Python3(廖雪峰教程)
Python之前学过简明教程,现在再系统的学一下,本博客属于廖雪峰Python教程的重点总结。
第一章 Python基础
一、数据类型
- 整数:十六进制整数用0x前缀表示,数据内容用0-9的数字和a-f的字母表示,例如数字:0xff00。(注:0x中0是数字零,不是字母o)
- 浮点数:浮点数也就是小数,它的小数点位置是可变的,例如:2.3x10==0.23x100。当浮点数很大或很小的浮点数,将10用e替代,1.23x10^9就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。浮点数在计算机运算中存在四舍五入的误差。
- 字符串:字符串是以’ ‘或" "括起来的任意文本,比如’abc’,“xyz”。
- 布尔值:一个布尔值只有True、False两种值,要么是True,要么是False(注:开头大写!)
- 空值:空值用None表示,None不能理解为0,因为0是有意义的,而None是一个特殊的空值。
二、print语句
print语句也可以跟上多个字符串,用逗号“,”隔开,打印“,”时打印出一个空格,这样可以将所有字符串连成一串输出:
print ('The quick brown fox', 'jumps over', 'the lazy dog')
The quick brown fox jumps over the lazy dog
三、注释语句
pycharm注释快捷键:Ctrl + /
四、变量
Python是动态语言,在定义变量是不需要指定变量类型,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如Java是静态语言。
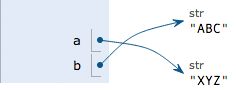
变量在计算机内存中的表示也非常重要。当我们写:a = 'ABC’时,Python解释器干了两件事情:
- 在内存中创建了一个’ABC’的字符串;
- 在内存中创建了一个名为a的变量,并把它指向’ABC’。
也可以把一个变量a赋值给另一个变量b,这个操作实际上是把变量b指向变量a所指向的数据,例如下面的代码:
a = 'ABC'
b = a
a = 'XYZ'
print b
最后b 依旧是‘ABC’,动态图如下:
五、字符串
- 当表示字符串:I’m OK,外面用“ ”,“I’m OK”。
- 当表示字符串:Learn “Python” in imooc,外面用‘ ’,‘Learn “Python” in imooc’。
- 当表示字符串:Bob said “I’m OK”,用转移字符串,外面“ ” 和‘ ’都可以,"Bob said “I’m OK”.”。
- 当字符串中含有多个需要转义字符时,前面加r: r’(_)/ (_)/’
- 当有多行转义字符时:r加三个单引号组成。
r'''Line 1
Line 2
Line 3'''
六、列表list
Python内置的一种数据类型是列表:list。list是一种有序的集合,可以随时添加和删除其中的元素。
- 把元素插入到指定的位置,比如索引号为1的位置:
>>> classmates.insert(1, 'Jack')
>>> classmates
['Michael', 'Jack', 'Bob', 'Tracy', 'Adam']
- 删除指定位置的元素,用pop(i)方法,其中i是索引位置:
>>> classmates.pop(1)
'Jack'
>>> classmates
['Michael', 'Bob', 'Tracy']
- list可以嵌套其他list,索引是相当于二位数组
七、元组tuple
tuple和list非常类似,但是tuple一旦初始化就不能修改
- 要定义一个只有1个元素的tuple
>>> t = (1)
>>> t
1
以上定义的不是tuple,是1这个数!这是因为括号()既可以表示tuple,又可以表示数学公式中的小括号,这就产生了歧义,因此,Python规定,这种情况下,按小括号进行计算,计算结果自然是1。
只有1个元素的tuple定义时必须加一个逗号,,来消除歧义:
>>> t = (1,)
>>> t
(1,)
- ‘’可变’’的tuple
>>> t = ('a', 'b', ['A', 'B'])
>>> t[2][0] = 'X'
>>> t[2][1] = 'Y'
>>> t
('a', 'b', ['X', 'Y'])
解释:
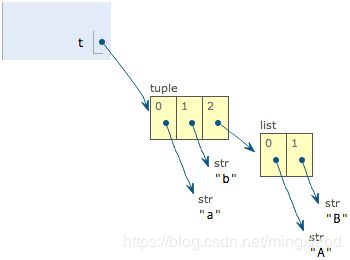
当我们把list的元素’A’和’B’修改为’X’和’Y’后,tuple变为:
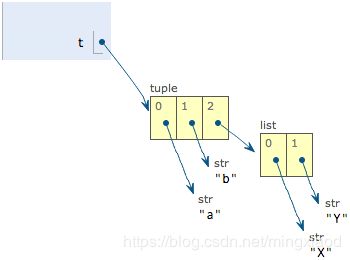
表面上看,tuple的元素确实变了,但其实变的不是tuple的元素,而是list的元素。tuple一开始指向的list并没有改成别的list,所以,tuple所谓的“不变”是说,tuple的每个元素,指向永远不变。即指向’a’,就不能改成指向’b’,指向一个list,就不能改成指向其他对象,但指向的这个list本身是可变的!
