重温JVM(二)JVM内存模型
一、前言
上文讲过了虚拟机的内存划分,即,我们将内存分为线程共享和线程私有。
线程共享的即java堆,和方法区。java堆大家可能都不会陌生;而方法区中包含了常量池,他也被称为永久代。通常方法区也会被叫做非堆,但是在逻辑上,他却是java堆的一部分,而且有些虚拟机会将方法区直接与java堆合并。
线程私有的就是虚拟机栈了,而虚拟机栈,本地方法栈,以及程序计数器。这里我们就不展开讨论了。
上面我就简单的回顾了虚拟机的内存划分部分,下面开始正文。
二、java内存模型简述
1、主内存
java内存模型规定了,所有的变量都必须存储在主内存当中。
2、工作内存
每天线程私有的内存,即工作内存。
工作内存中保存了该线程所使用的变量的主内存的副本的拷贝。线程对变量所做的操作,都必须在工作内存中进行。
不同个的线程,无法访问对方的工作内存变量,只能通过主内存,来达到线程、工作内存、主内存三者之间的信息交互。
简图如下:
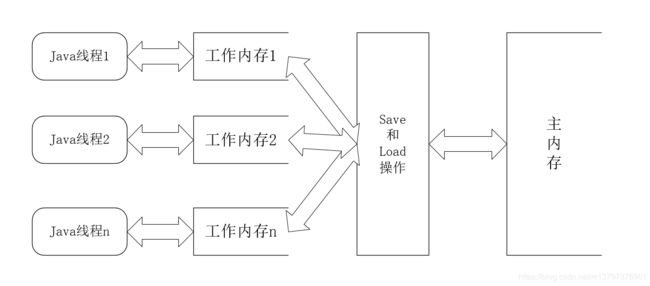
主内存、工作内存,与我上一篇博客中讲述的java内存区域中的堆、栈、方法区等,并不是同一个层次的内存划分。
不同,为了方便记忆,我们可以这么理解:
主内存对应的是java堆中的实例数据部分,工作内存对应的是java虚拟机栈中的部分区域。
从计算机的组织原理来说,我们也可以这么来理解,主内存对应的是物理硬件的内存,所以如果主内存与进程进行数据交互,它将是非常耗时的。
工作内存优先存储在寄存器和高速缓存中,因为程序在运行一般访问的是工作内存。
(所以我在上篇博客的开头就讲了,抛开操作系统和组织原理来讲虚拟机,就是在耍流氓 =_=)
三、关于原子性的二三事
1、从一段代码开始
No BB, show code
private static volatile int i = 0;
public static void add(){
i++;
}
public static void main(String [] args){
for(int c=0; c<20; c++){
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
for(int k = 0; k<10000; k++){
add();
}
}
});
thread.start();
}
while (Thread.activeCount()>1){
Thread.yield();
}
System.out.println(i);
}
如果你看过上面的代码,那可以继续阅读,如果没有见过上面的代码,这里建议思考下,最后输出的值是多少?
显而易见,结果并不是200000。(如果最后的结果就是200000,那么我举这个例子干嘛 =。=)
2、虚拟机内部的原子操作
无论是长辈,还是其他人的建议,都提过,带着问题阅读的效率会比漫无目的阅读,效果好很多,所以上面我提出了问题,下文自然是为了解决问题而展开的额讨论和说明。这里,先从java虚拟机内存的操作开始讲起。
lock:作用于主内存,将主内存的某变量标志为一条线程独占。
unlock:作用于主内存,将主内存中的变量,从锁定状态解放出来,解放出来的变量,才可以重新被其他线程占用。
read:作用于主内存,将主内存中的变量,从主内存传输到工作内存中。
load:作用于工作内存,将read到的值,放到工作内存的副本当中。
use:作用于工作内存,将工作内存中的一个变量,传递给执行引擎。当虚拟机执行的字节码指令,运用到此值时,使用此操作。
assign:作用于工作内存,将从执行引擎接受到的值,赋值给工作内存的变量。每当执行字节码的赋值语句时,会使用此操作。
store:作用于工作内存的变量,将工作内存中的变量,传输到主内存中。
write:作用于主内存,将store中从工作内存获取到的变量,放到主内存的变量当中。
3、原子操作的划分
原子操作分为两部分,一般,通过read、load、use、write等读写操作,就可以保证数据的原子性。
但是有时候我们需要整块的业务代码,都具有原子性时,就需要使用lock与unlock。
4、volatile说明
细心的同学可能已经发现了,我上面的代码中。遍历时被volatile声明。
那么volatile的作用是什么呢?
一般来说,volatile变量对所有的线程,都是理解可见的。对于volatile变量所有的写操作,都能理解反应到其他线程中。
换言之,volatile在所有线程中都是一致的,所以,所有基于volatile变量的运算在并发下都是安全的。
其实不然,volatile变量,并不能保证并发安全。
(1)执行结果对比
| 变量类型 | 执行结果1 | 执行结果2 | 执行结果3 | 执行结果4 | 执行结果5 | 平均值(去掉极值) |
|---|---|---|---|---|---|---|
| volatile | 186632 | 196403 | 193658 | 197305 | 186825 | 192295 |
| 一般变量 | 178387 | 179369 | 189835 | 174015 | 199458 | 182530 |
我记录了五次代码的执行结果。如上表格所示。都不是我们的目标值200000。那是不是说明volatile声明的变量和不进行声明,是完全一致的呢?
