k8s日志收集方案
本文介绍通过elk + filebeat方式收集k8s日志,其中filebeat以logagent方式部署。elfk最新版本:7.6.2
k8s日志收集方案
- 3种日志收集方案:
1. node上部署一个日志收集程序Daemonset方式部署日志收集程序,对本节点 /var/log 和 /var/lib/docker/containers 两个目录下的日志进行采集
-
sidecar方式部署日志收集程序
每个运行应用程序的pod中附加一个日志收集的容器,使用 emptyDir 共享日志目录让日志容器收集日志
-
应用程序直接推送日志
常见的如 graylog 工具,直接修改代码推送日志到es,然后在graylog上展示出来
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 3种收集方案的优缺点:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 1. node上部署一个日志收集程序 | 每个node仅需部署一个日志收集程序,消耗资源少,对应用无侵入 | 应用程序日志需要写到标准输出和标准错误输出,不支持多行日志 |
| 2. pod中附加一个日志收集容器 | 低耦合 | 每个pod启动一个日志收集容器,增加资源消耗 |
| 3. 应用程序直接推送日志 | 无需额外收集工具 | 侵入应用,增加应用复杂度 |
下面测试第1种方案:每个node上部署一个日志收集程序,注意elfk版本保持一致。
LogAgent方式收集k8s日志
- 主机说明:
| 系统 | ip | 角色 | cpu | 内存 | hostname |
|---|---|---|---|---|---|
| CentOS 7.8 | 192.168.30.128 | master、deploy | >=2 | >=2G | master1 |
| CentOS 7.8 | 192.168.30.129 | master | >=2 | >=2G | master2 |
| CentOS 7.8 | 192.168.30.130 | node | >=2 | >=2G | node1 |
| CentOS 7.8 | 192.168.30.131 | node | >=2 | >=2G | node2 |
| CentOS 7.8 | 192.168.30.132 | node | >=2 | >=2G | node3 |
- 搭建k8s集群:
搭建过程省略,具体参考:Kubeadm方式搭建k8s集群 或 二进制方式搭建k8s集群
搭建完成后,查看集群:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready master 46h v1.14.0
master2 Ready master 46h v1.14.0
node1 Ready <none> 46h v1.14.0
node2 Ready <none> 46h v1.14.0
node3 Ready <none> 46h v1.14.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 部署es集群:
mkdir /elfk & cd /elfk
vim elasticsearch.yaml
- 1
- 2
- 3
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: kube-system
labels:
app: elasticsearch
spec:
selector:
app: elasticsearch
clusterIP: None
ports:
- name: api
port: 9200
- name: discovery
port: 9300
—
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: kube-system
spec:
serviceName: elasticsearch
replicas: 3
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
containers:
- name: elasticsearch
image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.6.2
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
ports:
- containerPort: 9200
name: api
protocol: TCP
- containerPort: 9300
name: discovery
protocol: TCP
env:
- name: “http.host”
value: “0.0.0.0”
- name: “network.host”
value: “eth0”
- name: “cluster.name”
value: “es-cluster”
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: “bootstrap.memory_lock”
value: “false”
- name: “discovery.seed_hosts”
value: “elasticsearch”
- name: “cluster.initial_master_nodes”
value: “elasticsearch-0,elasticsearch-1,elasticsearch-2”
- name: “discovery.seed_resolver.timeout”
value: “10s”
- name: “discovery.zen.minimum_master_nodes”
value: “2”
- name: “ES_JAVA_OPTS”
value: “-Xms512m -Xmx512m”
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
terminationGracePeriodSeconds: 30
volumes:
- name: data
hostPath:
path: /home/elasticsearch/data #该路径为es数据存储目录,自动创建
initContainers:
- name: fix-permissions
image: busybox
command: [“sh”, “-c”, “chown -R 1000:1000 /usr/share/elasticsearch/data”]
securityContext:
privileged: true
volumeMounts:
- name: data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
command: [“sysctl”, “-w”, “vm.max_map_count=262144”]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
command: [“sh”, “-c”, “ulimit -n 65536”]
securityContext:
privileged: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