八、条件判断
看一个有问题的条件判断。很多同学会用input()读取用户的输入,这样可以自己输入,程序运行得更有意思:
birth = input('birth: ')
if birth < 2000:
print('00前')
else:
print('00后')
输入数字1982,结果报错:
Traceback (most recent call last):
File "", line 1, in
TypeError: unorderable types: str() > int()
这是因为input()返回的数据类型是str,str不能直接和整数比较,必须先把str转换成整数。Python提供了int()函数来完成这件事情:
s = input('birth: ')
birth = int(s)
if birth < 2000:
print('00前')
else:
print('00后')
再次输入数字运行,就可以得到正确地结果。
九、循环
for…in循环,依次把list或tuple中的每个元素迭代出来,
names = ['Michael', 'Bob', 'Tracy']
for name in names:
print(name)
十、字典 dic
避免key不存在的错误,有两种办法:
- 通过in判断key是否存在:
d = {'Michael': 95, 'Bob': 75, 'Tracy': 85}
'Thomas' in d
False
- 通过dict提供的get()方法,如果key不存在,可以返回None,或者自己指定的value:
>>> d.get('Thomas')
>>> d.get('Thomas', -1)
-1
注意:返回None的时候Python的交互环境不显示结果
要删除一个key,用pop(key)方法
- 和list比较,dict有以下几个特点:
查找和插入的速度极快,不会随着key的增加而变慢;
需要占用大量的内存,内存浪费多。
而list相反:
查找和插入的时间随着元素的增加而增加;
占用空间小,浪费内存很少。
所以,dict是用空间来换取时间的一种方法。
十一、集合set
要创建一个set,需要提供一个list作为输入集合:
>>> s = set([1, 2, 3])
>>> s
{1, 2, 3}
注意,传入的参数[1, 2, 3]是一个list,而显示的{1, 2, 3}只是告诉你这个set内部有1,2,3这3个元素,显示的顺序也不表示set是有序的。
重复元素在set中自动被过滤:
>>> s = set([1, 1, 2, 2, 3, 3])
>>> s
{1, 2, 3}
通过add(key)方法可以添加元素到set中,可以重复添加,但不会有效果:
>>> s.add(4)
>>> s
{1, 2, 3, 4}
>>> s.add(4)
>>> s
{1, 2, 3, 4}
通过remove(key)方法可以删除元素:
>>> s.remove(4)
>>> s
{1, 2, 3}
注:其他用.pop(),除tuple不可删减
十二、不可变对象
str是不变对象
>>> a = 'abc'
>>> b = a.replace('a', 'A')
>>> b
'Abc'
>>> a
'abc'
虽然字符串有个replace()方法,也确实变出了’Abc’,但变量a最后仍是’abc’,应该怎么理解呢?
要始终牢记的是,a是变量,**而’abc’才是字符串对象!(不可变)**有些时候,我们经常说,对象a的内容是’abc’,但其实是指,a本身是一个变量,它指向的对象的内容才是’abc’
理解:replace方法创建了一个新字符串’Abc’并返回,如果我们用变量b指向该新字符串,就容易理解了,变量a仍指向原有的字符串’abc’,但变量b却指向新字符串’Abc’了
第二章 函数
一、调用函数
1.函数错误类型
要调用一个函数,需要知道函数的名称和参数,比如求绝对值的函数abs,只有一个参数。可以通过help(abs)查看abs函数的帮助信息。
(1)调用函数的时候,如果传入的参数数量不对,会报TypeError的错误,并且Python会明确地告诉你:abs()有且仅有1个参数,但给出了两个:
>>> abs(1, 2)
Traceback (most recent call last):
File "", line 1, in
TypeError: abs() takes exactly one argument (2 given)
(2)如果传入的参数数量是对的,但参数类型不能被函数所接受,也会报TypeError的错误,并且给出错误信息:str是错误的参数类型:
>>> abs('a')
Traceback (most recent call last):
File "", line 1, in
TypeError: bad operand type for abs(): 'str'
2.数据类型转换
>>> int('123')
123
>>> int(12.34)
12
>>> float('12.34')
12.34
>>> str(1.23)
'1.23'
>>> str(100)
'100'
>>> bool(1)
True
>>> bool('')
False
3.函数的别名
函数名其实就是指向一个函数对象的引用,完全可以把函数名赋给一个变量,相当于给这个函数起了一个“别名”:
>>> a = abs # 变量a指向abs函数
>>> a(-1) # 所以也可以通过a调用abs函数
1
二、定义函数
1.函数
在Python中,定义一个函数要使用def语句,依次写出函数名、括号、括号中的参数和冒号:,然后,在缩进块中编写函数体,函数的返回值用return语句返回。
请注意,函数体内部的语句在执行时,一旦执行到return时,函数就执行完毕,并将结果返回。因此,函数内部通过条件判断和循环可以实现非常复杂的逻辑。如果没有return语句,函数执行完毕后也会返回结果,只是结果为None。return None可以简写为return。
>>> def my_abs(x):
... if x >= 0:
... return x
... else:
... return -x
...
