LZW字典压缩
什么是LZW字典压缩
LZW字典压缩的精髓就是通过字典去记录一些出现频次比较高的词汇,并在存储的时候把一些词汇用特定的数去表示。如果一个字符串“ab”出现的频次很高,若采用直接用字符的方式去存储(字符的编码范围是0~65536,两个字节)需要4个字节,那么它出现10次就要占用40个字节;如果我们规定一个数来表示“ab”,比如256,256需要占用两个字节的存储空间,使用10次需要20个字节,和前者相比可以节省一半的存储空间,这就是字典压缩的好处。我们可以把在文件中写数据,看成在文件中写一些字符串的索引,要得到具体内容,通过字典去对应就可以了。
如何实现字典
LZW字典压缩可以理解为一种人为编写的协议,具体的实现也是基于字节中的数据的存储和解读。我们知道:0 ~ 255对应了ASCII码的256种符号,这也是我们翻译的一个基石,之后的编码都对应于之前的一些字符的组合,在英文文章的实现上,使用 0 ~ 255的字符就足够了,我们在使用字典前会先加载256个字符的键值对信息。接下来,我们需要充分利用剩下的256 ~ 65535的这些编码,人为规定它们代表的意义,就比如上文提到的用256来表示“ab”。这里我们可以使用HashMap来存储字符串和编码,在写字符信息时,可以用之前出现过的字符串对应的编码来代替。既然两个字节能表示的编码上限是65535,那么当编码达到这个数的时候,我们就需要把编码表清空,复原到只含有256个键值对的初始状态,然后继续之前的操作。
如何压缩
我们用例子来说话:
这里给出一个字符串:ababaabbababaabb
我们来模拟一下它压缩的动态过程:
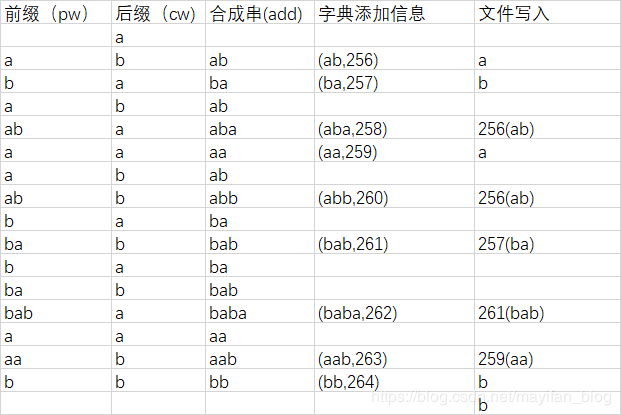
注:在这个过程前我们已经读取文件,获取了文件的所有字节,并把它转化为一个字符串,接下来我们逐个取出字符串中的字符。
简述一下压缩和字典生成的流程:
1、 获取第一个字符a,不做操作,把它作为下一次操作的前缀(这里后缀指该次读到的字符)。
2、读取下一个字符b作为后缀,把前缀a和后缀b连接起来,得到合成字符串,判断字典是否有次字符串对应的信息,如果没有,则添加此字符串和编码(编码从256开始分配,每次加1)到字典。同时写入a到压缩文件。把后缀a作为下一次操作的前缀。
3、读取下一个字符a,同上,我们把ba加入字典并写b。
4、读取下一个字符b,此时合成字符串为ab,我们发现在字典中存在该索引,我们不急着把它输出,再去尝试看看这个常用的字符串能不能拼接为一个更长的字符串作为索引存入字典,我们把这个合成串作为下一次操作的前缀。
5、读取下一个字符a,合成字符串aba,字典中没有它的索引,所以我们把它存入字典,并写出之前的ab(此时ab已经用256代替了,我们向文件写一个256表示的字节就可以了,用二进制表示是:0000000100000000),然后把a作为前缀。
6、接下来的操作都和上方类似,读者可以自行阅读表格。
7、最后别忘了把最后一个字符写到文件。
如何解压
大家看到这里可能会疑惑,我们只是写了一串字符,而且有些地方还是用大于255的字符表示,如何解压呢?如何知道256,257这些数字背后的含义呢?
