python爬取当日疫情信息并存储为json文件
信息来源:https://ncov.dxy.cn/ncovh5/view/pneumonia
一.爬取目标网站,将所有国内数据存储在json文件内,命名为当前日期。
步骤:
1)请求目标网站。
2)获取响应的html页面。
3)利用正则表达式在获取的页面查找相应内容,并进行数据清洗。
4)将读取内容存储为json文件。
(一)请求目标网站和获取响应页面
import requests
# 网页路径
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'
}
response = requests.get(url, headers=headers)
print(response.status_code) # 打印状态码
# 更推荐使用response.content.deocde()的方式获取响应的html页面
url_text = response.content.decode() (二)定位需要提取的内容
(1)寻找需要提取的信息所在位置
右键查看网页源代码,需要提取的部分如下:

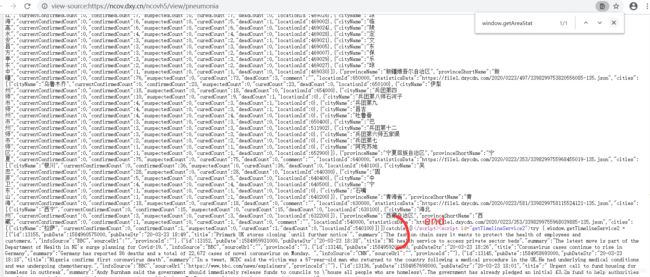
(2)利用正则表达式查找(使用re.search()函数):
上一步爬取返回的html页面为url_text,url_content为要提取的部分,则:
# re.search():扫描字符串以查找正则表达式模式产生匹配项的第一个位置 ,然后返回相应的match对象。
"""
# re.search(pattern, string, flags=0)函数源码:
def search(pattern, string, flags=0):
# Scan through string looking for a match to the pattern,
# returning a match object, or None if no match was found.
return _compile(pattern, flags).search(string)
"""
# 在字符串a中,包含换行符\n,在这种情况下:如果不使用re.S参数,则只在每一行内进行匹配。
# 而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
url_content = re.search(r'window.getAreaStat = (.*?)}]}catch', url_text, re.S)
texts = url_content.group() # 获取匹配正则表达式的整体结果(三)对提取的内容进行数据清洗,保留下需要的内容。
上一步提取的texts值如下(1),若要能存储为json文件,则需要去掉头部和尾部不符合格式的内容。这里使用字符串的replace方法。处理完数据内容如(2)。
content = texts.replace('window.getAreaStat = ', '').replace('}catch', '') # 去除多余的字符(1)处理前:
window.getAreaStat =
[
{"provinceName": "香港"...},
// ...
]
}catch(2)处理后:
[
{
"provinceName": "香港"
// ...
}
// ...
](四)将数据存入到json文件中。
在上一步成功将数据转为符合json格式的文件后,即可将数据存入json文件中。这里将数据存入当前目录的data目录下,并命名为当前日期.json。当然,操作时候应该加上try catch语句进行异常捕获。
import datetime
today = datetime.date.today().strftime('%Y%m%d') # 获取当前日期
json_data = json.loads(content) # 用于将content数据转成dict。
with open('data/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)完整获取国内各省数据并保存到json数据的代码:
import json
import re
import requests
import datetime
# 网页路径
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'
}
today = datetime.date.today().strftime('%Y%m%d')
def get_dxy_data():
"""
爬取丁香园实时统计数据,保存到data目录下,以当前日期作为文件名,存JSON文件
步骤:
1)请求目标网站,可打印状态码查看访问状态。
2)获取响应的html页面。
3)利用正则表达式在获取的页面查找相应内容,并进行数据清洗。
4)将读取内容存储为json文件。
"""
response = requests.get(url, headers=headers) # request.get()用于请求目标网站
print(response.status_code) # 打印状态码
try:
url_text = response.content.decode() # 更推荐使用response.content.deocde()的方式获取响应的html页面
# print(url_text)
# re.search():扫描字符串以查找正则表达式模式产生匹配项的第一个位置 ,然后返回相应的match对象。
url_content = re.search(r'window.getAreaStat = (.*?)}]}catch', url_text, re.S)
# 在字符串a中,包含换行符\n,在这种情况下:如果不使用re.S参数,则只在每一行内进行匹配。
# 而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
texts = url_content.group() # 获取匹配正则表达式的整体结果
"""
整体结果如下:则需要将'window.getAreaStat = '和'}catch'去掉才是标准的json格式。
window.getAreaStat =
[
{"provinceName": "香港"...},
// ...