>>> my_abs(-9)
9
>>> _
如果你已经把my_abs()的函数定义保存为abstest.py文件了,那么,可以在该文件的当前目录下启动Python解释器,用from abstest import my_abs来导入my_abs()函数,注意abstest是文件名(不含.py扩展名):
>>> from abstest import my_abs
>>> my_abs(-9)
9
2.函数
如果想定义一个什么事也不做的空函数,可以用pass语句:
def nop():
pass
pass语句什么都不做,那有什么用?实际上pass可以用来作为占位符,比如现在还没想好怎么写函数的代码,就可以先放一个pass,让代码能运行起来。
三、函数的参数
1.位置参数
def power(x, n):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
power(x, n)函数有两个参数:x和n,这两个参数都是位置参数,调用函数时,传入的两个值按照位置顺序依次赋给参数x和n。(调用时必须添加的参数)
2.默认参数
def power(x, n=2):
s = 1
while n > 0:
n = n - 1
s = s * x
return s
这样,当我们调用power(5)时,相当于调用power(5, 2), n属于默认参数。
注意:
默认参数很有用,但使用不当,也会掉坑里。默认参数有个最大的坑,演示如下:
def add_end(L=[]):
L.append('END')
return L
>>> add_end()
['END']
>>> add_end()
['END', 'END']
>>> add_end()
['END', 'END', 'END']
很多初学者很疑惑,默认参数是[],但是函数似乎每次都“记住了”上次添加了’END’后的list。
Python函数在定义的时候,默认参数L的值就被计算出来了,即[],因为默认参数L也是一个变量,它指向对象[],每次调用该函数,如果改变了L的内容,则下次调用时,默认参数的内容就变了,不再是函数定义时的[]了。
定义默认参数要牢记一点:默认参数必须指向不变对象!(上述例子中的[]是可变化的)
要修改上面的例子,我们可以用None这个不变对象来实现:
def add_end(L=None):
if L is None:
L = []
L.append('END')
return L
>>> add_end()
['END']
>>> add_end()
['END']
为什么要设计str、None这样的不变对象呢?因为不变对象一旦创建,对象内部的数据就不能修改,这样就减少了由于修改数据导致的错误。
3.可变参数
顾名思义,可变参数就是传入的参数个数是可变的,可以是1个、2个到任意个,还可以是0个
我们以数学题为例子,给定一组数字a,b,c……,请计算a2 + b2 + c2 + ……。
要定义出这个函数,我们必须确定输入的参数。由于参数个数不确定,我们首先想到可以把a,b,c……作为一个list或tuple传进来,这样,函数可以定义如下:
def calc(numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
>>> calc([1, 2, 3])
14
>>> calc((1, 3, 5, 7))
84
但是调用的时候,需要先组装出一个list或tuple,
所以,我们把函数的参数改为可变参数:
def calc(*numbers):
sum = 0
for n in numbers:
sum = sum + n * n
return sum
>>> calc(1, 2, 3)
14
>>> calc(1, 3, 5, 7)
84
定义可变参数和定义一个list或tuple参数相比,仅仅在参数前面加了一个*号。在函数内部,参数numbers接收到的是一个tuple,因此,函数代码完全不变。但是,调用该函数时,可以传入任意个参数,包括0个参数:
如果已经有一个list或者tuple,要调用一个可变参数怎么办?可以这样做:
>>> nums = [1, 2, 3]
>>> calc(*nums)
14
*nums表示把nums这个list的所有元素作为可变参数传进去。这种写法相当有用,而且很常见。(即函数定义时加了 * 号,参数为可变参数,当我们有一个列表参数需要传递时,在调用函数时需要在前面加 * 号)
4.关键字参数
可变参数允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个tuple。
而关键字参数允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个dict。请看示例:
def person(name, age, **kw):
print('name:', name, 'age:', age, 'other:', kw)
函数person除了必选参数name和age外,还接受关键字参数kw。在调用该函数时,可以只传入必选参数,即**kw可以不用传递参数。
传入任意个数的关键字参数:
>>> person('Bob', 35, city='Beijing')
name: Bob age: 35 other: {'city': 'Beijing'}
>>> person('Adam', 45, gender='M', job='Engineer')
name: Adam age: 45 other: {'gender': 'M', 'job': 'Engineer'}
后面传递一个或者多个键值对的字典型(dic)的参数。
上面复杂的调用可以用简化的写法:
>>> extra = {'city': 'Beijing', 'job': 'Engineer'}
>>> person('Jack', 24, **extra)
name: Jack age: 24 other: {'city': 'Beijing', 'job': 'Engineer'}
即直接稀罕地一个字典型参数,但必须也加**。注意kw获得的dict是extra的一份拷贝,对kw的改动不会影响到函数外的extra。
5.命名关键字参数
对于关键字参数,函数的调用者可以传入任意不受限制的关键字参数。至于到底传入了哪些,就需要在函数内部通过kw检查。
仍以person()函数为例,我们希望检查是否有city和job参数:
def person(name, age, **kw):
if 'city' in kw:
# 有city参数
pass
if 'job' in kw:
# 有job参数
pass
print('name:', name, 'age:', age, 'other:', kw)
