吴恩达深度学习第一课笔记——神经网络和深度学习
文章目录
- 第一周:深度学习引言(Introduction to Deep Learning)
- 1.2 什么是神经网络?(What is a Neural Network)
- 1.4 为什么深度学习会兴起?(Why is Deep Learning taking off?)
- “Scale drives deep learning progress”
- 1.5 总结
- 第二周:神经网络的编程基础(Basics of Neural Network programming)
- 2.1 二分类(Binary Classification)
- 2.2 逻辑回归(Logistic Regression)
- 2.3 逻辑回归的代价函数(Logistic Regression Cost Function)
- 2.4 梯度下降法(Gradient Descent)
- 2.5 导数(Derivatives)
- 2.7 计算图(Computation Graph)
- 2.9 逻辑回归中的梯度下降(Logistic Regression Gradient Descent)
- 2.10 m 个样本的梯度下降(Gradient Descent on m Examples)
- 2.11 向量化(Vectorization)
- 2.12 向量化的更多例子(More Examples of Vectorization)
- 2.13 向量化逻辑回归(Vectorizing Logistic Regression)
- 2.14 向量化 logistic 回归的梯度输出(Vectorizing Logistic Regression's Gradient)
- 2.15 Python 中的广播(Broadcasting in Python)
- 2.16 关于 python _ numpy 向量的说明(A note on python or numpy vectors)
- 2.18 logistic 损失函数的解释(Explanation of logistic regression cost function)
- 单个样本
- m 个样本
- 2.19 总结
- 第三周:浅层神经网络(Shallow neural networks)
- 3.1 神经网络概述(Neural Network Overview)
- 3.2 神经网络的表示(Neural Network Representation)
- 3.3 计算一个神经网络的输出(Computing a Neural Network's output)
- 3.4 多样本向量化(Vectorizing across multiple examples)
- 3.5 向量化实现的解释(Justification for vectorized implementation)
- 3.6 激活函数(Activation functions)
- 3.7 为什么需要非线性激活函数?(why need a nonlinear activation function?)
- 3.8 激活函数的导数(Derivatives of activation functions)
- 3.9 神经网络的梯度下降(Gradient descent for neural networks)
- 3.11 随机初始化(Random+Initialization)
- 3.12 总结
- 第四周:深层神经网络(Deep Neural Networks)
- 4.1 深层神经网络(Deep L-layer neural network)
- 4.2 前向传播和反向传播(Forward and backward propagation)
- 前向传播
- 反向传播
- 4.4 核对矩阵的维数(Getting your matrix dimensions right)
- 4.5 为什么使用深层表示?(Why deep representations?)
- 提取特征复杂度
- 减少神经元个数以减少计算量
- 4.6 搭建神经网络块(Building blocks of deep neural networks)
- 4.7 参数VS超参数(Parameters vs Hyperparameters)
- 4.8 深度学习和大脑的关联性(What does this have to do with the brain?)
- 4.9 总结
第一周:深度学习引言(Introduction to Deep Learning)
1.2 什么是神经网络?(What is a Neural Network)
我们常常用深度学习这个术语来指训练神经网络的过程。有时它指的是特别大规模的神经网络训练。
神经网络就是多个神经元映射函数叠加形成的一个整体的映射。通过输入 x 即可得到输出 y
值得注意的是神经网络给予了足够多的关于 x 和 y 的数据,给予了足够的训练样本有关和。神经网络非常擅长计算从 x 到 y 的精准映射函数。
1.4 为什么深度学习会兴起?(Why is Deep Learning taking off?)
“Scale drives deep learning progress”
数据量和计算能力提升巨大
传统机器学习算法性能一开始在增加更多数据时会上升,但是一段变化后它的性能就会像一个高原一样,并且它们不知道如何处理规模巨大的数据。

神经网络随着规模和数据量的增大效果越来越好。
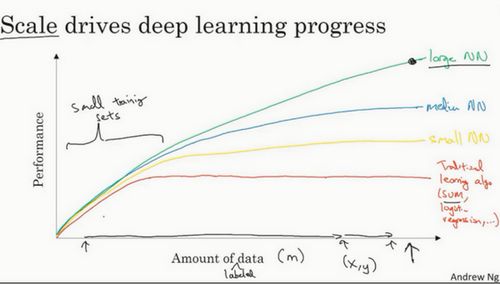
数据量少的时候看特征工程和算法处理,数据量大了神经网络的优势就体现出来了,传统算法对大数据量没有那么依赖,效果提升不明显。
如今最可靠的方法来在神经网络上获得更好的性能,往往就是要么训练一个更大的神经网络,要么投入更多的数据
在数据量小的时候,效果会取决于你的特征工程能力,那将决定最终的性能。在这个图形区域的左边,各种算法之间的优先级并不是定义的很明确,最终的性能更多的是取决于你在用工程选择特征方面的能力以及算法处理方面的一些细节,只是在某些大数据规模非常庞大的训练集,也就是在右边这个 m 会非常的大时,我们能更加持续地看到更大的由神经网络控制的其它方法。
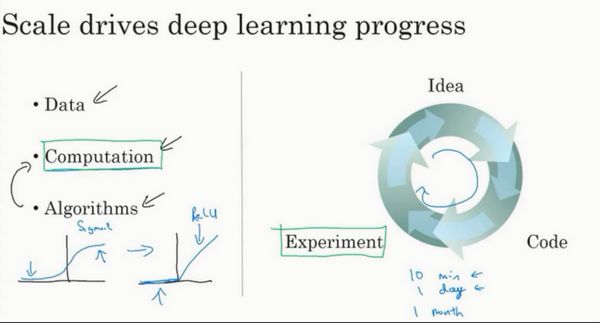
算法创新提升速度
神经网络方面的一个巨大突破是从 sigmoid 函数转换到一个 ReLU 函数。**sigmoid **函数最左边的梯度会接近零,所以学习的速度会变得非常缓慢,因为当你实现梯度下降以及梯度接近零的时候,参数会更新的很慢。ReLU 它的梯度对于所有输入的负值斜率都是 0,仅仅通过将 Sigmod 函数转换成 ReLU 函数,便能够使得一个叫做梯度下降(gradient descent)的算法运行的更快,这就是一个或许相对比较简单的算法创新的例子