我们之前提到过,所有的操作都是基于那0~255的字符的压缩,这些字符就是我们的标准,虽然我们没有把字典写入文件,但是我们可以通过256个基本的字符去逐个破解256,257这些数字背后的意义。
解压时,我们先把压缩文件读出来,此时它是这样的:a、b、256、a、256、257、261、259、b、b
之前在压缩的时候我们知道256是对应ab,这里我们只要读了前两个字符,就可以推出256的索引了,然后依据一定的规则,可以还原为原字符串。
我们还是通过表格来演示这个过程:

解压和还原的思路类似,依然是逐个字符去读取,只是这里需要把字节编码转为对应的字符串,然后写出去。
接下来详解一下步骤:
1、读取第一个字符a,并写入解压目录下的文件。把a作为下一次操作的前缀。
2、读取下一个字符b,合成串ab,字典中不存在ab,则添加进字典,写b。
3、读取下一个字符(256),在字典中查询到256对应为ab,取出ab并写到文件,合成字符是前缀和后缀的第一个字符相加(得到ba),查询到字典中不存在ba,则添加ba到字典。把后缀ab作为下一次操作的前缀。
4、读取下一个字符a,合成得到aba,字典中无aba则添加到字典,写入a。把a作为下一次操作的前缀。
5、接下来的操作类似,我们直接看前缀为257,后缀为261的这行,前缀对应ba字符串,而后缀261在字典中找不到,此时,我们需要从前缀去推导后缀的组成,cw=pw+pw.charAt(0),得到cw并写cw,合成串是bab(ba+b)。
6、重复以上操作和判断即可把数据还原并写入解压目录。
简单小结解压:每次读到的数据都直接写入文件,即读什么写什么;当读到的字符在字典中没有索引,需要通过前缀推导。
程序流程
1、第一次读取文件,数据存到字节数组,缓冲数组转字符串。
2、逐个字符读取字符串并写文件,写文件的同时生成字典,得到压缩文件。
3、读取压缩文件,数据存到字节数组。
4、保存字节数组中每个字符的高八位信息。
5、遍历低八位,通过高八位判断数据转化方式,得到每一个字符对应的整数表示并存到队列。
6、逐个取出队列中的数据,写入解压目录,同时生成字典,得到解压后的文件。
代码实现(Java)
1、压缩类:
public class Compress {
HashMap<String, Integer> map = new HashMap<>();//压缩时的编码表
String pre = ""; //前缀
String suf = ""; //后缀
String add = ""; //连接字符串,作为中间参数
int code = 256; //从256开始编码,255~65535
/**
* 读取文件数据,获取待处理字符串
*/
public String read(File file1)
{
String str="";
try
{
InputStream is = new FileInputStream(file1);
byte[] buffer = new byte[is.available()];//根据字节数建立缓冲区
is.read(buffer); //一次性把文件读到buffer缓冲区
str = new String(buffer); //字节数组转字符串
is.close();
}
catch(IOException e)
{
e.printStackTrace();
}
return str;
}
/**
* 对字符串处理,生成LZW编码表,同时写入压缩文件
*/
public void write(String str,File file2)
{
for(int i=0;i<256;i++) //把256个字符放入码表
{
String a = (char)i+"";
map.put(a, i);
}
try
{
OutputStream out = new FileOutputStream(file2); //向上转型
DataOutputStream dos = new DataOutputStream(out); //数据输出流
pre = str.charAt(0)+""; //把第一个字符作为前缀
for(int i=1;i<str.length();i++)
{
if(code==65535) //编码数量过多,需要清空map
{
System.out.println("重置");
dos.writeInt(65535); //写一个信号表示清零
map.clear(); //清空
code=256; //计数置256
pre=""; //前缀置空
for(int j=0;j<256;j++) //把256个字符放入码表
{
String a = (char)j+"";
map.put(a, j);
}
}
suf=str.charAt(i)+""; //获取后缀字符
add=pre+suf; //连接
if(map.get(add)==null) ///map在不存在该字符串,则把该字符串写入
{
System.out.println("合成字符串:"+add);
System.out.println("对应编码:"+code);
map.put(add,code); //把当前字符串作为字典存入哈希表,从256开始
add=""; //清空中间字符串
System.out.println("写入的前缀:"+pre);
System.out.println("它的编码:"+map.get(pre));
if(pre.length()==1)
dos.writeChar(pre.charAt(0));
else
dos.writeChar(map.get(pre));
pre=suf;
code++;
}
else
{
pre=add; //已存在于map,则继续判断,把它作为前缀
}