如果要限制关键字参数的名字,就可以用命名关键字参数,例如,只接收city和job作为关键字参数。这种方式定义的函数如下:
和关键字参数kw不同,命名关键字参数需要一个特殊分隔符***,*后面的参数被视为命名关键字参数。
def person(name, age, *, city, job):
print(name, age, city, job)
调用时不写*,如下:
>>> person('Jack', 24, city='Beijing', job='Engineer')
Jack 24 Beijing Engineer
命名参数名必须写,否则报错!如下:
>>> person('Jack', 24, 'Beijing', 'Engineer')
Traceback (most recent call last):
File "", line 1, in
TypeError: person() takes 2 positional arguments but 4 were given
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*了:
def person(name, age, *args, city, job):
print(name, age, args, city, job)
命名关键字参数可以有默认值,从而简化调用:
def person(name, age, *, city='Beijing', job):
print(name, age, city, job)
>>> person('Jack', 24, job='Engineer')
Jack 24 Beijing Engineer
#Beijing默认
6.参数组合
在Python中定义函数,可以用必选参数、默认参数、可变参数、关键字参数和命名关键字参数,这5种参数都可以组合使用。但是请注意,参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
一般不建议。
四、递归函数
如果一个函数在内部调用自身本身,这个函数就是递归函数。
使用递归函数需要注意防止栈溢出。在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出。
解决递归调用栈溢出的方法是通过尾递归优化,尾递归是指,在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。
出现栈溢出:
def fact(n):
if n==1:
return 1
return n * fact(n - 1)
尾递归优化:
def fact_iter(num, product):
if num == 1:
return product
return fact_iter(num - 1, num * product)
def fact(n):
return fact_iter(n, 1)
第三章 高级特性
一、切片
L[0:3]表示,从索引0开始取,直到索引3为止,但不包括索引3。即索引0,1,2,正好是3个元素。
如果第一个索引是0,还可以省略:
>>> L = ['Michael', 'Sarah', 'Tracy', 'Bob', 'Jack']
>>> L[:3]
['Michael', 'Sarah', 'Tracy']
它同样支持倒数切片,试试:
>>> L[-2:]
['Bob', 'Jack']
>>> L[-2:-1] #依旧满足左闭右开
['Bob']
所有数,每5个取一个:
>>> L = list(range(100))
>>> L[::5]
[0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95]
字符串’xxx’也可以看成是一种list,每个元素就是一个字符。因此,字符串也可以用切片操作,只是操作结果仍是字符串:
>>> 'ABCDEFG'[:3]
'ABC'
>>> 'ABCDEFG'[::2]
'ACEG'
二、迭代
Python的for循环不仅可以用在list或tuple上,还可以作用在其他可迭代对象上。
list这种数据类型虽然有下标,但很多其他数据类型是没有下标的,但是,只要是可迭代对象,无论有无下标,都可以迭代,比如dict就可以迭代:
>>> d = {'a': 1, 'b': 2, 'c': 3}
>>> for key in d:
... print(key)
...
a
c
b
因为dict的存储不是按照list的方式顺序排列,所以,迭代出的结果顺序很可能不一样。
默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()。
>>> a={'a':1,'b':2,'c':3}
>>> for n,m in a.items():
print(n,m)
a 1
b 2
c 3
由于字符串也是可迭代对象,因此,也可以作用于for循环:
>>> for ch in 'ABC':
... print(ch)
...
A
B
C
所以,当我们使用for循环时,只要作用于一个可迭代对象,for循环就可以正常运行,而我们不太关心该对象究竟是list还是其他数据类型。
那么,如何判断一个对象是可迭代对象呢?方法是通过collections模块的Iterable类型判断
>>> from collections import Iterable
>>> isinstance('abc', Iterable) # str是否可迭代
True
>>> isinstance([1,2,3], Iterable) # list是否可迭代
True
>>> isinstance(123, Iterable) # 整数是否可迭代
False
如果要对list实现类似Java那样的下标循环怎么办?Python内置的enumerate函数可以把一个list变成索引-元素对,这样就可以在for循环中同时迭代索引和元素本身:
>>> a=[1,2,3]
>>> for i,value in enumerate(a):
print(i,value)
0 1
1 2
2 3
三、列表生成式
列表生成式即List Comprehensions,是Python内置的非常简单却强大的可以用来****的生成式。
>>> list(range(1, 11))
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
但如果要生成[1x1, 2x2, 3x3, …, 10x10]怎么做?方法一是循环:
>>> L = []
>>> for x in range(1, 11):
... L.append(x * x)
...