计算能力的提升(GPU)和算法的改进让验证想法的时间缩短,对于提升效率意义重大,也促进深度学习更快发展
1.5 总结
本节课的内容比较简单,主要对深度学习进行了简要概述。首先,我们使用房价预测的例子来建立最简单的但个神经元组成的神经网络模型。然后,我们将例子复杂化,建立标准的神经网络模型结构。接着,我们从监督式学习入手,介绍了不同的神经网络类型,包括 Standard NN,CNN 和 RNN。不同的神经网络模型适合处理不同类型的问题。对数据集本身来说,分为 Structured Data 和 Unstructured Data。近些年来,深度学习对 Unstructured Data 的处理能力大大提高,例如图像处理、语音识别和语言翻译等。最后,我们用一张对比图片解释了深度学习现在飞速发展、功能强大的原因。归纳其原因包含三点:Data,Computation和Algorithms。
第二周:神经网络的编程基础(Basics of Neural Network programming)
2.1 二分类(Binary Classification)
在神经网络的计算中,通常先有一个叫做前向暂停(forward pause)或叫做前向传播(foward propagation)的步骤,接着有一个叫做反向暂停(backward pause) 或叫做反向传播**(backward propagation**)的步骤。
2.2 逻辑回归(Logistic Regression)
y ^ = w T + b \hat y=w^{T}+b y^=wT+b
σ ( z ) = 1 1 + e − z \sigma (z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1
线性回归加 sigmoid 函数作非线性变换,得到 0~1 之间的概率
2.3 逻辑回归的代价函数(Logistic Regression Cost Function)
单个代价函数 L ( y ^ , y ) = − y l o g ( y ^ ) − ( 1 − y ) l o g ( 1 − y ^ ) L(\hat y,y)=-ylog(\hat y)-(1-y)log(1-\hat y) L(y^,y)=−ylog(y^)−(1−y)log(1−y^)
整体代价函数 J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) = 1 m ∑ i = 1 m ( − y ( i ) l o g y ^ ( i ) − ( 1 − y ( i ) l o g ( 1 − y ^ ( i ) ) ) J(w,b)=\frac{1}{m}\sum_{i=1}^{m}L(\hat y^{(i)},y^{(i)})=\frac {1}{m}\sum_{i=1}^{m}(-y^{(i)}log\hat y^{(i)}-(1-y^{(i)}log(1-\hat y^{(i)})) J(w,b)=m1∑i=1mL(y^(i),y(i))=m1∑i=1m(−y(i)logy^(i)−(1−y(i)log(1−y^(i)))
2.4 梯度下降法(Gradient Descent)
找到损失函数的全局最小值(或接近最小值)

对应与对每个参数求偏导得到最优解

w = w − α ∂ J ( w , b ) ∂ w w=w-\alpha \frac{\partial J(w,b)}{\partial w} w=w−α∂w∂J(w,b)
b = b − α ∂ J ( w , b ) ∂ b b=b-\alpha \frac{\partial J(w,b)}{\partial b} b=b−α∂b∂J(w,b)
α \alpha α 为学习率
2.5 导数(Derivatives)
第一点,导数就是斜率,而函数的斜率,在不同的点是不同的。
第二点,如果你想知道一个函数的导数,你可参考你的微积分课本或者维基百科,然后你应该就能找到这些函数的导数公式。
2.7 计算图(Computation Graph)
前向过程计算输出,反向过程计算梯度
可以说,一个神经网络的计算,都是按照前向或反向传播过程组织的。首先我们计算出一个新的网络的输出(前向过程),紧接着进行一个反向传输操作。后者我们用来计算出对应的梯度或导数。计算图解释了为什么我们用这种方式组织这些计算过程。
2.9 逻辑回归中的梯度下降(Logistic Regression Gradient Descent)
前向传播

反向传播

2.10 m 个样本的梯度下降(Gradient Descent on m Examples)
计算流程
J=0;dw1=0;dw2=0;db=0;
for i = 1 to m
z(i) = wx(i)+b;
a(i) = sigmoid(z(i));
J += -[y(i)log(a(i))+(1-y(i))log(1-a(i));
dz(i) = a(i)-y(i);
dw1 += x1(i)dz(i);
dw2 += x2(i)dz(i);
db += dz(i);
J/= m;
dw1/= m;
dw2/= m;
db/= m;
w=w-alpha*dw
b=b-alpha*db
这种计算中有两个缺点,也就是说应用此方法在逻辑回归上你需要编写两个 for 循环。第一个 for 循环是 1~m 样本数量的循环,第二个 for 循环是 x1~xn 特征数量的循环。
当你应用深度学习算法,你会发现在代码中显式地使用 for 循环使你的算法很低效。所以这里有一些叫做向量化技术,它可以允许你的代码摆脱这些显式的 for 循环。
2.11 向量化(Vectorization)
# for 循环方法
z=0
for i in range(n_x)
z+=w[i]*x[i]
z+=b
# 向量化方法
z=np.dot(w,x)+b
CPU 和 GPU 都有并行化的指令,他们有时候会叫做 SIMD 指令,这个代表了一个单独指令多维数据,这个的基础意义是,如果你使用了 built-in 函数,像 np.function 或者并不要求你实现循环的函数,它可以让 python 的充分利用并行化计算,这是事实在 GPU 和 CPU 上面计算,GPU 更加擅长 SIMD 计算,但是 CPU 事实上也不是太差,可能没有 GPU 那么擅长吧。接下来的视频中,你将看到向量化怎么能够加速你的代码,经验法则是,无论什么时候,避免使用明确的 for 循环。
2.12 向量化的更多例子(More Examples of Vectorization)
虽然有时写循环(loop)是不可避免的,但是我们可以使用比如 numpy 的内置函数或者其他办法去计算。当你这样使用后,程序效率总是快于循环(loop)。
- 矩阵乘法时,np.dot() 好于两层 for 循环