if(i==str.length()-1)
{
System.out.println("最后的字符:"+pre);
System.out.println("写入的编码:"+map.get(pre));
if(pre.length()==1)
dos.writeChar(pre.charAt(0));
else
dos.writeChar(map.get(pre));
}
}
dos.close();
//System.out.print("输出码表:"+map.toString());
}
catch(IOException e)
{
e.printStackTrace();
}
}
/**
* 压缩文件的对外接口
*/
public void compress(File file1,File file2)
{
String str =read(file1);
System.out.println("从文件中读取到字符串:"+str);
write(str,file2);
}
}
2、解压类:
public class Uncompress {
HashMap< String,Integer> map = new HashMap<>(); //存储在解压过程中生成的字典 ,字符串查编码
HashMap<Integer, String> map1 = new HashMap<>(); //存储在解压过程中生成的字典,编码查字符串
ArrayList<Integer> highlist = new ArrayList<>(); //存放高八位对应的数值
ArrayList<Integer> numlist = new ArrayList<>(); //存放获得的每一个字符的数据,存放的是int值
String pw = ""; //前缀
String cw =""; //后缀
String add=""; //合成字符串
int code=256;
/**
* 从压缩文件中还原得到字符串和哈希表
* @param file2
*/
public byte[] getStr(File file2)
{
String str="";
try
{
InputStream is = new FileInputStream(file2);
byte[] buffer = new byte[is.available()];
is.read(buffer);
str = new String(buffer);
System.out.println("获得的字符串:"+str);
is.close();
return buffer;
}
catch(IOException e)
{
e.printStackTrace();
}
return null;
}
/**
* 通过字符串获取字典并解压,写入目标文件
*/
public void writeStr(File file3,byte[] buffer)
{
int count=0;
for(int i=0;i<256;i++) //添加基本ascii字符进入码表
{
String a = (char)i+"";
map1.put(i, a);
map.put(a, i);
}
for(int i=0;i<buffer.length;i+=2) //存储高八位
{
int a = buffer[i];
highlist.add(a);
}
for(int i=1;i<buffer.length;i+=2) //依次取出低八位,结合高八位信息转化为对应实际字符对应的数值
{
if(buffer[i]==-1&&buffer[i-1]==-1)//读到清表信息
{
System.out.println("读到清表信息");
numlist.add(65525);
}
else
{
if(highlist.get(count)>0) //高八位有数据,则其为编码数据
{
System.out.println("高八位有数据");
System.out.println("高八位数据:"+highlist.get(count));
System.out.println("低八位数据:"+buffer[i]);
if(buffer[i]>=0) //字节数据为正,可以直接用,低八位加上高八位*256
{
System.out.println("字节数据为正");
int a=buffer[i]+256*highlist.get(count);
numlist.add(a);
System.out.println("添加数据:"+a);
System.out.println("");
}
else //字节数据为负,加上256转为正,再加高位数据
{
System.out.println("字节数据为负");
int a=buffer[i]+256+256*highlist.get(count);
numlist.add(a);
System.out.println("添加数据:"+a);
}
}
else //高八位全为0,则其为普通ASCII数据
{
System.out.println("高八位全为0");
if(buffer[i]>0) //字节数据为正,可以直接用
{
System.out.println("字节数据为正");
int a=buffer[i];
numlist.add(a);
System.out.println("添加数据:"+a);
}
else //字节数据为负,加上256转为正
{
System.out.println("字节数据为负");
int a=buffer[i]+256;
numlist.add(a);
System.out.println("添加数据:"+a);
}
}
}
count++;
}
try
{