>>> L
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
但是循环太繁琐,而列表生成式则可以用一行语句代替循环生成上面的list:
>>> [x * x for x in range(1, 11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
写列表生成式时,把要生成的元素x * x放到前面,后面跟for循环,就可以把list创建出来。
for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
还可以使用两层循环,可以生成全排列:
>>> [m + n for m in 'ABC' for n in 'XYZ']
['AX', 'AY', 'AZ', 'BX', 'BY', 'BZ', 'CX', 'CY', 'CZ']
for循环其实可以同时使用两个甚至多个变量,比如dict的items()可以同时迭代key和value:
>>> d = {'x': 'A', 'y': 'B', 'z': 'C' }
>>> [k + '=' + v for k, v in d.items()]
['y=B', 'x=A', 'z=C']
最后把一个list中所有的字符串变成小写:
>>> L = ['Hello', 'World', 'IBM', 'Apple']
>>> [s.lower() for s in L]
['hello', 'world', 'ibm', 'apple']
四、生成器
通过列表生成式,我们可以直接创建一个列表。但是,受到内存限制,列表容量肯定是有限的。而且,创建一个包含100万个元素的列表,不仅占用很大的存储空间,如果我们仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
所以,如果列表元素可以按照某种算法推算出来,那我们是否可以在循环的过程中不断推算出后续的元素呢?这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
>>> L = [x * x for x in range(10)]
>>> L
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g = (x * x for x in range(10))
>>> g
at 0x1022ef630>
此时g输出的是一个生成器,开始调用,generator也是可迭代对象,使用for循环:
>>> g = (x * x for x in range(10))
>>> for n in g:
... print(n)
...
0
1
4
9
16
25
36
49
64
81
generator非常强大。如果推算的算法比较复杂,用类似列表生成式的for循环无法实现的时候,还可以用函数来实现。
斐波拉契数列用列表生成式写不出来,但是,用函数把它打印出来却很容易:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
print(b)
a, b = b, a + b
n = n + 1
return 'done'
注意,赋值语句:
a, b = b, a + b
相当于:
t = (b, a + b) # t是一个tuple
a = t[0]
b = t[1]
fib函数实际上是定义了斐波拉契数列的推算规则,可以从第一个元素开始,推算出后续任意的元素,这种逻辑其实非常类似generator。也就是说,上面的函数和generator仅一步之遥。要把fib函数变成generator,只需要把print(b)改为yield b就可以了:
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
>>> f = fib(6)
>>> f
这里,最难理解的就是generator和函数的执行流程不一样。函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
举个简单的例子,定义一个generator,依次返回数字1,3,5:
def odd():
print('step 1')
yield 1
print('step 2')
yield(3)
print('step 3')
yield(5)
调用该generator时,首先要生成一个generator对象,然后用next()函数不断获得下一个返回值:
>>> o = odd()
>>> next(o)
step 1
1
>>> next(o)
step 2
3
>>> next(o)
step 3
5
>>> next(o)
Traceback (most recent call last):
File "", line 1, in
StopIteration
可以看到,odd不是普通函数,而是generator,在执行过程中,遇到yield就中断,下次又继续执行。执行3次yield后,已经没有yield可以执行了,所以,第4次调用next(o)就报错。
五、迭代器
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list、tuple、dict、set、str等;
一类是generator,包括生成器和带yield的generator function。
这些可以直接作用于for循环的对象统称为可迭代对象:Iterable。
可以使用isinstance()判断一个对象是否是Iterable对象:
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
>>> isinstance('abc', Iterable)
True
>>> isinstance((x for x in range(10)), Iterable)
True
>>> isinstance(100, Iterable)
False
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
可以使用isinstance()判断一个对象是否是Iterator对象:
>>> from collections import Iterator
>>> isinstance((x for x in range(10)), Iterator)
True
>>> isinstance([], Iterator)
False
>>> isinstance({}, Iterator)
False
>>> isinstance('abc', Iterator)
False
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。所以list、dict、str等数据类型不是Iterator。
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
把list、dict、str等Iterable变成Iterator可以使用iter()函数:
>>> isinstance(iter([]), Iterator)
True
>>> isinstance(iter('abc'), Iterator)
True
第四章 函数式编程
一、高阶函数
>>> f = abs
>>> f
结论:函数本身也可以赋值给变量,即:变量可以指向函数。
>>> f = abs
>>> f(-10)
10
变量f现在已经指向了abs函数本身。直接调用abs()函数和调用变量f()完全相同
>>> abs = 10
>>> abs(-10)
Traceback (most recent call last):
File "", line 1, in
TypeError: 'int' object is not callable
函数名也是变量
把abs指向10后,就无法通过abs(-10)调用该函数了!因为abs这个变量已经不指向求绝对值函数而是指向一个整数10!当然实际代码绝对不能这么写,这里是为了说明函数名也是变量。要恢复abs函数,请重启Python交互环境。
既然变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
举例:
def add(x, y, f):
return f(x) + f(y)
当我们调用add(-5, 6, abs)时,参数x,y和f分别接收-5,6和abs,根据函数定义,我们可以推导计算过程为:
x = -5
y = 6
f = abs
f(x) + f(y) ==> abs(-5) + abs(6) ==> 11
return 11
此例中,add即为高阶函数
1.map()和reduce()函数
(1)map()函数
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。
>>> def f(x):
... return x * x
...
>>> r = map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])
>>> list(r)
[1, 4, 9, 16, 25, 36, 49, 64, 81]
(2)reduce()函数
reduce把一个函数作用在一个序列[x1, x2, x3, …]上,这个函数必须接收两个参数,reduce把结果继续和序列的下一个元素做累积计算
>>> def add(x, y):
... return x + y
...