- 善用 numpy 函数。当你想写循环时候,检查numpy是否存在类似的内置函数,从而避免使用循环(loop)方式。
np.exp()、np.log()、np.abs()、np.maximum()
通过 numpy 去掉一层 for 循环

2.13 向量化逻辑回归(Vectorizing Logistic Regression)
前向传播的计算,用 numpy 函数向量化计算替代一个 for 循环
Z = np.dot(w.T,X) + b
2.14 向量化 logistic 回归的梯度输出(Vectorizing Logistic Regression’s Gradient)
反向传播计算梯度,用矩阵运算替代另一个 for 数量循环
Z = w T X + b = n p . d o t ( w . T , X ) + b Z=w^{T}X+b=np.dot(w.T, X)+b Z=wTX+b=np.dot(w.T,X)+b
A = σ ( Z ) A=\sigma (Z) A=σ(Z)
d Z = A − Y dZ=A-Y dZ=A−Y
d w = 1 m ∗ X ∗ d z T dw=\frac{1}{m}*X*dz^{T} dw=m1∗X∗dzT
z 转置后才能和 X 相乘得到 dw
d b = 1 m ∗ n p . s u m ( d Z ) db=\frac{1}{m}*np.sum(dZ) db=m1∗np.sum(dZ)
更新参数
w = w − α ∗ d w w=w-\alpha*dw w=w−α∗dw
b = b − α ∗ d b b=b-\alpha*db b=b−α∗db
2.15 Python 中的广播(Broadcasting in Python)
numpy 广播机制
如果两个数组的维度其中一个维度相同,另一个维度有 1,即可进行广播
矩阵 A m , n A_{m,n} Am,n 和矩阵 B 1 , n B_{1,n} B1,n 进行四则运算,(m, n)和(1, n)可以广播, B 1 , n B_{1,n} B1,n 广播成为 B m , n B_{m,n} Bm,n
矩阵 A m , n A_{m,n} Am,n 和矩阵 B m , 1 B_{m,1} Bm,1 进行四则运算,(m, n)和(m, 1)可以广播, B m , 1 B_{m,1} Bm,1 广播成为 B m , n B_{m,n} Bm,n
2.16 关于 python _ numpy 向量的说明(A note on python or numpy vectors)
Python 广播功能既是优点也是缺点,通过技巧规避 bug
- 编写神经网络时,不要在它的 shape 是 ( n , ) (n,) (n,)或者一维数组时使用数据结构
a = np.random.randn(5, 1) 而不是 a = np.random.randn(5)
如果你每次创建一个数组,你都得让它成为一个列向量,产生一个向量或者你让它成为一个行向量,那么你的向量的行为可能会更容易被理解。
- 使用 assert 语句
assert(a.shape == (5, 1))
- 使用 reshape 确保维度正确
2.18 logistic 损失函数的解释(Explanation of logistic regression cost function)
为什么要用那个损失函数?因为选用的损失函数最优化效果等价于原始形式最优化效果,并且可能计算方面更为高效
极大似然估计的应用对应于假设变量独立同分布,联合概率等于概率乘积,损失函数才能对应的上
单个样本
令 y ^ = p ( y = 1 ∣ x ) \hat y=p(y=1|x) y^=p(y=1∣x)
输出概率 P ( y ∣ x ) = y ^ y ( 1 − y ^ ) 1 − y P(y|x)=\hat y^{y}(1-\hat y)^{1-y} P(y∣x)=y^y(1−y^)1−y
当 y=1 时,输出 y ^ \hat y y^
当 y=0 时,输出 1 − y ^ 1-\hat y 1−y^
恰好对应 p ( y = 1 ∣ x ) p(y=1|x) p(y=1∣x) 的值
对 P ( y ∣ x ) P(y|x) P(y∣x) 变形,取对数不影响最优化,变形之后变成 l o g P ( y ∣ x ) = y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) logP(y|x)=ylog\hat y+(1-y)log(1-\hat y) logP(y∣x)=ylogy^+(1−y)log(1−y^),对应上损失函数的表达形式
m 个样本
独立同分布假设下概率乘积等价于对数求和,因此损失函数对应成 J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) = 1 m ∑ i = 1 m ( − y ( i ) l o g y ^ ( i ) − ( 1 − y ( i ) l o g ( 1 − y ^ ( i ) ) ) J(w,b)=\frac{1}{m}\sum_{i=1}^{m}L(\hat y^{(i)},y^{(i)})=\frac {1}{m}\sum_{i=1}^{m}(-y^{(i)}log\hat y^{(i)}-(1-y^{(i)}log(1-\hat y^{(i)})) J(w,b)=m1∑i=1mL(y^(i),y(i))=m1∑i=1m(−y(i)logy^(i)−(1−y(i)log(1−y^(i)))
总结一下,为了最小化成本函数,我们从 logistic 回归模型的最大似然估计的角度出发,假设训练集中的样本都是独立同分布的条件下。
2.19 总结
介绍了神经网络的基础——逻辑回归。首先,我们介绍了二分类问题,以图片为例,将多维输入x转化为feature vector,输出y只有{0,1}两个离散值。接着,我们介绍了逻辑回归及其对应的Cost function形式。然后,我们介绍了梯度下降算法,并使用计算图的方式来讲述神经网络的正向传播和反向传播两个过程。最后,我们在逻辑回归中使用梯度下降算法,总结出最优化参数w和b的算法流程。
介绍了神经网络基础——python和向量化。在深度学习程序中,使用向量化和矩阵运算的方法能够大大提高运行速度,节省时间。以逻辑回归为例,我们将其算法流程包括梯度下降转换为向量化的形式。同时,我们也介绍了python的相关编程方法和技巧。
第三周:浅层神经网络(Shallow neural networks)
3.1 神经网络概述(Neural Network Overview)
逻辑回归模型

