设为recordCount.
}
else
{
recordCount1=记录总数 div 桶数+1;
int n=1;//n表示桶中记录数为recordCount1的最大桶数.
m=recordCount1*n;
while(((记录总数-m) mod (桶数- n)) !=0)
{
n++;
m=recordCount1*n;
}
recordCount2=(记录总数-m) div (桶数-n);
//将前n个桶的记录数设为recordCount1.
//将n+1个至后面所有桶的记录数设为recordCount2.
}
 NTILE()函数算法实现代码
NTILE()函数算法实现代码
根据上面的算法,如果总记录数为59,总组数为5,则 n=4 , recordCount1=12 , recordCount2=11,分组结果为 :12,12,12,12,11。
如果总记录数为53,总组数为5,则 n=3 , recordCount1=11 , recordCount2=10,分组结果为:11,11,11,10,10。
就拿上面的例子来说,总记录数为6,总组数为4,通过算法得到 n=2 , recordCount1=2 , recordCount2=1,分组结果为:2,2,1,1。
select ntile,COUNT([ID]) recordCount from
(
select NTILE(4) OVER(order by [SubTime] desc) as ntile,* from [Order]
) as t
group by t.ntile
运行Sql,分组结果如图:
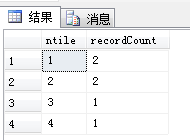
比对算法与Sql Server的分组结果是一致的,说明算法没错。:)