Clustering By Fast Search And Find Of Density Peaks -- Sci14发表的聚类算法
This post is about a new cluster algorithm published by Alex Rodriguez and Alessandro Laio in the latest Science magazine. The method is short and efficient, I implemented it using about only 100 lines of cpp code.
BASIC METHOD
There are two leading criteria in this method: Local Density and Minimum Distance with higher density.
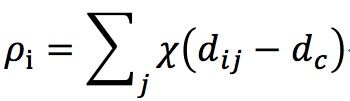
Rho above is the local density, in which,
and dc is a cutoff distance. Rho is basically equal to the number of points that are closer than dc to point i. The algorithm is sensitive only to the relative magnitude of rho in different points, implying that, for large data sets, the results of the analysis are robust with respect to the choice of dc.
The authors say that we can choose dc so that the average number of neighbors is around1 to 2% of the total number of points in the data set (I used 1.6% in my code).
Delta is measured by computing the minimum distance between the point i and any other point with higher density:
and for the point with highest density, we simply let:

The following figure illustrates the basic algorithm:

The left hand figure shows the dataset we use (28 points in a 2d space), most of the points belong to 2 clusters: blue and red, and there are 3 outliers with black circles. By calculating the rho and delta of each point in the dataset, we show the result by the right hand figure (decision graph), x-axis is local density, y-axis is the minimum distance between one point and any other point with higher density.
Our target is to find points that have both high rho and high delta (in this example point number 1 and 10), they’re cluster centers. We can see the three outliers (26, 27, 28) have high delta but very low rho.
CODE
-
// Science 27 June 2014:
-
// Vol. 344 no. 6191 pp. 1492-1496
-
// DOI: 10.1126/science.1242072
-
// http://www.sciencemag.org/content/344/6191/1492.full//
-
//
-
// Code Author: Eric Yuan
-
// Blog: http://eric-yuan.me
-
// You are FREE to use the following code for ANY purpose.
-
//
-
// Have fun with it
-
-
#include "iostream"
-
#include "vector"
-
#include "math.h"
-
using namespace std;
-
-
#define DIM 3
-
#define elif else if
-
-
#ifndef bool
-
#define bool int
-
#define false ((bool)0)
-
#define true ((bool)1)
-
#endif
-
-
struct Point3d {
-
double x;
-
double y;
-
double z;
-
Point3d ( double xin, double yin, double zin ) : x (xin ), y (yin ), z (zin ) { }
-
};
-
-
void dataPro (vector <vector > &src, vector &dst ) {
-
for ( int i = 0; i < src. size ( ); i ++ ) {
-
Point3d pt (src [i ] [ 0 ], src [i ] [ 1 ], src [i ] [ 2 ] );
-
dst. push_back (pt );
-
}
-
}
-
-
double getDistance (Point3d &pt1, Point3d &pt2 ) {
-
double tmp = pow (pt1. x - pt2. x, 2 ) + pow (pt1. y - pt2. y, 2 ) + pow (pt1. z - pt2. z, 2 );
-
return pow (tmp, 0.5 );
-
}
-
-
double getdc (vector &data, double neighborRateLow, double neighborRateHigh ) {