非也,我在去掉了volatile声明后,执行得到的结果,如上表格展示。
最后得出的结论是,加了volatile声明,结果更加趋近目标值。造成这一现象的原因是什么呢?
(2) 从字节码开始说明
查看字节码的方式有一般有两种。
一是找到生产的class文件,执行 javap指令,查看编译的代码。
二是,如果你用的是idea编辑器(idea天下第一),你可以在选中要查看的java类后,点击view菜单 点击 Show Bytecode。
这两种方式,我一般选择方式二,方式二方便,且查看的代码格式符合我的阅读习惯。
public static void add();
descriptor: ()V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=0, args_size=0
0: getstatic #2 // Field i:I
3: iconst_1
4: iadd
5: putstatic #2 // Field i:I
8: return
LineNumberTable:
line 12: 0
line 13: 8
volatile声明对象的字节码指令执行流程说明
volatile变量声明的对象,的的确确是,当他在主内存中的值发生变化,会立即反应到工作内存中。
这里就有一个节点,也就是我们字节码中的
getstatic
getstatic指令,此指令,是获取了当前最新的实时的变量值。后续的对此值进行+1操作,然后返回。但是可能存在一个情况,就是在执行+1操作或者返回操作时,其他线程对这个值进行了处理,导致此线程返回的值并不是正确值了。
可能还是不太理解,我们模拟一下场景。
- 场景①
时刻1:线程A获取了此值1。(最快)
时刻2:线程B获取了此值1。(次快)
时刻3:线程C获取了此值1.(最慢) - 场景②
时刻4:线程A处理完毕了值,且write了值到主内存,执行完毕后主内存的值为2.
时刻5:线程B,在线程A修改完主内存值后,才开始执行getstatic指令,最后他执行的是2+1,执行完毕后主内存值为3
时刻6:线程C,在执行getstatic方法时,线程A已经写完数据到了主内存,而线程B还在进行+1操作。所以此时主内存值为2。他再对2进行+1操作,执行完毕后,将3写入主内存。
所以最后主内存的值为3,并不是我们的目标值4。这也是我们的代码执行结果了,小于200000的原因。
不加volatile声明对象的字节码流程说明
不加volatile声明,可能在进入线程后,未进行getstatic指令前,变量值发生了改变,而线程不知道。
所以,这也就是加了
四、线程安全的正确姿势
讲到这里,我想大家应该对上方的代码执行结果没有什么疑虑了。
但是问题又来了,如何确保能正确的得到目标值呢。
1、万能的synchronized
相比大家看到此关键字,就已经知道了我下面要讲什么了。
public synchronized static void add(){
i++;
}
对add方法,加了synchronized关键字进行修饰之后,最后得到的目标结果,就是我们的目标值20000了。
当然,越是万能,往往代表越是无能。
此方法的性能会比使用自己手动的进行lock以及unlock,性能要差很多。
特别是在1.5的jdk版本,性能差异非常大。不过在后续的jdk版本中,逐渐对synchronized在进行优化。而且官方也推荐这种方式,毕竟,他较之ReentrantLock要优雅、coooooool很多。
2、高性能的ReentrantLock
private static int i = 0;
private static ReentrantLock lock = new ReentrantLock();
public static void add(){
lock.lock();
try{
i++;
}finally {
lock.unlock();
}
}
即使是i++,我们也要进行try,这是为了养成良好的语义习惯 =_=
每一次加锁,必然要进行一次解锁。不然…嘿嘿嘿嘿
需要说明的是,ReentrantLock(重入锁)比之synchronized,多了其他的高级功能,等待可中断、实现公平锁、所可以绑定多个条件。这里就不进行展开讨论。
3、狭隘的AtomicInteger
private static AtomicInteger i =new AtomicInteger(0);
public static void add(){
i.addAndGet(1);
}
Atomic对象有很多,如AtomicBoolean、AtomicLong等。
他保证了数据操作的原子性,实现原理是通过CAS原理。
何为CAS?即比较和交换:
获取主内存值(A),将获取到的值(A)与新的值(B)放入参数。在此获取其值,如果,获取到的值与传输的值A一致,就修改主内存值为新的值B。
这也就是CAS
当然在Atimic的实现中,还是用了Unsafe类,他可以直接操作物理内存!!!!
这里我们不对他详细的展开论述。
五、总结
内存模型中,分为工作内存与主内存。
这么讲其实没意义,我换个说法,为什么要区分工作内存和主内存??
线程是程序运行的基础,而线程需要与计算机进行数据交换,而由于计算机的组成,进行数据交换会,有的内存区域传输快,有的传输慢。而且也为了保证数据的安全性,我们区分出了主内存(可以狭义的理解为物理内存)与工作内存(寄存器即高速缓存,当量大时,也会存储到物理内存中)
在重温JVM时,我多次的是思考了为什么?也就是为什么要这么设计,这么设计有什么好处,收益颇多。
六、参考
《深入理解Java虚拟机》