GNN学习笔记
本文参考以下链接编写:
1.《图神经网络综述:模型与应用》
2. 几种图神经网络方法总结
3.图神经网络模型
一.GNN提出动机
1 CNN
2 图嵌入
(第一次提出GNN的论文:The graph neural network model (Scarselli, F., et al., 2009))
二.GNN
1.优点
1)可以对由元素组成的输入、输出及其依赖性进行建模,
2)可以用RNN核同时对图上的扩散过程进行建模
2.特点
1)GNN在每个节点进行传播,忽略节点的输入顺序,换句话说,GNNs 的输出对于节点的输入顺序是不变的;(改善了CNN遍历所有可能的顺序作为模型的输入的问题)
2)GNN 通常通过邻域状态的加权和来更新节点的隐藏状态;在标准神经网络中,两个节点之间的依赖信息仅仅作为节点的特征
3)发展:推理是高级人工智能的一个重要研究课题,GNN 探索从像场景图片和故事文档这样的非结构性数据生成图形,这可以成为进一步高级 AI 的强大神经模型。
4)图神经网络中每一层的聚合所使用的参数是相同的,并且这个模型可以推理出新出现节点的embedding或者一张新图的embedding。
3.基本概念
1)图(Graph):由 顶点(节点) 和 边 组成。分为有向图(wiki)和无向图。
4.基本思想
基于节点的局部邻域信息对节点进行embedding。直观来讲,就是通过神经网络来聚合每个节点及其周围节点的信息。
(将图中的节点视为目标或者concept,边表示顶点间关系。每个concept 都自然的通过各自的特征和关联concepts的特征定义。然后通过顶点包含的信息以及其邻域的信息,给每个顶点一个状态向量)
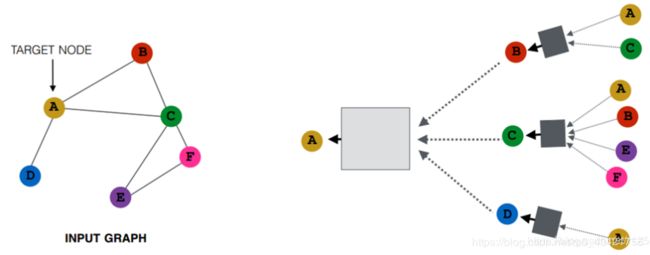
节点如何获取它的邻居节点的信息。最基本的想法就是聚合一个节点的邻居节点信息时,采用平均的方法,并使用神经网络作聚合操作,具体方法如下图:
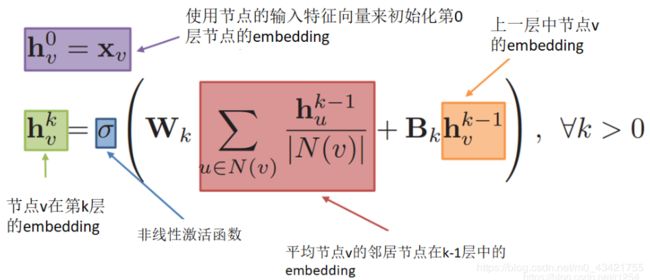
那么如何训练这个模型,具体分为监督、和无监督两种方法。
无监督的方法包括:
随机游走(Random walks):node2vec, DeepWalk
图分解(Graph factorization)
训练模型使得相似的节点具有相似的embedding
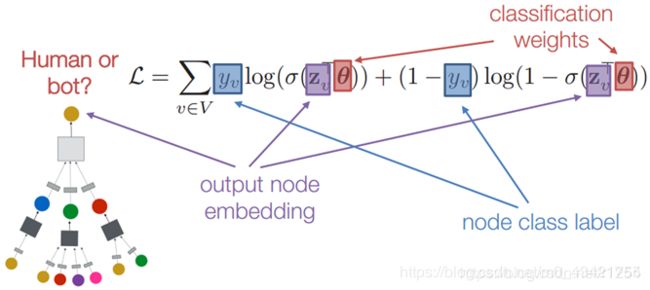
监督的方法,以二分类举例,可以定义一个交叉熵函数来作为损失函数:
图神经网络中每一层的聚合所使用的参数是相同的,并且这个模型可以推理出新出现节点的embedding或者一张新图的embedding。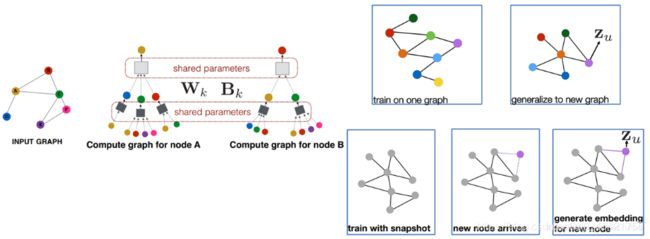
5.模型(原理)
一张图解释上面的基本思想(觉得这个图特写形象的解释了GNN的主要思想):