OutputStream os = new FileOutputStream(file3); //获取文件输出流
for(int i=0;i<numlist.size();i++) //逐个取出字符数据,编码输出
{
int n = numlist.get(i); //获取字符对应数值
System.out.println("读到的字符值:"+n);
if(map.containsValue(n)) //字典中存在
{
System.out.println("字典中存在");
cw=map1.get(n); //获取对应字符串作为当前字符串
if(pw!="") //判断前缀不为空
{
System.out.println("前缀不为空");
System.out.println("查询当前字典");
add=pw+cw.charAt(0); //合成组合词
System.out.println("上一个:"+pw);
System.out.println("当前:"+cw);
System.out.println("合成:"+add);
System.out.println("code:"+code);
map1.put(code,add ); //更新词典
map.put(add, code);
code++;
os.write(cw.getBytes("GBK")); //写当前读到的那个字符串
System.out.println("写入:"+cw);
}
else //前缀为空,是第一个字符,直接写
{
System.out.println("前缀为空,第一个字符");
os.write(cw.getBytes("GBK")); //把字符按照两个字节的单位写出去
System.out.println("写入:"+cw);
}
}
else //字典中不存在,则从前缀中获取信息得到当前数字对应的字符串,写入文件并写入字典
{
System.out.println("字典中不存在");
System.out.println("pw:"+pw);
cw=pw+pw.charAt(0);
map.put(cw, code); //两表对应增加字典内容
map1.put(code, cw);
code++;
os.write(cw.getBytes("GBK")); //写出当前字符串内容
System.out.println("写入:"+cw);
}
pw=cw; //当前的字符串变为下一次循环的前缀
if(map1.size()==65535||map.size()==65535) //编码溢出,重置哈希表
{
map1.clear();
map.clear();
for(int j=0;j<256;j++)
{
map.put((char)j+"", j);
map1.put(j, (char)j+"");
}
code=256;
pw="";
}
}
os.close(); //关闭资源
}
catch(IOException e)
{
e.printStackTrace();
}
}
public void uncompress(File file2,File file3)
{
byte[] buffer = getStr(file2); //解压文件,获取字符串
writeStr(file3,buffer); //写文件
}
}
3、测试类:
public class Test {
public static void main(String[] args)
{
Compress com = new Compress();
Uncompress ucom = new Uncompress();
File file1 = new File("E:\\workspace\\mayifan\\src\\com\\myf\\lzwcompress1227\\data1.txt"); //带压缩的文件
File file2 = new File("E:\\workspace\\mayifan\\src\\com\\myf\\lzwcompress1227\\data2.txt"); //压缩生成文件
File file3 = new File("E:\\workspace\\mayifan\\src\\com\\myf\\lzwcompress1227\\data3.txt"); //解压目录文件
com.compress(file1,file2); //文件压缩的方法
ucom.uncompress(file2, file3);//文件解压方法
}
}
4、例题压缩解压效果:
data1是原文件,data3是解压后的文件。

5、英文文段解压、压缩解压效果:

一些细节
1、在IO流中我们使用write()方法把int值写入是等同于其在ASCII中对应的字符写入。在这里字节、字符、整数三者在某种意义上等价,范围在0 ~ 255 ,字节中的数据从00000000 ~ 11111111,其中每一个编码对应一个char字符,也对应了一个整数值。这里,int的使用,默认是无符号的,即都是正数。但是这仅限于IO中的字节操作。计算机中字节运算是补码运算,Java的字节有正负,范围是-128 ~ 127 ,字节的最高位是符号位,0表示正数,1表示负数,其余位数取反加一得到模值的大小。所以,在字节数据转int之后是可能出现负值的,而我们不希望出现负值,那么就要对数据做一些处理,得到我们需要的值,具体内容可以参照代码。
2、LZW字典压缩这种方法是针对重复出现的字符构成的串而设计的压缩方案。可靠的部分是0 ~ 255部分,其余编码是我们自己定义的,如果我们读取了中文字符,会和自己编码的字符产生冲突,所有,如果要应用于中文压缩,方法还有待改进。
3、当字典容量超过65535时需要我们对字典进行复原处理,不然会出现错误。