-
int nSamples = data. size ( );
-
int nLow = neighborRateLow * nSamples * nSamples;
-
int nHigh = neighborRateHigh * nSamples * nSamples;
-
double dc = 0.0;
-
int neighbors = 0;
-
cout < < "nLow = " < <nLow < < ", nHigh = " < <nHigh < <endl;
-
while (neighbors < nLow || neighbors > nHigh ) {
-
//while(dc <= 1.0){
-
neighbors = 0;
-
for ( int i = 0; i < nSamples - 1; i ++ ) {
-
for ( int j = i + 1; j < nSamples; j ++ ) {
-
if (getDistance (data [i ], data [j ] ) < = dc ) ++neighbors; if (neighbors > nHigh ) goto DCPLUS;
-
}
-
}
-
DCPLUS : dc += 0.03;
-
cout < < "dc = " < <dc < < ", neighbors = " < <neighbors < <endl;
-
}
-
return dc;
-
}
-
-
vector getLocalDensity (vector &points, double dc ) {
-
int nSamples = points. size ( );
-
vector rho (nSamples, 0 );
-
for ( int i = 0; i < nSamples - 1; i ++ ) {
-
for ( int j = i + 1; j < nSamples; j ++ ) {
-
if (getDistance (points [i ], points [j ] ) < dc ) {
-
++rho [i ];
-
++rho [j ];
-
}
-
}
-
//cout<<"getting rho. Processing point No."<<i<<endl;
-
}
-
return rho;
-
}
-
-
vector getDistanceToHigherDensity (vector &points, vector &rho ) {
-
int nSamples = points. size ( );
-
vector delta (nSamples, 0.0 );
-
-
for ( int i = 0; i < nSamples; i ++ ) {
-
double dist = 0.0;
-
bool flag = false;
-
for ( int j = 0; j < nSamples; j ++ ) { if (i == j ) continue; if (rho [j ] > rho [i ] ) {
-
double tmp = getDistance (points [i ], points [j ] );
-
if ( !flag ) {
-
dist = tmp;
-
flag = true;
-
} else dist = tmp < dist ? tmp : dist;
-
}
-
}
-
if ( !flag ) {
-
for ( int j = 0; j < nSamples; j ++ ) { double tmp = getDistance (points [i ], points [j ] ); dist = tmp > dist ? tmp : dist;
-
}
-
}
-
delta [i ] = dist;
-
//cout<<"getting delta. Processing point No."<<i<<endl;
-
}
-
return delta;
-
}
-
-
int main ( int argc, char ** argv )
-
{
-
long start, end;
-
FILE *input;
-
input = fopen ( "dataset.txt", "r" );
-
vector <vector > data;
-
double tpdouble;
-
int counter = 0;
-
while ( 1 ) {
-
if (fscanf (input, "%lf", &tpdouble ) ==EOF ) break;
-
if (counter / 3 > = data. size ( ) ) {
-
vector tpvec;
-
data. push_back (tpvec );
-
}
-
data [counter / 3 ]. push_back (tpdouble );
-
++ counter;
-
}
-
fclose (input );
-
//random_shuffle(data.begin(), data.end());
-
-
start = clock ( );
-
cout < < "********" < <endl;
-
vector points;
-
dataPro (data, points );
-
double dc = getdc (points, 0.016, 0.020 );
-
vector rho = getLocalDensity (points, dc );
-
vector delta = getDistanceToHigherDensity (points, rho );
-
// saveToTxt(rho, delta);
-
// now u get the cluster centers
-
end = clock ( );
-
cout < < "used time: " < < ( ( double ) (end - start ) ) / CLOCKS_PER_SEC < <endl;
-
return 0;
-
}
PostScript: I found that the result differs a lot when using different value of dc, If you have any idea of how to calculate dc precisely, please let me know.
Newly Updated: Jul. 1 9:14 Pm
Ryan raised an interesting idea yesterday and I tried it.