>>> reduce(add, [1, 3, 5, 7, 9])
25
但是如果要把序列[1, 3, 5, 7, 9]变换成整数13579,reduce就可以派上用场:
>>> from functools import reduce
>>> def fn(x, y):
... return x * 10 + y
...
>>> reduce(fn, [1, 3, 5, 7, 9])
13579
整理成一个str2int的函数就是:
from functools import reduce
DIGITS = {'0': 0, '1': 1, '2': 2, '3': 3, '4': 4, '5': 5, '6': 6, '7': 7, '8': 8, '9': 9}
def str2int(s):
def fn(x, y):
return x * 10 + y
def char2num(s):
return DIGITS[s]
return reduce(fn, map(char2num, s))
2,filter()函数
filter()也接收一个函数和一个序列。filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
例如,在一个list中,删掉偶数,只保留奇数,可以这么写:
def is_odd(n):
return n % 2 == 1
list(filter(is_odd, [1, 2, 4, 5, 6, 9, 10, 15]))
结果: [1, 5, 9, 15]
用list打印出来,也可以用循环或者next()
把一个序列中的空字符串删掉,可以这么写:
def not_empty(s):
return s and s.strip()
list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))
# 结果: ['A', 'B', 'C']
s and s.strip()“ 这个表达式的值。Python语法是这么运行的:
如果s is None,那么s会被判断为False。而False不管和什么做and,结果都是False,所以不需要看and后面的表达式,直接返回s(注意不是返回False)。
如果s is not None,那么s会被判断为True,而True不管和什么and都返回后一项。于是就返回了s.strip()。
可见用filter()这个高阶函数,关键在于正确实现一个“筛选”函数。
注意到filter()函数返回的是一个Iterator,也就是一个惰性序列,所以要强迫filter()完成计算结果,需要用list()函数获得所有结果并返回list。
3,sorted()函数
排序也是在程序中经常用到的算法。无论使用冒泡排序还是快速排序,排序的核心是比较两个元素的大小。如果是数字,我们可以直接比较,但如果是字符串或者两个dict呢?直接比较数学上的大小是没有意义的,因此,比较的过程必须通过函数抽象出来。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,无返回值,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
Python内置的sorted()函数就可以对list进行排序,根据大小,sorted()函数也是一个高阶函数,它还可以接收一个key函数来实现自定义的排序,例如按绝对值大小排序:
>>> sorted([36, 5, -12, 9, -21], key=abs)
[5, 9, -12, -21, 36]
key指定的函数将作用于list的每一个元素上,并根据key函数返回的结果进行排序。对比原始的list和经过key=abs处理过的list:
默认情况下,对字符串排序,是按照ASCII的大小比较的,由于’Z’ < ‘a’,结果,大写字母Z会排在小写字母a的前面。
现在,我们提出排序应该忽略大小写,按照字母序排序。要实现这个算法,不必对现有代码大加改动,只要我们能用一个key函数把字符串映射为忽略大小写排序即可。忽略大小写来比较两个字符串,实际上就是先把字符串都变成大写(或者都变成小写),再比较。
这样,我们给sorted传入key函数,即可实现忽略大小写的排序:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower)
['about', 'bob', 'Credit', 'Zoo']
要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
>>> sorted(['bob', 'about', 'Zoo', 'Credit'], key=str.lower, reverse=True)
['Zoo', 'Credit', 'bob', 'about']
reverse = True 降序 , reverse = False 升序(默认)。
二、返回函数
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
当我们调用lazy_sum()时,返回的并不是求和结果,而是求和函数:
>>> f = lazy_sum(1, 3, 5, 7, 9)
>>>> f()
25
闭包:
注意到返回的函数在其定义内部引用了局部变量args(外部函数定义的变量),所以,当一个函数返回了一个函数后,其内部的局部变量还被新函数(内部函数)引用。
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
在上面的例子中,每次循环,都创建了一个新的函数,然后,把创建的3个函数都返回了。
你可能认为调用f1(),f2()和f3()结果应该是1,4,9,但实际结果是:
>>> f1()
9
>>> f2()
9
>>> f3()
9
全部都是9!原因就在于返回的函数引用了变量i,但它并非立刻执行。等到3个函数都返回时,它们所引用的变量i已经变成了3,因此最终结果为9。
返回闭包时牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
三、匿名函数
当我们在传入函数时,有些时候,不需要显式地定义函数,直接传入匿名函数更方便。
list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
[1, 4, 9, 16, 25, 36, 49, 64, 81]
关键字lambda表示匿名函数,冒号前面的x表示函数参数。也可以没有参数
匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。用匿名函数有个好处,因为函数没有名字,不必担心函数名冲突。
四、装饰器
函数对象有一个__name__属性,可以拿到函数的名字:
def now():
print('2015-3-25')
f = now
>>>now.__name__
'now'
>>> f.__name__
'now'
现在,假设我们要增强now()函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改now()函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
本质上,decorator就是一个返回函数的高阶函数。所以,我们要定义一个能打印日志的decorator,可以定义如下:
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
观察上面的log,因为它是一个decorator,所以接受一个函数作为参数,并返回一个函数。我们要借助Python的**@语法**,把decorator置于函数的定义处:
@log
def now():
print('2015-3-25')
调用now()函数,不仅会运行now()函数本身,还会在运行now()函数前打印一行日志:
>>> now()
call now():
2015-3-25
把@log放到now()函数的定义处,相当于执行了语句:now = log(now)
五、偏函数
当函数的参数个数太多,需要简化时,使用functools.partial可以创建一个新的函数(偏函数),这个新函数可以
固定住原函数的部分参数,从而在调用时更简单。
假设要转换大量的二进制字符串,每次都传入int(x, base=2)非常麻烦,可以定义一个int2()的函数,默认把base=2传进去,functools.partial就是帮助我们创建一个偏函数的,不需要我们自己定义int2(),可以直接使用下面的代码创建一个新的函数int2:
>>> import functools
>>> int2 = functools.partial(int, base=2)
>>> int2('1000000')
64
>>> int2('1010101')
85
注意到上面的新的int2函数,仅仅是把base参数重新设定默认值为2,但也可以在函数调用时传入其他值:
>>> int2('1000000', base=10)
1000000
创建偏函数时,实际上可以接收函数对象、*args和**kw这3个参数,当传入:
max2 = functools.partial(max, 10)# max2是新的max函数
实际上会把10作为*args的一部分自动加到左边,也就是:max2(5, 6, 7)
args = (10, 5, 6, 7)
max(*args)
第五章 模块
一、使用模块
编写一个hello的模块:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
' a test module '
__author__ = 'Michael Liao'
import sys
def test():
args = sys.argv
if len(args)==1:
print('Hello, world!')
elif len(args)==2:
print('Hello, %s!' % args[1])
else:
print('Too many arguments!')
if __name__=='__main__':
test()
第1行注释可以让这个hello.py文件直接在Unix/Linux/Mac上运行,
第2行注释表示.py文件本身使用标准UTF-8编码;
第4行是一个字符串,表示模块的文档注释,任何模块代码的第一个字符串都被视为模块的文档注释;
第6行使用__author__变量把作者写进去,这样当你公开源代码后别人就可以瞻仰你的大名;
以上就是Python模块的标准文件模板,当然也可以全部删掉不写,但是,按标准办事肯定没错。
后面开始就是真正的代码部分。
导入sys模块后,我们就有了变量sys指向该模块,利用sys这个变量,就可以访问sys模块的所有功能。
sys模块有一个argv变量,用list存储了命令行的所有参数。argv至少有一个元素,因为第一个参数永远是该.py文件的名称,
运行python3 hello.py获得的sys.argv就是[‘hello.py’];(文件名字符只有一个)
运行python3 hello.py Michael获得的sys.argv就是[‘hello.py’, 'Michael]。(文件名有两个)
导入时,没有打印Hello, word!,因为没有执行test()函数。
调用hello.test()时,才能打印出Hello, word!:
>>> import hello
>>>> hello.test()
Hello, world!
二、作用域
正常的函数和变量名是公开的(public),可以被直接引用,比如:abc,x123,PI等;
类似_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用,比如_abc,__abc等;
之所以我们说,private函数和变量“不应该”被直接引用(可以间接引用),而不是“不能”被直接引用,是因为Python并没有一种方法可以完全限制访问private函数或变量,但是,从编程习惯上不应该引用private函数或变量:
注意:
变量名类似__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用__name__、__score__这样的变量名。
def _private_1(name):
return 'Hello, %s' % name
def _private_2(name):
return 'Hi, %s' % name
def greeting(name):
if len(name) > 3:
return _private_1(name)
else:
return _private_2(name)
我们在模块里公开greeting()函数,而把内部逻辑用private函数隐藏起来了,这样,调用greeting()函数不用关心内部的private函数细节,这也是一种非常有用的代码封装和抽象的方法。
第六章 面向对象编程
一、类和实例
1.类和实例
类(Class)是抽象的模板,比如Student类
实例(Instance)是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。
class后面紧接着是类名,即Student,类名通常是大写开头的单词:
class Student(object):
pass
(object),表示该类是从哪个类继承下来的,继承的概念我们后面再讲,通常,如果没有合适的继承类,就使用object类,这是所有类最终都会继承的类。
定义好了Student类,就可以根据Student类创建出Student的实例,创建实例是通过**类名+()**实现的:
>>> bart = Student()
>>> bart
<__main__.Student object at 0x10a67a590>
>>> Student
变量bart指向的就是一个Student的实例,后面的0x10a67a590是内存地址,每个object的地址都不一样,而Student本身则是一个类。
可以自由地给一个实例变量绑定属性,比如,给实例bart绑定一个name属性:
>>> bart.name = 'Bart Simpson'
>>> bart.name
'Bart Simpson'
由于类可以起到模板的作用,因此,可以在创建实例的时候,把一些我们认为必须绑定的属性强制填写进去。通过定义一个特殊的**init**方法,在创建实例的时候,就把name,score等属性绑上去:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
和普通的函数相比,在类中定义的函数只有一点不同,就是第一个参数永远是实例变量self,并且,调用时,不用传递该参数。除此之外,类的方法和普通函数没有什么区别,所以,你仍然可以用默认参数、可变参数、关键字参数和命名关键字参数。
3.数据封装
面向对象编程的一个重要特点就是数据封装。在上面的Student类中,每个实例就拥有各自的name和score这些数据。我们可以通过函数来访问这些数据,比如打印一个学生的成绩:
>>> def print_score(std):
... print('%s: %s' % (std.name, std.score))
...