]
}catch
转换结果:
[
{
"provinceName": "香港"
// ...
}
// ...
]
"""
content = texts.replace('window.getAreaStat = ', '').replace('}catch', '') # 去除多余的字符
json_data = json.loads(content)
with open('data/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
except:
print('' % response.status_code)
存储完打开20200406.json,发现疫情统计信息并没有存在该文件中,而是存在该json文件中的statisticsData属性内。
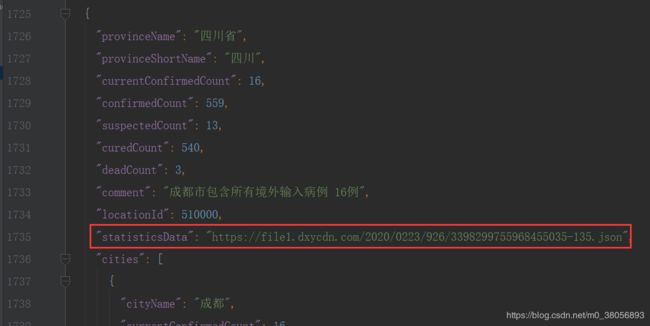
二.获取各个省份历史统计数据,保存到data目录下,存JSON文件
步骤:
1)读取之前保存的json文件。
2)创建一个空字典statistics_data用于接收各省份数据。
3)将所需要的数据存储在statistics_data.json文件
(一)以读模式打开之前保存的json文件,加载json数组。
with open('data/' + today + '.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())(二)创建一个空字典statistics_data用于接收各省份数据。
首先需要知道我们要提取的数据,每个省的统计信息,这些并没有直接存储在之前的json文件中。
(1)观察之前保存后的json数据如下:其中不同省份的statisticsData属性分别对应一个不同的json文件。因此可通过json数组['statisticsData']来提取对应的json文件路径作为请求。

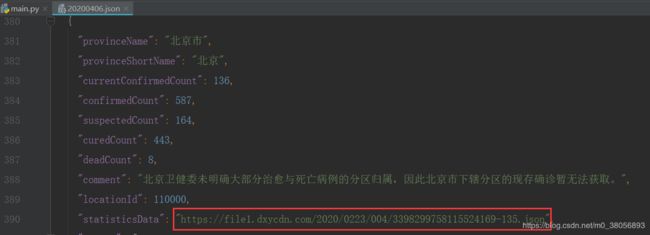
代码:请求省份对应的json文件。
statistics_data = {}
for province in json_array:
response = requests.get(province['statisticsData'])
# 如"https://file1.dxycdn.com/2020/0223/331/3398299755968040033-135.json"(2)随便选择一个statisticsData对应的json文件路径放到浏览器下载,打开json文件如下。发现对应省内的数据都保存到下载的json文件的data属性下。因此可以通过json数组['data']来提取对应省的所有数据。我们提取20200406.json文件中的"provinceName"作为statistics_data字典中的键,而data内容作为对应于provinceName的值。
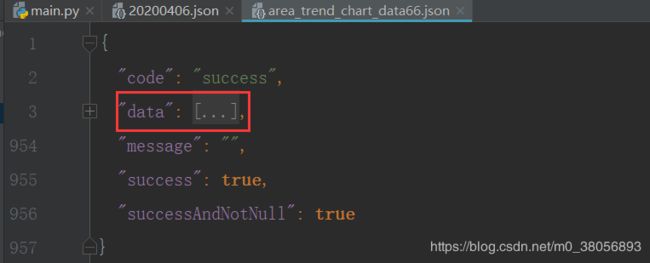
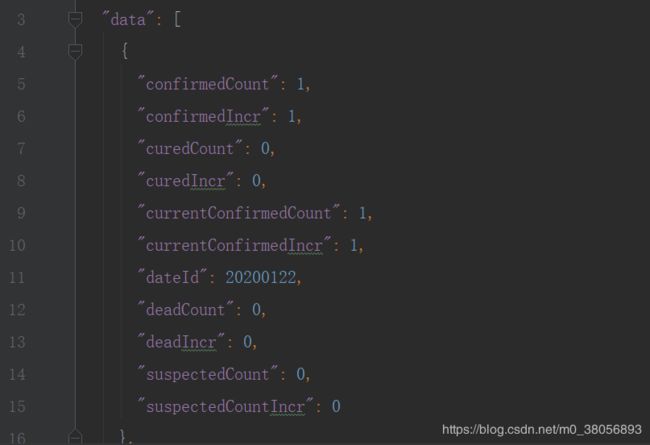

代码:将各省份及其对应的疫情数据存储到statistics_data字典中,省份名称作为键,省内疫情数据作为值。
statistics_data = {}
for province in json_array:
response = requests.get(province['statisticsData'])
# "https://file1.dxycdn.com/2020/0223/331/3398299755968040033-135.json"
try:
statistics_data[province['provinceShortName']] = json.loads(response.content.decode())['data']
except:
print(' for url: [%s]' % (response.status_code,province['statisticsData']))
(三)将所需要的数据存储在statistics_data.json文件
with open("data/statistics_data.json", "w", encoding='UTF-8') as f:
json.dump(statistics_data, f, ensure_ascii=False)完整的获取统计数据并存入json文件的代码:
import json
import re
import requests
import datetime
# 网页路径
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'
}
today = datetime.date.today().strftime('%Y%m%d')
def get_statistics_data():
"""
获取各个省份历史统计数据,保存到data目录下,存JSON文件
步骤:
1)读取之前保存的json文件
2)创建一个空字典statistics_data用于接收
3)将所需要的数据存储在statistics_data.json文件
"""
with open('data/' + today + '.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
statistics_data = {}
for province in json_array:
response = requests.get(province['statisticsData'], headers=headers) # "https://file1.dxycdn.com/2020/0223/331/3398299755968040033-135.json"