为了方便,建议提前在所有node节点上拉取elasticsearch镜像:docker pull docker.elastic.co/elasticsearch/elasticsearch-oss:7.6.2。
kubectl apply -f elasticsearch.yaml
kubectl get pod -n kube-system |grep elasticsearch
NAME READY STATUS RESTARTS AGE
elasticsearch-0 1/1 Running 0 2m
elasticsearch-1 1/1 Running 0 75s
elasticsearch-2 1/1 Running 0 30s
kubectl get sts -n kube-system
NAME READY AGE
elasticsearch 3/3 2m24s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 部署kibana:
这里为了方便,直接使用NodePort暴露kibana端口。
vim kibana.yaml
- 1
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: kube-system
labels:
app: kibana
spec:
selector:
app: kibana
ports:
- port: 5601
nodePort: 30080
type: NodePort
—
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: kube-system
labels:
app: kibana
spec:
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- name: kibana
image: docker.elastic.co/kibana/kibana-oss:7.6.2
resources:
limits:
cpu: 1000m
requests:
cpu: 100m
env:
- name: ELASTICSEARCH_HOSTS
value: “http://elasticsearch:9200”
ports:
- containerPort: 5601
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
kubectl apply -f kibana.yaml
kubectl get pod -n kube-system |grep kibana
kibana-84d7449d95-r7h8w 1/1 Running 0 17s
kubectl get deploy -n kube-system |grep kibana
kibana 1/1 1 1 2m29s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
部署没问题的话,是可以正常访问kibana页面的,浏览器访问ip:30080,

- 以daemonset方式部署filebeat:
vim filebeat.yaml
- 1
apiVersion: v1 kind: ConfigMap metadata: name: filebeat-config namespace: kube-system labels: app: filebeat data: filebeat.yml: |- filebeat.config: inputs: path: ${path.config}/inputs.d/*.yml reload.enabled: falsemodules: path: ${path.config}/modules.d/*.yml reload.enabled: false output.elasticsearch: hosts: ['elasticsearch:9200'] username: elastic password: changeme
—
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-inputs
namespace: kube-system
labels:
app: filebeat
data:
kubernetes.yml: |-
- type: docker
containers.ids:
- “*”
processors:
- add_kubernetes_metadata:
in_cluster: true
fields:
log_topic: pod
—
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: filebeat
namespace: kube-system
labels:
app: filebeat
spec:
template:
metadata:
labels:
app: filebeat
spec:
serviceAccountName: filebeat
terminationGracePeriodSeconds: 30
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat-oss:7.6.2
args: [
“-c”, “/etc/filebeat.yml”,
“-e”,
]
env:
- name: ELASTICSEARCH_HOST
value: elasticsearch
- name: ELASTICSEARCH_PORT
value: “9200”
securityContext:
runAsUser: 0
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- name: config
mountPath: /etc/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: inputs
mountPath: /usr/share/filebeat/inputs.d
readOnly: true
- name: data
mountPath: /usr/share/filebeat/data
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: config
configMap:
defaultMode: 0600
name: filebeat-config
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers
- name: inputs
configMap:
defaultMode: 0600
name: filebeat-inputs
- name: data
hostPath:
path: /var/lib/filebeat-data
type: DirectoryOrCreate
—
apiVersion: v1
kind: ServiceAccount
metadata:
name: filebeat
namespace: kube-system
labels:
app: filebeat
—
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: filebeat
subjects:
- kind: ServiceAccount
