《RRPN:Arbitrary-Oriented Scene Text Detection via Rotation Proposals》论文笔记
- VOC数据集到RRPN所需数据格式转换脚本
1. 概述
在诸如ICDAR之类的文本检测比赛中,需要在给定的图片中检测出任意形式的文本区域,这些文本区域有水平的也有倾斜的。对于水平文本情况,是一种较为理想的文本展现形式,使用现有的SSD、YOLO、Faster R-CNN之类的检测方法都能有效检测出水平框;对倾斜文本的情况,传统的 ( x , y , h , w ) (x,y,h,w) (x,y,h,w)回归的检测模型便不能够很好完成这个任务了。这就是这篇论文需要解决的问题。
对于这样的情况,一般的思路是使用语义分割的方法分割出文本区域,再使用最小边界四边形或多边形框出文本区域,但是这样带来的问题便是耗时较长。这篇文章对于这样的问题的解决思路是在原有水平框回归的基础上添加旋转角度的回归,从而变成了回归 ( w , y , h , w , θ ) (w,y,h,w,\theta) (w,y,h,w,θ),下面的图1是传统的水平回归框与文章提出方法的对比:

文章的算法是源自于Faster R-CNN的,不同的地方是在疑似区域提取与边界框回归上,对于疑似目标的区域使用Rotation Region-of-Interest (RRoI) pooling解决,对于边界框回归是同时回归 ( w , y , h , w , θ ) (w,y,h,w,\theta) (w,y,h,w,θ),这里将旋转因素融入到区域提取网络中,使得其可以抽取任意角度的区域。还将RoI Pooling进行了改进使其变为Rotation RoI Pooling,在后面的优化过程中运用角度回归,因而最后的检测效果也是出类拔萃的。
文章的主要工作内容:
- 1)提出了一种与基于分割方法不同的文本检测方法,该方法是基于区域提取的方法,同时将RRoI(Rotation Region-of-Interest)和旋转兴趣区域学习相结合。保证了文本检测过程中的效率。
- 2)提出了一种新的任意旋转文本区域优化的策略,从而优化了旋转文本的检测性能。
- 3)该方法在MSRA-TD500,ICDAR2013和ICDAR2015中比之前的方法更精准更高效。
2. 实现方法
2.1 整体网络结构

2.2 旋转边界框的表达(Rotated Bounding Box Representation)
旋转边界框的表达(Rotated Bounding Box Representation)
文本标注使用 ( x , y , h , w , θ ) (x,y,h,w,\theta) (x,y,h,w,θ)进行表示,坐标 ( x , y ) (x,y) (x,y)代表标注框的几何中心,高度 h h h代表标注框的短边,宽度 w w w代表标注框的长边,角度 θ \theta θ是边界框的长边沿X轴旋转的正向角度,这个角度的范围是 [ − π 4 , 3 π 4 ) [-\frac{\pi}{4},\frac{3\pi}{4}) [−4π,43π)。使用这样的五个变量进行表示具有3个好处:
- 1)能够比较容易计算出两个旋转的角度差异;
- 2)相较于传统上对于边界框使用8个点的表达,使用这样的方式更能很好回归带有旋转的目标检测框情形;
- 3)使用这样的表达能够高效计算经过旋转之后训练图片的ground truth;
训练数据的增广:论文作者在取得每个batch的训练数据的时候对原始数据进行旋转变换,这个在对应的代码中有写,即使输入的数据是水平无旋转角度的扔进去训练也是接收的。

2.3 旋转的锚点(Rotation Anchors)
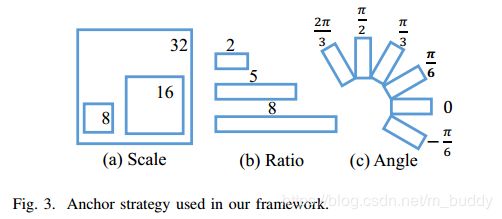
由于实际检测场景的复杂性,这里使用带有旋转角度的三维度变量anchor而非原有两维度变量anchor。在论文中使用了6个不同的角度来控制目标疑似区域的提取: − π 6 , 0 , π 6 , π 3 , π 2 , 2 π 3 -\frac{\pi}{6}, 0, \frac{\pi}{6}, \frac{\pi}{3}, \frac{\pi}{2}, \frac{2\pi}{3} −6π,0,6π,3π,2π,32π(为什么选用的是这6组角度? 在后面内容会进行说明),长宽比例采用3组: 1 : 2 , 1 : 5 , 1 : 8 1:2,1:5,1:8 1:2,1:5,1:8,尺度上也取3组 8 , 16 , 32 8,16,32 8,16,32,这样就组合生成了54个5维度的anchor( 6 ∗ 3 ∗ 3 ; ( x , y , h , w , θ ) 6*3*3; (x,y,h,w,\theta) 6∗3∗3;(x,y,h,w,θ))。对于宽高为 W ∗ H W*H W∗H的feature map会产生 H ∗ W ∗ 54 H*W*54 H∗W∗54数目的anchor。下图3是本文anchor的策略示意图:
2.4 兴趣区域的学习(Learning of Rotated Proposal)
论文中使用到的RPN网络需要在现有的anchor基础上进行学习,这一点与传统的Faster R-CNN单靠IoU进行判别不同,这里的正负样本区域提取的划定准则为:
- 正样本的情形: 与GT框的IoU大于0.7,同时与GT框的角度夹角小于 π 12 \frac{\pi}{12} 12π;
- 负样本的情形: 与GT框的IoU小于0.3,或是与GT框的IoU大于0.7但是与GT框的角度夹角大于 π 12 \frac{\pi}{12} 12π;
没有被归为上述两种情况的样本在训练过程中是不会被使用的。
这里使用的损失函数定义为如下的形式:
L ( p , l , v ∗ , v ) = L c l s ( p , l ) + λ l L r e g ( v ∗ , v ) L(p,l,v^{*},v)=L_{cls}(p,l)+\lambda lL_{reg}(v^{*},v) L(p,l,v∗,v)=Lcls(p,l)+λlLreg(v∗,v)
其中, l = 1 l=1 l=1代表前景,反之代表背景, p p p是分类的概率, v ∗ , v v^{*},v v∗,v代表GT与预测的结果。
对于分类损失定义为:
L c l s ( p , l ) = − l o g ( p l ) L_{cls}(p,l)=-log(pl) Lcls(p,l)=−log(pl)
对于边界框的回归定义为:

只选用6组anchor角度的原由:
论文中固定了旋转的表达范围是 [ − π 4 , 3 π 4 [-\frac{\pi}{4},\frac{3\pi}{4} [−4π,43π,然后在正负样本判别的时候给了 π 12 \frac{\pi}{12} 12π的裕度范围,所以这样划分就形成了这样的6组角度。
在下面的图4中可以看出同目标区域经过回归之后的角度朝向是一致的(c图)
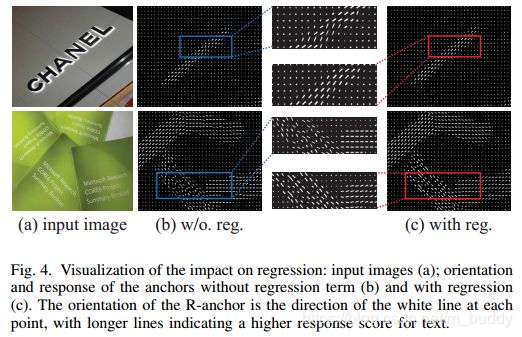
为了证明能够从feature map中训练拟合角度,下面图5展示了不同训练轮数的feature map的对比,小的白短线是对anchor有较高响应的部分。

2.5 区域提取网络的优化(Accurate Proposal Refinement)
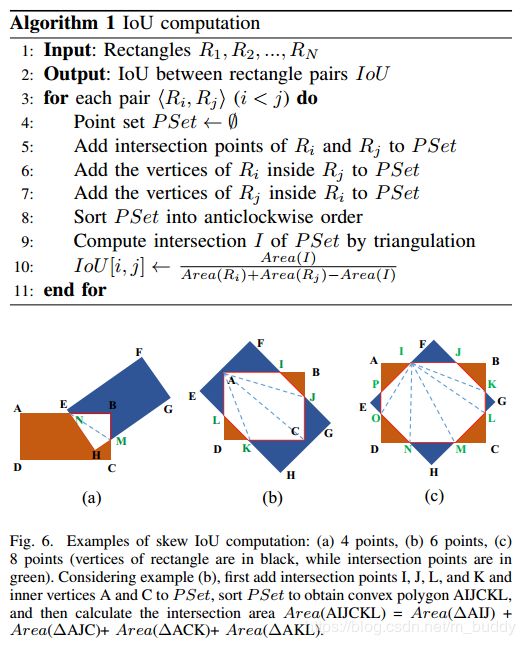
斜交情况下IoU的计算: 传统情况下参与计算IoU的矩形框都是水平的,但是这样的假设在本篇论文场景中是不成立的,因而论文提出了一种计算斜交矩形交叠面积的方法,其方法见算法1,方法的示意图见图6,在图6中将交叠区域
使用绿色的虚线划分为了多个三角形,通过计算这些三角形面积的和,从而得到交叠区域的面积。
斜交情况下的检测结果非极大值抑制: 传统的NMS算法只考虑了IoU,同样在本篇文章的场景下不适用的,因而文章给出了考虑IoU与旋转角度,得到的新算法由两步骤组成:1)保留IoU大于0.7的区域提取;2)对于IoU介于0.3~0.7之间区域提取保留与GT夹角最小的(应该小于 π 12 \frac{\pi}{12} 12π)。
2.6 RRoI Pooling Layer
这里提出RRoI Pooling是为了避免使用传统的RoI Pooling带来的损失,因为需要检测的目标是带有角度的了,所以需要对应的RRoI Pooling。其原理见图7所示,是将文本区域按照文本的方向划分为等分的格子(a图),在将这些格子中的数据映射到最后的结果中(b图)。

RRoI Pooling的算法流程见算法2中流程所示:

3. 实验
3.1 性能对比

3.2 测试图片展示