ryan
Here’s the new function to calculate “Local Density”:
-
double ratio = 0.015;
-
int nSamples = points. size ( );
-
int M = nSamples * ratio;
-
vector rho (nSamples, 0.0 );
-
for ( int i = 0; i < nSamples; i ++ ) {
-
vector tmp;
-
for ( int j = 0; j < nSamples; j ++ ) {
-
if (i == j ) continue;
-
double dis = getDistance (points [i ], points [j ] );
-
if (tmp. empty ( ) ) {
-
tmp. push_back (dis );
-
}elif (tmp. size ( ) < M ) {
-
if (dis < = tmp [tmp. size ( ) - 1 ] ) tmp. push_back (dis );
-
else {
-
for ( int k = 0; k < tmp. size ( ); k ++ ) {
-
if (tmp [k ] < = dis ) { tmp. insert (tmp. begin ( ) + k, dis ); break; } } } } else { if (dis > = tmp [ 0 ] ) {
-
; // do nothing
-
}elif (dis < = tmp [tmp. size ( ) - 1 ] ) {
-
tmp. erase (tmp. begin ( ) );
-
tmp. push_back (dis );
-
} else {
-
for ( int k = 0; k < tmp. size ( ); k ++ ) {
-
if (tmp [k ] < = dis ) {
-
tmp. insert (tmp. begin ( ) + k, dis );
-
tmp. erase (tmp. begin ( ) );
-
break;
-
}
-
}
-
}
-
}
-
}
-
double res = 0.0;
-
for ( int j = 0; j < tmp. size ( ); j ++ ) {
-
res += tmp [j ];
-
}
-
rho [i ] = 0 - res / tmp. size ( );
-
}
-
return rho;
-
}
Because the mean distance to nearest M neighbors is inversely proportional to density, so I add a “y = -x” in the end.
I tested this idea using four dataset:
- Aggregation: 788 vectors, 2 dimensions, 7 clusters.
- Spiral: 312 vectors, 2 dimensions, 3 clusters
- Jain: 373 vectors, 2 dimensions, 2 clusters
- Flame: 240 vectors, 2 dimensions, 2 clusters
And the result is as follow (Ryan’s idea in red circles, method in paper in blue circles):
Jain:

Spiral:
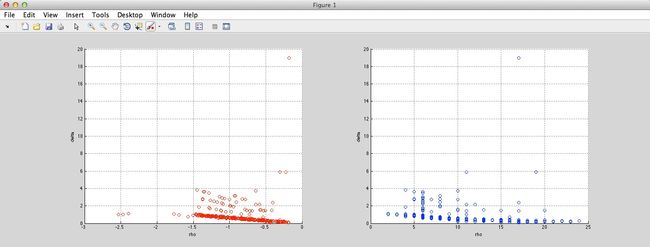
Flame:
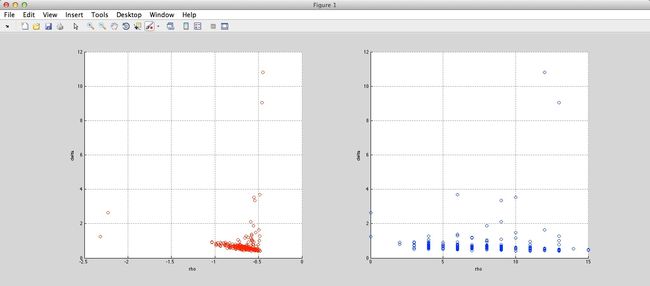
Aggregation:
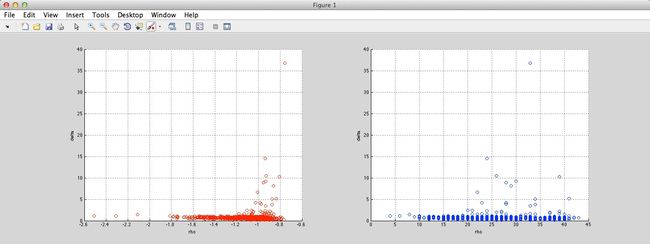
Actually Ryan’s method works well, but just like I replied him, how to get a proper “M” is still like black magic.
If anyone has any idea, please let me know.
Thanks Ryan.
原文:http://eric-yuan.me/clustering-fast-search-find-density-peaks/
备注:
对于作者原来的论文里面有一个超参 (d_c) 设置会影响效果;但该算法能处理不同密度的簇。
对于Ryan's 的方法,同样的M=#sample * 0.015 也是一个经验值,需要设定或调节。但这个方法貌似比较好。
文献出处:
http://www.52ml.net/16351.html
http://www.52ml.net/16296.html (中文)