Python知乎专栏爬虫,pdfkit专栏文章制作PDF电子书
虽然一直说逼乎比较水,大概是由于我这种渣渣太多了,但不可否认,还是存在质量度比较高文章,专栏,毕竟逼乎有着比较高质量的韭菜,收割起来尤其畅快,反复收割都不是问题,这可是人人月入十万的比乎。
本渣渣没事搜索pyqt5教程,手机搜索,找到了这个专栏,PyQt5图形界面编程,看了下很适合本渣渣学习,so,这就有了下面这篇文章,打算写个爬虫,使用pdfkit把专栏文章制作PDF电子书慢慢看(发csdn赚个分)!
专栏地址:
https://zhuanlan.zhihu.com/xdbcb8
目录页地址:
https://zhuanlan.zhihu.com/p/48373518
目录地址,就是爬取的入口

搞起来,fake_useragent库伪装ua协议头,发现十次有两三次被挂比,不愧是比乎,协议头验证得比较到位。
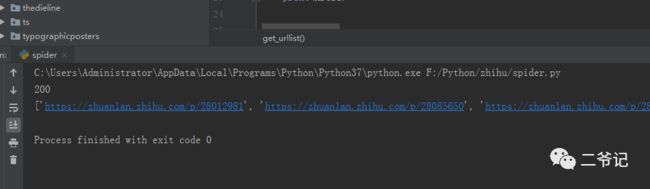
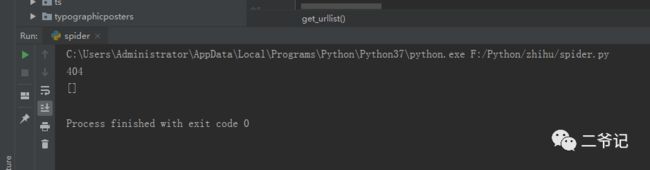
运行十次效果

附参考代码:
#https://zhuanlan.zhihu.com/p/48373518
#20200615 by 微信:huguo00289
# -*- coding: UTF-8 -*-
import requests,time
from fake_useragent import UserAgent
from lxml import etree
def get_urllist():
ua=UserAgent()
headers={
'user-agent':ua.random,
}
url="https://zhuanlan.zhihu.com/p/48373518"
response=requests.get(url,headers=headers,timeout=5)
print(response.status_code)
time.sleep(2)
html=response.content.decode('utf-8')
req=etree.HTML(html)
hrefs=req.xpath('//div[@class="RichText ztext Post-RichText"]/ul//a/@href')
print(hrefs)
if __name__=='__main__':
for i in range(1,11):
get_urllist()
没办法了,用自己浏览器的ua吧,要不然写报错?
暂时发现cookies头影响不大,把整个专栏文章爬取一次,没有发现异常,而且网页结构很规范,可能这里抓取的内容没有深入。
关键点:
1.etree把节点返回为html代码
h1=etree.tostring(h1,encoding='utf-8').decode('utf-8')这里需要去调试输出正确的html代码
2.pdfkit的使用
与一样selenium需要进行安装配置
首先定义调用路径/地址
confg = pdfkit.configuration(wkhtmltopdf=r'C:\Users\Administrator\AppData\Local\Programs\Python\Python37\wkhtmltox\bin\wkhtmltopdf.exe')配置参数
options = {
'page-size': 'A4',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'outline': None,
}
pdfkit.from_string(datas, r'out.pdf',options=options,configuration=confg)
运行效果:


PDF电子书效果:
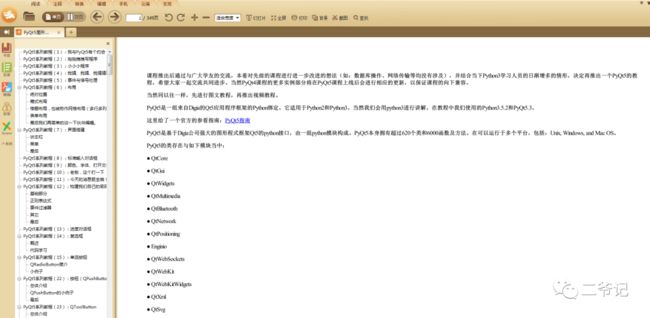
附参考代码:
#https://zhuanlan.zhihu.com/p/48373518
#20200615 by 微信:huguo00289
# -*- coding: UTF-8 -*-
import requests,time
from fake_useragent import UserAgent
from lxml import etree
import pdfkit
confg = pdfkit.configuration(wkhtmltopdf=r'C:\Users\Administrator\AppData\Local\Programs\Python\Python37\wkhtmltox\bin\wkhtmltopdf.exe')
def get_urllist():
ua=UserAgent()
headers={
'user-agent':ua.random,
#'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
#'cookie': 'SESSIONID=tPiQ2FpwANFw2tVR91VkmgEd5OHTxWSzjXpOB861nqq; JOID=UV8SBE3hul2soItWA-ULhKLMOToWiYsX3ufdBG-i8xTCkvkjdPW3u_ahj1YCSli_gQ4Fs3mJdFAfWYxxC2OzOdM=; osd=U14cBk7ju1Ouo4lXDecIhqPCOzkUiIUV3eXcCm2h8RXMkPohdfu1uPSggVQBSFmxgw0HsneLd1IeV45yCWK9O9A=; _zap=d55f3e6d-080a-4581-b3d3-c2a3698688aa; d_c0="AMCqkldLeg-PTtyw-z_gAIP5PcjeFBCdsJo=|1558685069"; __gads=ID=528a3696428a9d32:T=1558685297:S=ALNI_MZ9VGoTrHsNgTUcKt7Pw-nt0MfRZA; _xsrf=DJsB0m4gygVwX2u42LFqERf0llZT1t6X; tst=r; _ga=GA1.2.1869194376.1583723562; z_c0=Mi4xX09zZUdRQUFBQUFBd0txU1YwdDZEeGNBQUFCaEFsVk5Hc21DWHdDTjlBUXhJOHZEUmhLRTdyMUYxcnVLblc5Xzd3|1586854682|2b1575f2d3331cb3eb1327b1e6e0afd8fa7fe5fd; __utma=51854390.1869194376.1583723562.1586158626.1588234855.7; __utmz=51854390.1588234855.7.7.utmcsr=zhihu.com|utmccn=(referral)|utmcmd=referral|utmcct=/; __utmv=51854390.100-1|2=registration_date=20200213=1^3=entry_date=20190524=1; q_c1=116807e43ab24320baa102068d5541f3|1591838671000|1558685083000; _gid=GA1.2.1281198261.1592183078; Hm_lvt_98beee57fd2ef70ccdd5ca52b9740c49=1592189701,1592193127,1592199976,1592200401; KLBRSID=975d56862ba86eb589d21e89c8d1e74e|1592200462|1592200461; Hm_lpvt_98beee57fd2ef70ccdd5ca52b9740c49=1592200463',
}
url="https://zhuanlan.zhihu.com/p/48373518"
response=requests.get(url,headers=headers,timeout=5)
print(response.status_code)
time.sleep(2)
html=response.content.decode('utf-8')
req=etree.HTML(html)
hrefs=req.xpath('//div[@class="RichText ztext Post-RichText"]/ul//a/@href')
print(hrefs)
return hrefs
def get_content(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36',
}
response = requests.get(url, headers=headers, timeout=5)
print(response.status_code)
time.sleep(2)
html = response.content.decode('utf-8')
req=etree.HTML(html)
h1=req.xpath('//h1[@class="Post-Title"]')[0]
h1=etree.tostring(h1,encoding='utf-8').decode('utf-8')
#print(h1)
article=req.xpath('//div[@class="RichText ztext Post-RichText"]')[0]
article = etree.tostring(article, encoding='utf-8').decode('utf-8')
#print(article)
content='%s%s'%(h1,article)
print(content)
return content
def dypdf(datas):
#datas = f'{datas}'
datas=f'''
{datas}
'''
print("开始打印内容!")
options = {
'page-size': 'A4',
'margin-top': '0.75in',
'margin-right': '0.75in',
'margin-bottom': '0.75in',
'margin-left': '0.75in',
'encoding': "UTF-8",
'outline': None,
}
pdfkit.from_string(datas, r'out.pdf',options=options,configuration=confg)
print("打印保存成功!")
def main():
datas=''
urls=get_urllist()
for url in urls:
content=get_content(url)
datas='%s%s'%(datas,content)
dypdf(datas)
if __name__=='__main__':
main()
比较可惜的是专栏文章效果都是动图gif,打印成pdf图片都是无法显示!!
暂时没有找到解决方案!
如果想要获取该pdf电子书
可关注我微信公众号 :二爷记

回复 电子书 获取!