其中:
f w f_w fw:局部变换函数,描述节点和其邻居节点的依赖性;
g w g_w gw:局部输出函数,刻画输出值的生成过程;
将以上式子抽象为公式1:
公式1:
x n = f w ( l n , l c o [ n ] , x n e [ n ] , l n e [ n ] ) x_n = f_w(l_n,l_{co[n]},x_{ne[n]},l_{ne[n]}) xn=fw(ln,lco[n],xne[n],lne[n])
o n = g w ( x n , l n ) o_n = g_w(x_n,l_n) on=gw(xn,ln)
l n : l_n: ln:节点n的属性
l c o [ n ] l_{co[n]} lco[n]:关联边的属性
x n e [ n ] x_{ne[n]} xne[n]:邻居节点的状态
l n e [ n ] l_{ne[n]} lne[n]:邻居节点的属性
Remark:
- 邻域的定义可以根据实际情况自由设定
- 变换函数和输出函数的参数可能依赖于不同的顶点 n
- 利用图表示,我们要求的是点或者边信息的一个embedding(图植入,在这里我们是一个向量,实际上也可以是其他更复杂的信息表示,甚至是另一个图)也就是F学出来一个图的内在联系,G学习的是embedding到输出的映射
整合所有的状态,属性和输出等式,公式1可以表示为公式2:
公式2:
x = F w ( x , l ) x = F_w(x,l) x=Fw(x,l)
o = G w ( x , l N ) o = G_w(x,l_N) o=Gw(x,lN)
F w F_w Fw:全局变换函数
G w G_w Gw:全局输出函数
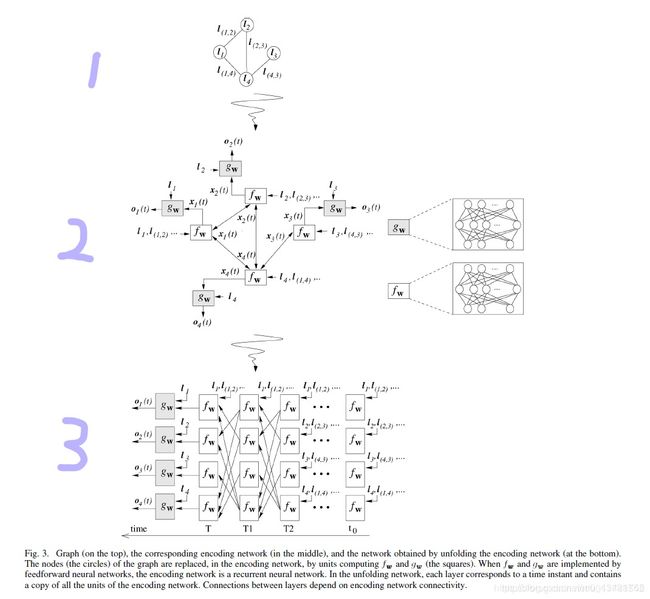
个人理解:图1是一张graph,图2是图1的一层GNN表示,图3是图2的多层表示,即GNN网络
实现GNN需要如下技术:
- 求解(1)的方法。
- 更新 f w f_w fw和 g w g_w gw的学习算法。
- f w f_w fw和 g w g_w gw的实现方案。
6.状态值的计算
通过经典的迭代方式对状态进行计算: x t + 1 = F w ( x ( t ) , l ) x_{t+1} = F_w(x(t),l) xt+1=Fw(x(t),l)
因此状态和输出值的迭代计算过程如下:
x n ( t + 1 ) = f w ( l n , l c o [ n ] , x n e [ n ] ( t ) , l n e [ n ] ) x_n(t+1) = f_w(l_n,l_{co[n]},x_{ne[n]}(t),l_{ne[n]}) xn(t+1)=fw(ln,lco[n],xne[n](t),lne[n])
o n ( t ) = g w ( x n ( t ) , l n ) o_n(t) = g_w(x_n(t),l_n) on(t)=gw(xn(t),ln)
函数 f w f_w fw和 g w g_w gw可以通过使用前馈神经网络来实现
7.学习算法

具体学习算法如以下伪代码:
主程序不断更新权重,直到期望的准确率或是到特定的停机标准

8.变换和输出函数实现
1)线性GNN
x n = f w ( l n , l c o [ n ] , x n e [ n ] , l n e [ n ] ) x_n = f_w(l_n,l_{co[n]},x_{ne[n]},l_{ne[n]}) xn=fw(ln,lco[n],xne[n],lne[n])可以表示为:
x n = h w ( l n , l ( n , u ) , x u , l u ) x_n = h_w(l_n,l(n,u),x_u,l_u) xn=hw(ln,l(n,u),xu,lu)进而表示为:
x n = A n , u x u + b n x_n = A_{n,u}x_u+b_n xn=An,uxu+bn
2)非线性GNN
h w h_w hw为多层FNN
PS:本文只是自己看了一些大佬们的博客以后把自己觉得很重要的部分摘录出来以供以后学习,相关链接文章开头均已列出。以后如果有相关代码实现,会继续更新 ~