预测的输出就是 y ^ = σ ( w T x + b ) \hat y=\sigma (w^{T}x+b) y^=σ(wTx+b)
多个逻辑回归模型堆叠成为一层,多层堆叠形成神经网络。每个节点代表一次计算结果,前一层的计算结果又作为下一层的输入继续运算。

3.2 神经网络的表示(Neural Network Representation)
如上图所示,输入特征竖直堆叠作为输入层,中间三个结点竖直堆叠作为隐藏层,右边一个结点作为输出层。
隐藏层的含义:训练过程中中间结点准确值不知道,只能知道输入和输出,中间像是一个黑盒对外隐藏。
根据输入层算不算一层,可以叫做两层神经网络或三层神经网络。
a a a 表示运算产生的结果数值, a 1 [ 1 ] a_{1}^{[1]} a1[1] 右上角表示第一层的输出,右下角表示这是该层第一个结点。
3.3 计算一个神经网络的输出(Computing a Neural Network’s output)
神经网络的计算
逻辑回归的计算过程如下图所示,有两个步骤,先计算线性结果,再进行非线性变换。一个神经网络只是这样子做了好多次重复计算。
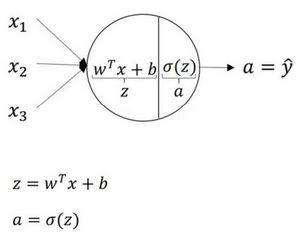
根据给出的一个单独的输入特征向量,运用四行代码计算出一个简单神经网络的输出。
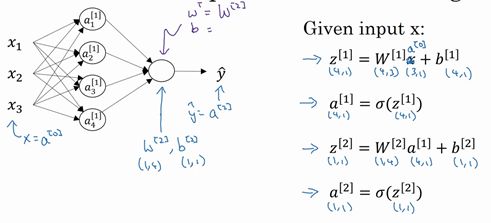
w w w 的形状(m, n)m 等于该层结点的个数,n 等于前一层输入的个数
3.4 多样本向量化(Vectorizing across multiple examples)
上面是一个样本输入计算的输出,当样本数为 m 个时,需要对 m 个样本都进行一次计算。为了不用 for 循环,使用向量化来进行计算。
对于一个样本的计算过程,输入层是列向量,隐藏层的输出是列向量,输出层还是列向量。把列向量堆叠起来组成矩阵,就可以一次对 m 个训练样本进行计算。
x = [ ⋮ ⋮ ⋮ ⋮ x ( 1 ) x ( 2 ) ⋯ x ( m ) ⋮ ⋮ ⋮ ⋮ ] x=\left[ \begin{array}{c} \vdots & \vdots & \vdots & \vdots\\ x^{(1)} & x^{(2)} & \cdots & x^{(m)}\\ \vdots & \vdots & \vdots & \vdots\\ \end{array} \right] x=⎣⎢⎢⎡⋮x(1)⋮⋮x(2)⋮⋮⋯⋮⋮x(m)⋮⎦⎥⎥⎤
Z [ 1 ] = [ ⋮ ⋮ ⋮ ⋮ z [ 1 ] ( 1 ) z [ 1 ] ( 2 ) ⋯ z [ 1 ] ( m ) ⋮ ⋮ ⋮ ⋮ ] Z^{[1]}=\left[\begin{array}{c}\vdots & \vdots & \vdots & \vdots\\z^{[1](1)} & z^{[1](2)} & \cdots & z^{[1](m)}\\\vdots & \vdots & \vdots & \vdots\\\end{array}\right] Z[1]=⎣⎢⎢⎡⋮z[1](1)⋮⋮z[1](2)⋮⋮⋯⋮⋮z[1](m)⋮⎦⎥⎥⎤
A [ 1 ] [ ⋮ ⋮ ⋮ ⋮ α [ 1 ] ( 1 ) α [ 1 ] ( 2 ) ⋯ α [ 1 ] ( m ) ⋮ ⋮ ⋮ ⋮ ] A^{[1]}\left[ \begin{array}{c} \vdots & \vdots & \vdots & \vdots\\ \alpha^{[1](1)} & \alpha^{[1](2)} & \cdots & \alpha^{[1](m)}\\ \vdots & \vdots & \vdots & \vdots\\ \end{array} \right] A[1]⎣⎢⎢⎡⋮α[1](1)⋮⋮α[1](2)⋮⋮⋯⋮⋮α[1](m)⋮⎦⎥⎥⎤
水平方向上,对应于不同的训练样本;竖直方向上,对应不同的输入特征,而这就是神经网络输入层中各个节点。
3.5 向量化实现的解释(Justification for vectorized implementation)
单个样本的计算 z [ 1 ] [ i ] = W [ 1 ] x ( i ) + b ( 1 ) z^{[1][i]}=W^{[1]}x^{(i)}+b^{(1)} z[1][i]=W[1]x(i)+b(1)