name: filebeat
namespace: kube-system
roleRef:
kind: ClusterRole
name: filebeat
apiGroup: rbac.authorization.k8s.io
—
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRole
metadata:
name: filebeat
labels:
app: filebeat
rules:
- apiGroups: [""]
resources:
- namespaces
- pods
verbs:
- get
- watch
- list
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
kubectl apply -f filebeat.yaml
kubectl get ds -n kube-system
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
calico-node 5 5 5 5 5 <none> 47h
filebeat 3 3 3 3 3 <none> 14s
kube-proxy 5 5 5 5 5 <none> 47h
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
elfk部署完成,接下来部署应用程序,收集日志。
- 收集nginx日志:
vim nginx-demo.yaml
- 1
apiVersion: v1
kind: Service
metadata:
name: nginx
labels:
app: nginx
spec:
selector:
app: nginx
ports:
- port: 80
nodePort: 30090
type: NodePort
—
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
spec:
replicas: 1
minReadySeconds: 15
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
terminationGracePeriodSeconds: 30
containers:
- name: nginx
image: nginx:1.17.0
ports:
- containerPort: 80
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
kubectl apply -f nginx-demo.yaml
kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-6bdc8cdf4-wlt29 1/1 Running 0 65s
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 47h
nginx NodePort 10.100.239.214 <none> 80:30090/TCP 101s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
访问nginx页面以产生日志:ip:30090,
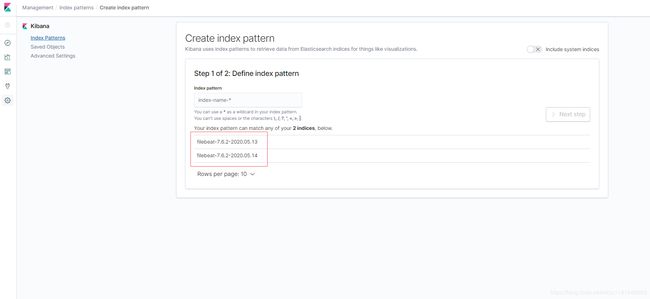
- kibana创建索引,查看nginx日志:
添加过滤条件kubernetes.labels.app: nginx后,显示nginx日志,
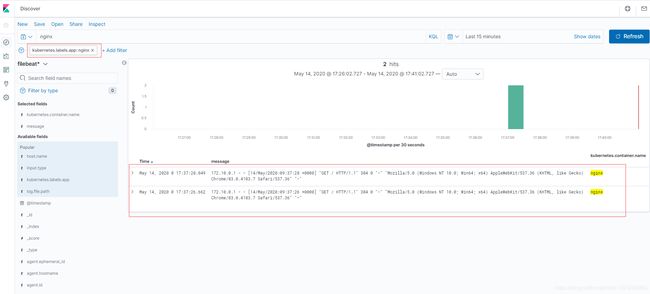
如果不添加过滤条件,则显示当前k8s集群及node节点产生的所有日志,

- 收集tomcat日志:
vim tomcat-demo.yaml
- 1
apiVersion: v1
kind: Service
metadata:
name: tomcat-test
labels:
app: tomcat-test
spec:
selector:
app: tomcat-test
ports:
- port: 8080
nodePort: 30100
type: NodePort
—
apiVersion: apps/v1
kind: Deployment
metadata:
name: tomcat-test
spec:
replicas: 1
minReadySeconds: 15
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
selector:
matchLabels:
app: tomcat-test
template:
metadata:
labels:
app: tomcat-test
spec:
terminationGracePeriodSeconds: 30
containers:
- name: tomcat
image: tomcat:8.0.51-alpine
ports:
- containerPort: 8080
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
kubectl apply -f tomcat-demo.yaml
kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-6bdc8cdf4-wlt29 1/1 Running 0 16m
tomcat-test-7845c7fd7b-9g4cn 1/1 Running 0 7s
kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 2d
nginx NodePort 10.100.239.214 <none> 80:30090/TCP 16m
tomcat-test NodePort 10.103.170.6 <none> 8080:30100/TCP 11s
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
访问tomcat页面以产生日志:ip:30100,
- kibana查看tomcat日志:
添加过滤条件kubernetes.labels.app: tomcat-test后,显示tomcat日志,

如果不添加过滤条件,则显示当前k8s集群及node节点产生的所有日志,
- 总结:
上面通过daemonset方式部署filebeat收集k8s日志,与使用log-pilot收集k8s日志原理上是一致的。
这种方式收集k8s日志很方便,但不足之处也很明显,日志是直接进行输出到es集群中的,无法进行多行合并、过滤处理,所有日志只能存在于一个以filebeat-version-%{+YYYY.MM.dd}命名的索引中,这是无法接受的。
或许这种方式可以进一步自定义index和日志过滤处理的,但我目前不知道而已,如果大家知道如何配置欢迎指导。
正因为上面方式的不足,所以在综合考虑后采取第2种方案:pod中附加一个日志收集容器。以sidecar方式部署filebeat,filebeat属于轻量级,资源消耗可以接受,这样一来就可以自定义index,而且可以输出日志数据到集群外的logstash进行日志的过滤处理,然后再由logstash将处理后的日志输出到es中。说到底,这种方案完全只需要filebeat以sidecar方式运行于k8s集群中,其余elk组件可以自由选择是否部署于k8s集群中。