不需要锚框:一种全卷积 One-Stage 目标检测算法(FCOS)
本文来源于 ICCV'19 上发表的一种新的目标检测技术 FCOS :全卷积 One-Stage 目标检测算法。该算法提出了一种非常直观和简单的方法来解决目标检测问题,本篇文章是对该算法的总结。

本文内容框架
- 基于锚框的检测器(Anchor-Based Detectors)
- 全卷积 One-Stage 目标检测算法(FCOS)的提出
- 多级检测(Multi-level detection)
- Centre-Ness 策略
- 实验对比
- 总结
基于锚框的检测器(Anchor-Based Detectors)
现有的目标检测方法大多使用预先定义的锚框,如:Fast-RCNN, YOLOv3, SSD, RetinaNet 等。但是这些锚框涉及到许多的超参数,如:锚框数量、尺寸比、图像划分区域数量等。而这些超参数对于最终结果的影响很大。其中,边框被判断为正样本还是负样本,由 Intersetcion over Union (IoU)这个超参数决定。而 IoU 的值极大程度上影响着锚框。下图展示了 Yolov3 当中锚框的作用:

我们之所以延续使用锚框,是因为这一方法的思想存在已久——历史上第一个目标检测器就是借鉴了经典计算机视觉早期检测模型中滑动窗口(sliding window)的概念。但是,既然现在我们拥有了多个 gpu,那么也就不需要滑动窗口了。
FCOS 的提出
因此 FCOS 方法采用了新的思路,即不再使用锚框,而是像语义分割一样,以逐像素预测的方式解决目标检测问题。首先,让我们看看这种方法是如何工作的:
设 Fᵢ为总步长为s的 CNN 的第一层Fᵢ⁰ 特征图。同时定义图像的基础边界框为Bᵢ = ( x⁰ᵢ, y⁰ᵢ, x¹ᵢ, y¹ᵢ, cᵢ ) ∈ R₄ × {1, 2 … C}. 。其中,C是类的数量;(x⁰ᵢ, y⁰ᵢ)和(x¹ᵢ, y¹ᵢ) 是边框的左上角及右下角坐标。对于特征图上的任一位置(x,y),类似于语义分割中的工作,我们可以确定其对应的原始图像中的像素。然后将特征图上的(x,y)映射到感受野中心附近位置(floor(s/2) + x*s, floor(s/2) + y*s)。通过一个 8x8 的图像以及 4x4 的特征图,将能够很好地理解这一特征提取过程。
通过上述映射,我们能够将图像中的每个像素都关联起来作为训练样本。也就意味着每个位置(x,y)都可以是正样本或负样本之一,而决定其是否属于正样本的条件为:当其位于基础边界框以内,并且该点计算得到的标签与基础边界框的标签一致。
具体的,我们通过四个值(l*, t*, r*, b*)的回归可以确定边界框的尺寸:
l* = x-x⁰ᵢ ; t* = y-y⁰ᵢ ; r* = x⁰ᵢ-x ; b* = y⁰ᵢ-y
并且针对这些值的回归计算也将是整个检测算法的损失函数的一部分。
现在,由于没有锚框,因此不需要计算锚框和边界框之间的 IoU 来获得正样本,从而可以直接训练回归器。相反,被确定为正样本的每个点(位于边界框内并具有正确的类标签)都是边界框尺寸参数回归的一部分。而这可能是即使使用的超参数更少,但FCOS比基于锚框的检测器工作得更好的原因之一。
对于特征图中的每个点,我们计算其分类得分,而对于被确定为正样本的每个点,我们进行回归。因此,总损失函数变成:
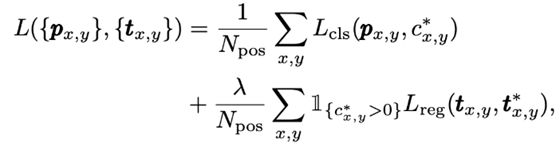
其中,λ=1。
RHS的第一部分是像素(x,y)分类,采用了 RetinaNet 中使用的标准焦距损失(Standard focal loss)。RHS的第二部分是边界框的回归,对于被确定为非正样本的像素,它被赋值为零。
多级检测(Multi-level detection)
多级预测是指利用不同层次的特征图进行目标检测。这类似于在RetinaNet中使用的FPNs(Feature Pyramid Networks)的概念。如下图所示,检测器应用于特征图P3、P4、P5、P6、P7等多个级别,这有助于我们检测图像中不同大小的物体,同时也有助于解决边界框重叠的问题。

基于锚框的检测器,通过将不同的锚框应用于不同的特征级别,以实现在不同级别分离不同的重叠的边界框。而类似于 FCOS 的无锚框检测器,则通过在不同的特征级别对回归预测进行约束,以实现相同的功能。具体地,首先定义了 $m_i$参数,对于所有的特征级别(P3-P7),mᵢ被分别设定为0、64、128、256、512和无穷大,而对于P2则设定为0。以P7为例,当max(l*,r*,t*,b*)< infinity时,对边界框进行回归预测。如果一个像素即使在多级检测之后仍然被分配给多个边界框,它将自动分配给两个边界框中较小的一个。Centre-Ness 策略
center-ness策略在每一个层级预测中添加了一个center-ness分支,该分支与分类和回归并行。顾名思义,它是对边界框内正样本像素的中心度进行计算,相当于给网络添加了一个损失,而该损失保证了预测的边界框尽可能的靠近中心。这是为了改善无锚框检测器的性能,使其与基于锚框的检测器不相上下。
具体地,中心度(centerness)计算如下:

实验对比
与主流的基于锚框的目标检测算法进行性能对比,结果如下:
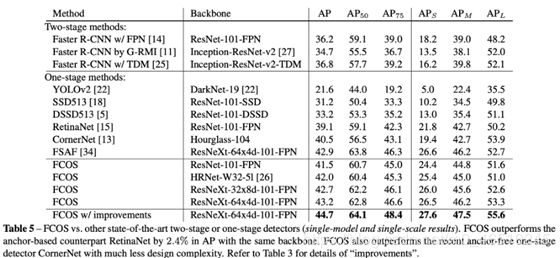
上表显示了 FCOS 与 RetinaNet (一种最先进的基于锚框的算法)的性能比较。可以看出,在相同主干网络的情况下,FCOS的性能比RetinaNet高出1.9%。
对于这两种模型,在nms阈值等参数设置相同的情况下,采用多级预测策略和centre-ness策略的FCOS算法表现都优于RetinaNet。
上表中提到的“improvements”包括:①将中心度分支移到回归分支而不是分类分支;②控制采样。

同时,上表展示了有添加 center-ness 策略和未添加 center-ness 策略的算法性能比较。可以明显看出 center-ness 策略对于提升算法性能有着很大作用。基于锚框的算法在对正锚框和负锚框进行分类时需要引入IoU阈值参数,而 center-ness 策略有助于消除这些超超参数。
值得注意的是,该研究中使用的一些重要的超参数,如学习率,NMS抑制阈值等,都是基于 RetinaNet 获取到。而如果进一步对这些超参数进行调整,将可能获得更好的目标检测效果。
总结
FCOS 这一算法能够使得目标检测更加简单化、快速化。这一方法的提出,将引导更多研究者摒弃基于锚框的目标检测算法,有可能成为解决目标检测这一难题更有效的方案。