整体样本的计算 Z [ 1 ] = W [ 1 ] X + b ( 1 ) Z^{[1]}=W^{[1]}X+b^{(1)} Z[1]=W[1]X+b(1)
理解了样本增加只是在横向堆叠列向量,就可以理解向量化实现了,只是从行列式的乘积转换为矩阵乘积
3.6 激活函数(Activation functions)
- sigmoid 函数 σ ( z ) = 1 1 + e − z \sigma (z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1
- tanh 函数 t a n h ( z ) = e z − e − z e z + e − z tanh(z)=\frac{e^{z}-e^{-z}}{e^{z}+e^{-z}} tanh(z)=ez+e−zez−e−z
事实上,**tanh **函数是 sigmoid 的向下平移和伸缩后的结果。对它进行了变形后,穿过了点(0,0),并且值域介于+1和-1之间。**tanh **函数在所有场合都优于 sigmoid 函数。(例外:二分类问题输出介于 0~1 之间)
sigmoid 函数和 tanh 函数两者共同的缺点是,在特别大或者特别小的情况下,导数的梯度或者函数的斜率会变得特别小,最后就会接近于0,导致降低梯度下降的速度。
- ReLu 函数 r e l u ( z ) = m a x ( 0 , z ) relu(z)=max(0,z) relu(z)=max(0,z)
z = 0 z=0 z=0 导数没有定义,实际实现时假设一个导数是1或者0效果都可以。
- 选择激活函数的经验法则
- 如果输出是0、1值(二分类问题),则输出层选择sigmoid函数,然后其它的所有单元都选择Relu函数
- 这是很多激活函数的默认选择,如果在隐藏层上不确定使用哪个激活函数,那么通常会使用 Relu 激活函数。有时,也会使用 tanh 激活函数,但 Relu 的一个优点是:当是负值的时候,导数等于0
- Leaky Relu 这个函数通常比 Relu 激活函数效果要好,尽管在实际中 Leaky ReLu 使用的并不多
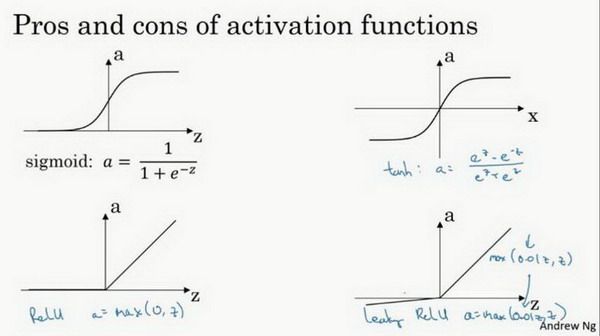
Relu 和 Leaky ReLu 优点:
- 学习更快
在 z z z 的区间变动很大的情况下,激活函数的导数或者激活函数的斜率都会远大于 0,在程序实现就是一个 if-else 语句,而 sigmoid 函数需要进行浮点四则运算,在实践中,使用 ReLu 激活函数神经网络通常会比使用 **sigmoid **或者 **tanh **激活函数学习的更快
- 不出现梯度弥散
sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于0,这会造成梯度弥散,而 Relu 和 Leaky ReLu 函数大于 0 部分都为常数,不会产生梯度弥散现象。(同时应该注意到的是,Relu 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性,而 Leaky ReLu 不会有这问题)
选择建议
如果不确定哪一个激活函数效果更好,可以把它们都试试,然后在验证集或者发展集上进行评价。然后看哪一种表现的更好,就去使用它。
3.7 为什么需要非线性激活函数?(why need a nonlinear activation function?)
不使用非线性激活函数的话隐藏层就没有作用,和直接从输入层进行线性变换等价
如果你使用线性激活函数或者没有使用一个激活函数,那么无论你的神经网络有多少层一直在做的只是计算线性函数,所以不如直接去掉全部隐藏层。
3.8 激活函数的导数(Derivatives of activation functions)
- sigmoid activation function

d d z g ( z ) = 1 1 + e − z ( 1 − 1 1 + e − z ) = g ( z ) ( 1 − g ( z ) ) \frac{d}{dz}g(z) = {\frac{1}{1 + e^{-z}} (1-\frac{1}{1 + e^{-z}})}=g(z)(1-g(z)) dzdg(z)=1+e−z1(1−1+e−z1)=g(z)(1−g(z))
- Tanh activation function

