【elasticsearch】filebeat+ELK收集数据的过程详述
前言:
为了日志收集,用了4台虚拟机,filebeat52一台,es两台95、93,logstash一台75,kibana和es的主节点在一台服务器95上,因为安装了x-pack BUT 不会用的原因、真是坑自己不带眨眼滴走了很多弯路,说多了都是泪,之前写了安装搭建的博客,希望给大家带来帮助吧,如果没有帮助那我就是在做笔记;^_^
filebeat类似一个管道,将指定路径下的文件发送到logstash中过滤给elasticsearch,然后kibana中建立索引展示——大概是这个流程,下面说一下配置过程:
安装情况:
1、filebeat安装在需要收集日志的服务器上面,指定路径
2、kibana的安装位置不受限制,配置好了就可以,我是安装在了95的/usr/local/bin/kibana-6.1.2-linux-x86_64
3、elasticsearch也在95上和kibana同目录:/usr/local/bin/elasticsearch-6.1.2
为es安装了head插件、分词ik插件、x-pack插件(不熟悉的话坑很多)
4、logstash安装在75的/usr/local/bin/logstash-6.1.2
下面进入主题啦:
filebeat.yml:
filebeat.prospectors:
- type: log
paths:
/usr/local/tomcat-achievement-8082/logs/*.log//收集这个路径下所有以log结尾的文件
tags: ["achie_log"]//标识,在logstash中我利用此对应建立索引
//对于出错的信息一般都是很多行,需要多行合并
multiline.pattern: '^\\' //以/开头的行 进行多行合并
multiline.negate: false //后面说
multiline.match: after
- type: log
paths:
/usr/local/tomcat-basicInfo-8081/logs/*.log//同上
tags: ["basic_log"]
multiline.pattern: '^\\'
multiline.negate: false
multiline.match: after
- type: log
paths:
/usr/local/tomcat-examinationEvaluation-8083/logs/*.log
tags: ["exam_log"]
multiline.pattern: '^\\'
multiline.negate: false
multiline.match: after
//因为要发送给logstash所以打开此注解,并关闭其他,例如elasticsearch
output.logstash:
# The Logstash hosts
hosts: ["192.168.22.75:4560"]
其他的可以注释掉了关于多行合并,感觉还是有必要复制一下官网的讲解:
multiline.pattern:指定正则表达式配合negate及match
multiline.negate:是否否定模式,拗口的家伙
multiline.match: 如何组合匹配的行
上面的两个选项组合出如下结果:
false after:与模式相匹配的连续行被附加 到不匹配的前一行
false before:匹配的行与下一不匹配的行合并(与模式匹配的连续行被预置到不匹配的下一行)
true after:不匹配的行与前一匹配的行合并(与模式不匹配的连续行被附加到匹配的前一行)
true before:不匹配的行与下一匹配的行合并(不匹配模式的连续行被预置到匹配的下一行)
multiline.flush_pattern:指定一个正则表达式:设置当前的多行将从内存中刷新,结束多行消息。
multiline.max_lines:可以组合成一个事件的最大行数,如果多行消息包含超过最大行数,则将丢弃任何额外的行,默认值是500。
multiline.timeout:超时后,Filebeat会发送多行事件来启动新事件,即使没有发现新模式。缺省值是5 s。
[Manage multiline messages]
修改:2018年5月1日14:28:15
- type: log
paths:
/usr/local/tomcat-authorityManagement-8084/logs/*.log
ignore_older: "24h"
fields_under_root: true#fields下的level不再是fields.level而是level
fields:
level: author_8084_53#这里添加端口号和ip,这样更加直观
review: 1
multiline.pattern: '^[[:space:]]|^Caused by'#这里做了修改
multiline.negate: false
multiline.match: afterlogstash:主要是配置正则,对应的设置索引
在config文件中写一个conf文件,其他路径也可以,启动的时候指定路径就行
input {
beats {//beats方式输入
port => 4560//(监听)4560端口
}
}
filter{//过滤
grok{//对消息中的message部分进行正则过滤
match => { "message" => "%{TIMESTAMP_ISO8601:logTime} %{LOGLEVEL:logLevel}\s*(?([\S].*))"}
}//前两个%{logstash自定义的类型:自定义字段名}% (?<自定义字段名>(正则))
}
output {//输出
if [tags][0] == "basic_log"{//还记得当年湖畔filebeat中的tags吗?if记得
elasticsearch {//输出到es中
hosts => ["192.168.22.95:9200"]//太简单,自己猜
index => "basic-log-%{+YYYY.MM.dd}"//指定索引,类似于mysql中的数据库
}
}
if [tags][0] == "achie_log"{
elasticsearch {
hosts => ["192.168.22.95:9200"]
index => "achie_log-%{+YYYY.MM.dd}"
}
}
if [tags][0] == "exam_log"{
elasticsearch {
hosts => ["192.168.22.95:9200"]
index => "exam-log-%{+YYYY.MM.dd}"
}
}
}我这里把x-pack安全检查给关了,开了的话需要添加,否则会向我一样,自己把自己埋了都不知道,说多了都是泪~
elasticsearch {
hosts => ["192.168.22.95:9200"]
index => "exam-log-%{+YYYY.MM.dd}"
user => logstash_internal
password => changeme
}启动命令:后台运行
./bin/logstash -f config/beat.conf &//-f后面是路径及文件名
修改:2018年5月1日14:32:28
output {
elasticsearch {
hosts => "192.168.22.95:9200"
index => "%{level}-%{+YYYY.MM.dd}"#取level字段,更加灵活
}
}现在正在用的是log-outto-es-using.conf这个文件
经过上面这些我们就把日志存到了es上面了
为了接收数据,elasticsearch安装配置了就好,关于怎么安装看我之前的博客:集群 单机
终于到kibana了呐,这个K吧很炫如果玩转了的话,刚才咱们通过logstash给elasticsearch创建了一系列索引(类似于数据库),怎么用kibana显示出来呐?kibana和elasticsearch通过配置文件连起来了,但是elasticsearch里面有什么数据,kibana是不知道的,那怎么让她知道并显示出来呐?
在kibana中也创建一个与elasticsearch 中的索引 同名的索引,elasticsearch里面的数据会通过kibana创建的索引名自动归到这个索引下;怎么创建索引:


Dev Tools 这个用来增删改查数据:
如果上面kibana需要建立索引才能和elasticsearch中的数据对上,您不理解的话记住就可以了,我目前处于小白阶段,时间也有点紧,再多说一点的话我只能再举个例子了
比如,我再Dev Toos这个界面创建一个索引:
//tvs为index,sales为type,brand为properties属性字段,类型为text(默认分词)
PUT /tvs/
{
"mappings": {
"sales": {
"properties": {
"brand": {
"type": "text"
}
}
}
}
}
//添条数据,因为刚才试了一下,没有数据,kibana也不能识别这个索引。用put报错,换成了POST方式,批量添加
POST /tvs/sales
{
"brand":"阿狸"
}
//添加这一条,之后把他删了,kibana还是可以识别这个索引,
DELETE /tvs/sales/id='8dS85WIBurbT4svEM35A'
//id是自动生成的,也可以指定,下面操作查询/tvs/sales/下的数据可以看到id
get /tvs/sales/_search在kibana其他的界面是找不到这个tvs索引的

我理解的是:es有了索引但是kibana并没有对应的索引(名称一致:对应)

如果你在kibana中新建索引,那就可以找对应es中的数据,进行操作了

这个可以命名为tv*,那么所有以tv开头的索引都会归到这个索引下,这样在某些情况下、这样区分度不是很好,都堆到一起了,但是也不一定,具体看需求,说回来,看是不是有了!
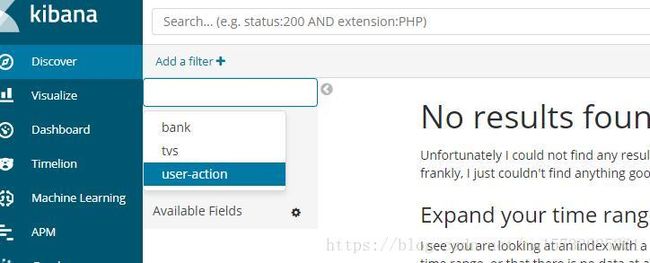
这篇博客的量已经够了,下篇见
kibana地址:http:*..95:5601
head地址:http:*..95:9100
后语:
在下才疏学浅目前正在学习过程中,这是后语,谢谢大家的阅读,对啦、还有一点,filebeat对齐很重要,稍微正规点滴说filebeat格式很重要,有那么一句话叫做:虽然我们很轻量但是仪式感不能少。本来想写四个字,不知不觉写了很多,还在说废话,就这样吧,谢谢达家。