try:
statistics_data[province['provinceShortName']] = json.loads(response.content.decode())['data']
except:
print(' for url: [%s]' % (response.status_code, province['statisticsData']))
with open("data/statistics_data.json", "w", encoding='UTF-8') as f:
json.dump(statistics_data, f, ensure_ascii=False)
执行完以上两个方法则可在data下生成两个json文件,分别存放全国疫情数据和统计信息。

本节完整代码实现如下:
import json
import re
import requests
import datetime
# 网页路径
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia'
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.87 Safari/537.36'
}
today = datetime.date.today().strftime('%Y%m%d')
def get_dxy_data():
"""
爬取丁香园实时统计数据,保存到data目录下,以当前日期作为文件名,存JSON文件
步骤:
1)请求目标网站,可打印状态码查看访问状态。
2)获取响应的html页面。
3)利用正则表达式在获取的页面查找相应内容,并进行数据清洗。
4)将读取内容存储为json文件。
"""
response = requests.get(url, headers=headers) # request.get()用于请求目标网站
print(response.status_code) # 打印状态码
try:
url_text = response.content.decode() # 更推荐使用response.content.deocde()的方式获取响应的html页面
# print(url_text)
# re.search():扫描字符串以查找正则表达式模式产生匹配项的第一个位置 ,然后返回相应的match对象。
url_content = re.search(r'window.getAreaStat = (.*?)}]}catch', url_text, re.S)
# 在字符串a中,包含换行符\n,在这种情况下:如果不使用re.S参数,则只在每一行内进行匹配。
# 而使用re.S参数以后,正则表达式会将这个字符串作为一个整体,在整体中进行匹配。
texts = url_content.group() # 获取匹配正则表达式的整体结果
"""
整体结果如下:则需要将'window.getAreaStat = '和'}catch'去掉才是标准的json格式。
window.getAreaStat =
[
{"provinceName": "香港"...},
// ...
]
}catch
转换结果:
[
{
"provinceName": "香港"
// ...
}
// ...
]
"""
content = texts.replace('window.getAreaStat = ', '').replace('}catch', '') # 去除多余的字符
json_data = json.loads(content)
with open('data/' + today + '.json', 'w', encoding='UTF-8') as f:
json.dump(json_data, f, ensure_ascii=False)
except:
print('' % response.status_code)
def get_statistics_data():
"""
获取各个省份历史统计数据,保存到data目录下,存JSON文件
步骤:
1)读取之前保存的json文件
2)创建一个空字典statistics_data用于接收
3)将所需要的数据存储在statistics_data.json文件
"""
with open('data/' + today + '.json', 'r', encoding='UTF-8') as file:
json_array = json.loads(file.read())
statistics_data = {}
for province in json_array:
response = requests.get(province['statisticsData'],
headers=headers) # "https://file1.dxycdn.com/2020/0223/331/3398299755968040033-135.json"
try:
statistics_data[province['provinceShortName']] = json.loads(response.content.decode())['data']
except:
print(' for url: [%s]' % (response.status_code, province['statisticsData']))
with open("data/statistics_data.json", "w", encoding='UTF-8') as f:
json.dump(statistics_data, f, ensure_ascii=False)
if __name__ == '__main__':
get_dxy_data()
get_statistics_data()