d d z g ( z ) = 1 − ( t a n h ( z ) ) 2 \frac{d}{{d}z}g(z) = 1 - (tanh(z))^{2} dzdg(z)=1−(tanh(z))2
- Rectified Linear Unit (ReLU)
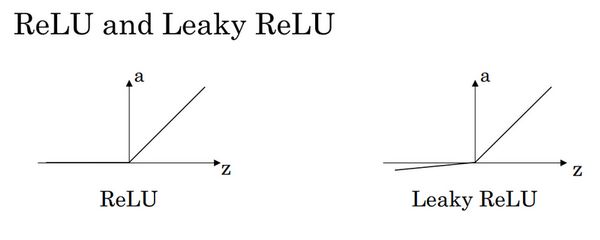
g ( z ) ′ = { 0 if z < 0 1 if z > 0 u n d e f i n e d if z = 0 g(z)^{'}= \begin{cases} 0& \text{if z < 0}\\ 1& \text{if z > 0}\\ undefined& \text{if z = 0} \end{cases} g(z)′=⎩⎪⎨⎪⎧01undefinedif z < 0if z > 0if z = 0
注:通常在 z= 0 的时候给定其导数 1, 0;当然 z=0 的情况很少
-
Leaky linear unit (Leaky ReLU)
g ( z ) = max ( 0.01 z , z ) g ( z ) ′ = { 0.01 if z < 0 1 if z > 0 u n d e f i n e d if z = 0 g(z)=\max(0.01z,z) \\ \\ \\ g(z)^{'}= \begin{cases} 0.01& \text{if z < 0}\\ 1& \text{if z > 0}\\ undefined& \text{if z = 0} \end{cases} g(z)=max(0.01z,z)g(z)′=⎩⎪⎨⎪⎧0.011undefinedif z < 0if z > 0if z = 0$
注:通常在 z=0 的时候给定其导数 1, 0.01;当然 z=0 的情况很少
3.9 神经网络的梯度下降(Gradient descent for neural networks)
梯度下降法的目的是优化损失函数,通过梯度下降更新 w w w 和 b b b 的值,找到损失函数的最优解。
总结一下,浅层神经网络(包含一个隐藏层),m个训练样本的正向传播过程和反向传播过程分别包含了6个表达式,其向量化矩阵形式如下图所示:

d W [ 2 ] = d z [ 2 ] ⋅ ∂ z [ 2 ] ∂ W [ 2 ] = d z [ 2 ] a [ 1 ] T dW^{[2]}=dz^{[2]}\cdot \frac{\partial z^{[2]}}{\partial W^{[2]}}=dz^{[2]}a^{[1]T} dW[2]=dz[2]⋅∂W[2]∂z[2]=dz[2]a[1]T 中, d W [ 2 ] dW^{[2]} dW[2] 表示 d z [ 2 ] d W [ 2 ] \frac {dz^{[2]}}{dW^{[2]}} dW[2]dz[2] , d z [ 2 ] dz^{[2]} dz[2] 表示链式推导到 z [ 2 ] z^{[2]} z[2] 的值,乘积就是链式推导到 W [ 2 ] W^{[2]} W[2] 的值
d W [ 2 ] = d z [ 2 ] ⋅ ∂ z [ 2 ] ∂ W [ 2 ] = d z [ 2 ] a [ 1 ] T dW^{[2]}=dz^{[2]}\cdot \frac{\partial z^{[2]}}{\partial W^{[2]}}=dz^{[2]}a^{[1]T} dW[2]=dz[2]⋅∂W[2]∂z[2]=dz[2]a[1]T 转置的问题现在可以用矩阵乘积维度分析理解,课上提到的 w 的行向量和列向量还没理解
3.11 随机初始化(Random+Initialization)
神经网络模型中的参数权重W是不能全部初始化为零的,若全部初始化为 0,隐藏层两个神经元对应的权重行向量 W 每次迭代更新都会得到完全相同的结果。这样隐藏层设置多个神经元就没有任何意义了。值得一提的是,参数 b 可以全部初始化为零,并不会影响神经网络训练效果。
W_1 = np.random.randn((2,2))*0.01
b_1 = np.zero((2,1))
W_2 = np.random.randn((1,2))*0.01
b_2 = 0
W2[1] 乘以0.01的目的是尽量使得权重W初始化比较小的值。之所以让W比较小,是因为如果使用sigmoid函数或者tanh函数作为激活函数的话,W比较小,得到的|z|也比较小(靠近零点),而零点区域的梯度比较大,这样能大大提高梯度下降算法的更新速度,尽快找到全局最优解。如果W较大,得到的|z|也比较大,附近曲线平缓,梯度较小,训练过程会慢很多。
当然,如果激活函数是ReLU或者Leaky ReLU函数,则不需要考虑这个问题。但是,如果输出层是sigmoid函数,则对应的权重W最好初始化到比较小的值。
3.12 总结
本节课主要介绍了浅层神经网络。首先,我们简单概述了神经网络的结构:包括输入层,隐藏层和输出层。然后,我们以计算图的方式推导了神经网络的正向输出,并以向量化的形式归纳出来。接着,介绍了不同的激活函数并做了比较,实际应用中根据不同需要选择合适的激活函数。激活函数必须是非线性的,不然神经网络模型起不了任何作用。然后,我们重点介绍了神经网络的反向传播过程以及各个参数的导数推导,并以矩阵形式表示出来。最后,介绍了权重随机初始化的重要性,必须对权重W进行随机初始化操作。
第四周:深层神经网络(Deep Neural Networks)
4.1 深层神经网络(Deep L-layer neural network)
逻辑回归和一个隐藏层的神经网络

对于任何给定的问题很难去提前预测到底需要多深的神经网络,所以先去尝试逻辑回归,尝试一层然后两层隐含层,然后把隐含层的数量看做是另一个可以自由选择大小的超参数,然后再保留交叉验证数据上评估,或者用你的开发集来评估。
深度学习的符号定义

L = 4 L=4 L=4、 n [ 0 ] = n x = 3 n^{[0]}=n_{x}=3 n[0]=nx=3、 n [ 1 ] = 5 n^{[1]}=5 n[1]=5、 n [ 2 ] = 5 n^{[2]}=5 n[2]=5、 n [ 3 ] = 3 n^{[3]}=3 n[3]=3、 n [ 4 ] = n [ L ] = 1 n^{[4]}=n^{[L]}=1 n[4]=n[L]=1
a [ l ] a^{[l]} a[l] 记作 l l l 层激活后的结果
4.2 前向传播和反向传播(Forward and backward propagation)
前向传播
- 单个样本
a [ l ] = g [ l ] ( z [ l ] ) a^{[l]}=g^{[l]}(z^{[l]}) a[l]=g[l](z[l])
- m 个样本的向量化矩阵
Z [ l ] = W [ l ] A [ l − 1 ] + b [ l ] Z^{[l]}=W^{[l]}A^{[l-1]}+b^{[l]} Z[l]=W[l]A[l−1]+b[l]
A [ l ] = g [ l ] ( Z [ l ] ) A^{[l]}=g^{[l]}(Z^{[l]}) A[l]=g[l](Z[l])
其中 l = 1 , ⋯ , L l=1,⋯,L l=1,⋯,L
反向传播
- 单个样本
输入: d a [ l ] da^{[l]} da[l]
输出: d a [ l − 1 ] da^{[l-1]} da[l−1], d W [ l ] dW^{[l]} dW[l], d b [ l ] db^{[l]} db[l]
步骤
- d z [ l ] = d a [ l ] ∗ g [ l ] ′ ( z [ l ] ) dz^{[l]}=da^{[l]}*g^{[l]^{'}}(z^{[l]}) dz[l]=da[l]∗g[l]′(z[l])
- d w [ l ] = d z [ l ] ⋅ a [ l − 1 ] dw^{[l]}=dz^{[l]}·a^{[l-1]} dw[l]=dz[l]⋅a[l−1]
- d b [ l ] = d z [ l ] db^{[l]}=dz^{[l]} db[l]=dz[l]
- d a [ l − 1 ] = w [ l ] T ⋅ d z [ l ] da^{[l-1]}=w^{[l]T}·dz^{[l]} da[l−1]=w[l]T⋅dz[l]
- d z [ l ] = w [ l + 1 ] T d z [ l + 1 ] ⋅ g [ l ] ′ ( z [ l ] ) d{{z}^{[l]}}={{w}^{[l+1]T}}d{{z}^{[l+1]}}\cdot \text{ }{{g}^{[l]}}'( {{z}^{[l]}})~ dz[l]=w[l+1]Tdz[l+1]⋅ g[l]′(z[l])
式子(5)由式子(4)带入式子(1)得到,前四个式子就可实现反向函数
- m 个样本向量化实现
- d Z [ l ] = d A [ l ] ∗ g [ l ] ′ ( Z [ l ] ) d{{Z}^{[l]}}=d{{A}^{[l]}}*{{g}^{\left[ l \right]}}'\left({{Z}^{[l]}} \right)~~ dZ[l]=dA[l]∗g[l]′(Z[l])
- d W [ l ] = 1 m d Z [ l ] ⋅ A [ l − 1 ] T d{{W}^{[l]}}=\frac{1}{m}\text{}d{{Z}^{[l]}}\cdot {{A}^{\left[ l-1 \right]T}} dW[l]=m1dZ[l]⋅A[l−1]T
- d b [ l ] = 1 m n p . s u m ( d z [ l ] , a x i s = 1 , k e e p d i m s = T r u e ) d{{b}^{[l]}}=\frac{1}{m}\text{ }np.sum(d{{z}^{[l]}},axis=1,keepdims=True) db[l]=m1 np.sum(dz[l],axis=1,keepdims=True)
- d A [ l − 1 ] = W [ l ] T . d Z [ l ] d{{A}^{[l-1]}}={{W}^{\left[ l \right]T}}.d{{Z}^{[l]}} dA[l−1]=W[l]T.dZ[l]
4.4 核对矩阵的维数(Getting your matrix dimensions right)
- 对于单个训练样本
输入x的维度是 ( n [ 0 ] , 1 ) (n^{[0]},1) (n[0],1)
d W [ l ] = W [ l ] : ( n [ l ] , n [ l − 1 ] ) dW^{[l]}=W^{[l]}:\ (n^{[l]},n^{[l-1]}) dW[l]=W[l]: (n[l],n[l−1])
d b [ l ] = b [ l ] : ( n [ l ] , 1 ) db^{[l]}=b^{[l]}:\ (n^{[l]},1) db[l]=b[l]: (n[l],1)
d z [ l ] = z [ l ] : ( n [ l ] , 1 ) dz^{[l]}=z^{[l]}:\ (n^{[l]},1) dz[l]=z[l]: (n[l],1)
d a [ l ] = a [ l ] : ( n [ l ] , 1 ) da^{[l]}=a^{[l]}:\ (n^{[l]},1) da[l]=a[l]: (n[l],1)
- 对于m个训练样本
输入矩阵X的维度是 ( n [ 0 ] , m ) (n^{[0]},m) (n[0],m)
d W [ l ] = W [ l ] : ( n [ l ] , n [ l − 1 ] ) dW^{[l]}=W^{[l]}:\ (n^{[l]},n^{[l-1]}) dW[l]=W[l]: (n[l],n[l−1])
d b [ l ] = b [ l ] : ( n [ l ] , 1 ) db^{[l]}=b^{[l]}:\ (n^{[l]},1) db[l]=b[l]: (n[l],1)
d z [ l ] = z [ l ] : ( n [ l ] , m ) dz^{[l]}=z^{[l]}:\ (n^{[l]},m) dz[l]=z[l]: (n[l],m)
d a [ l ] = a [ l ] : ( n [ l ] , m ) da^{[l]}=a^{[l]}:\ (n^{[l]},m) da[l]=a[l]: (n[l],m)
W [ l ] W^{[l]} W[l] 和 b [ l ] b^{[l]} b[l] 维度与只有单个样本一致
Z [ 1 ] = W [ 1 ] X + b [ 1 ] Z^{[1]}=W^{[1]}X+b^{[1]} Z[1]=W[1]X+b[1] 过程中
Z [ 1 ] Z^{[1]} Z[1] 的维度为 ( n [ 1 ] , n [ 0 ] ) ∗ ( n [ 0 ] , m ) = ( n [ 1 ] , m ) (n^{[1]},n^{[0]})*(n^{[0]},m)=(n^{[1]},m) (n[1],n[0])∗(n[0],m)=(n[1],m)
b [ 1 ] b^{[1]} b[1] 由于 python 广播机制,会被当成 ( n [ 1 ] , m ) (n^{[1]},m) (n[1],m) 进行计算
4.5 为什么使用深层表示?(Why deep representations?)
提取特征复杂度
从简单到复杂的金字塔状表示方法或者组成方法,深度神经网络的这许多隐藏层中,较早的前几层能学习一些低层次的简单特征,等到后几层,就能把简单的特征结合起来,去探测更加复杂的东西。
减少神经元个数以减少计算量
电路理论的解释
有一些函数你可以用一个小的L层深度神经网络来计算,而较浅的网络需要指数级更多的隐藏单元来计算。

处理同一逻辑问题,深层网络所需的神经元个数比浅层网络要少很多。这也是深层神经网络的优点之一。
尽管深度学习有着非常显著的优势,Andrew还是建议对实际问题进行建模时,尽量先选择层数少的神经网络模型,这也符合奥卡姆剃刀定律(Occam’s Razor)。对于比较复杂的问题,再使用较深的神经网络模型。
4.6 搭建神经网络块(Building blocks of deep neural networks)
- 对于第 l 层来说
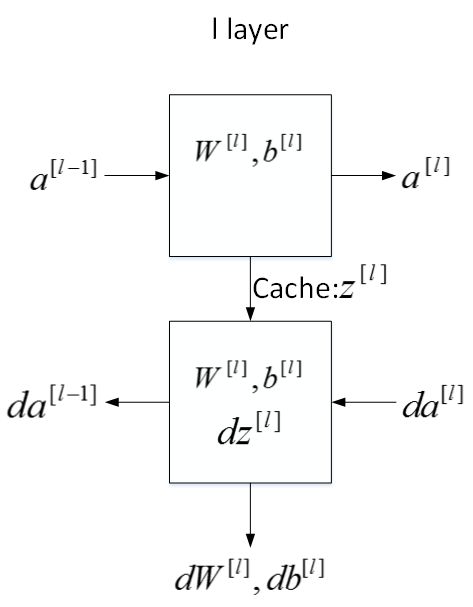
正向传播过程中:
输入: a [ l − 1 ] a^{[l-1]} a[l−1]
输出: a [ l ] a^{[l]} a[l]
参数: W [ l ] , b [ l ] W^{[l]}, b^{[l]} W[l],b[l]
缓存变量: z [ l ] z^{[l]} z[l]
反向传播过程中:
输入: d a [ l ] da^{[l]} da[l]
输出: d a [ l − 1 ] , d W [ l ] , d b [ l ] da{[l-1]}, dW^{[l]}, db^{[l]} da[l−1],dW[l],db[l]
参数: W [ l ] , b [ l ] W^{[l]}, b^{[l]} W[l],b[l]
- 对于神经网络所有层

4.7 参数VS超参数(Parameters vs Hyperparameters)
参数:神经网络中的参数就是我们熟悉的 W [ l ] W^{[l]} W[l] 和 b [ l ] b^{[l]} b[l]
超参数:例如学习速率 α,训练迭代次数 N,神经网络层数 L,各层神经元个数 n [ l ] n^{[l]} n[l],激活函数 g(z) 等。
超参数需要自己设置,这些超参数控制了最后参数的值
如何设置最优的超参数是一个比较困难的、需要经验知识的问题。通常的做法是选择超参数一定范围内的值,分别代入神经网络进行训练,测试 cost function 随着迭代次数增加的变化,根据结果选择 cost function 最小时对应的超参数值。这类似于 validation 的方法。
学习机器学习和深度学习有时候感觉就像是玄学,参数靠调,效果靠天。感觉很多时候都是在试,没有什么行之有效的指导手册。不过科学似乎也是这么发展的,很多成果都是人们试验并不断努力达到的。同样,可能很多研究方向穷尽了几代人的努力也没有什么成果,可能方向就是错误的。在不断尝试中不断前进,在不断试验中逐渐总结,这或许才应该是面对不确定性时的态度。
4.8 深度学习和大脑的关联性(What does this have to do with the brain?)
关联不大。
当你在实现一个神经网络的时候,那些公式是你在做的东西,你会做前向传播、反向传播、梯度下降法,其实很难表述这些公式具体做了什么。一个神经网络的逻辑单元可以看成是对一个生物神经元的过度简化,但迄今为止连神经科学家都很难解释究竟一个神经元能做什么,它可能是极其复杂的;它的一些功能可能真的类似logistic回归的运算,但单个神经元到底在做什么目前还没有人能够真正可以解释。
4.9 总结
本节课主要介绍了深层神经网络,是上一节浅层神经网络的拓展和归纳。首先,我们介绍了建立神经网络模型一些常用的标准的标记符号。然后,用流程块图的方式详细推导正向传播过程和反向传播过程的输入输出和参数表达式。我们也从提取特征复杂性和计算量的角度分别解释了深层神经网络为什么优于浅层神经网络。接着,我们介绍了超参数的概念,解释了超参数与参数的区别。最后,我们将神经网络与人脑做了类别,人工神经网络是简化的人脑模型。
红色石头笔记
黄海波笔记
b站视频