>>> print_score(bart)
Bart Simpson: 59
既然Student实例本身就拥有这些数据,要访问这些数据,就没有必要从外面的函数去访问,可以直接在Student类的内部定义访问数据的函数,这样,就把“数据”给封装起来了。这些封装数据的函数是和Student类本身是关联起来的,我们称之为类的方法:
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))
即直接在类内部定义访问数据的函数,使用时直接调用该内部函数。
二、访问限制
如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线__,在Python中,实例的变量名如果以__开头,就变成了一个私有变量(private),只有内部可以访问,外部不能访问,所以,我们把Student类改一改:
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
def print_score(self):
print('%s: %s' % (self.__name, self.__score))
但是如果外部代码要获取name和score怎么办?可以给Student类增加get_name和get_score这样的方法:
class Student(object):
...
def get_name(self):
return self.__name
def get_score(self):
return self.__score
如果又要允许外部代码修改score怎么办?可以再给Student类增加set_score方法:
class Student(object):
...
def set_score(self, score):
self.__score = score
你也许会问,原先那种直接通过bart.score = 99也可以修改啊,为什么要定义一个方法大费周折?因为在方法中,可以对参数做检查,避免传入无效的参数:
(即加入检测输入的效果)
class Student(object):
...
def set_score(self, score):
if 0 <= score <= 100:
self.__score = score
else:
raise ValueError('bad score')
在Python中,变量名类似__xxx__的,也就是以双下划线开头,并且以双下划线结尾的,是特殊变量,特殊变量是可以直接访问的,不是private变量,所以,不能用__name__、__score__这样的变量名。
三.继承和多态
1.继承
class Animal(object):
def run(self):
print('Animal is running...')
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running...')
dog = Dog()
dog.run()
cat = Cat()
cat.run()
Dog is running...
Cat is running...
2.多态
当子类和父类都存在相同的run()方法时,我们说,子类的run()覆盖了父类的run(),在代码运行的时候,总是会调用子类的run()。这样,我们就获得了继承的另一个好处:多态。
而且需要重新写一个函数,不同类调用它,产生不同结果(多态)
def run_twice(animal):
animal.run()
animal.run()
注意:静态语言 vs 动态语言
在上述多态函数中,对于静态语言(例如Java)来说如果需要传入Animal类型(父类),则传入的对象必须是Animal类型或者它的子类,否则,将无法调用run()方法。
对于Python这样的动态语言来说,则不一定需要传入Animal类型。我们只需要保证传入的对象有一个run()方法就可以了:
#其他类,只要含有run()函数,都可以调用多态函数
class Timer(object):
def run(self):
print('Start...')
四、获取对象信息
1.使用type()
判断基本数据类型可以直接写用type(),判断一个对象是否是函数怎么办?可以使用types模块中定义的常量:
>>> import types
>>> def fn():
... pass
...
>>> type(fn)==types.FunctionType
True
>>> type(abs)==types.BuiltinFunctionType
True
>>> type(lambda x: x)==types.LambdaType
True
>>> type((x for x in range(10)))==types.GeneratorType
True
2.使用isinstance()
(1)isinstance()判断的是一个对象是否是该类型本身,或者位于该类型的父继承链上。(即包括父类,子类)
(2)能用type()判断的基本类型也可以用isinstance()判断
(3)并且还可以判断一个变量是否是某些类型中的一种,比如下面的代码就可以判断是否是list或者tuple:
>>> isinstance([1, 2, 3], (list, tuple))
True
>>> isinstance((1, 2, 3), (list, tuple))
True
3.使用dir()
如果要获得一个对象的所有属性和方法,可以使用dir()函数,它返回一个包含字符串的list,比如,获得一个str对象的所有属性和方法:
>>> dir('ABC')
['__add__', '__class__',..., '__subclasshook__', 'capitalize', 'casefold',..., 'zfill']
类似__xxx__的属性和方法在Python中都是有特殊用途的,比如__len__方法返回长度。在Python中,如果你调用len()函数试图获取一个对象的长度,实际上,在len()函数内部,它自动去调用该对象的__len__()方法,所以,下面的代码是等价的:
>>> len('ABC')
3
>>> 'ABC'.__len__()
3
也可以自定义内部函数,通过内置的一系列函数,我们可以对任意一个Python对象进行剖析,拿到其内部的数据。要注意的是,只有在不知道对象信息的时候,我们才会去获取对象信息。如果可以直接写:
sum = obj.x + obj.y
就不要写:
sum = getattr(obj, 'x') + getattr(obj, 'y')
假设我们希望从文件流fp中读取图像,我们首先要判断该fp对象是否存在read方法,如果存在,则该对象是一个流,如果不存在,则无法读取。hasattr()就派上了用场。
f readImage(fp):
if hasattr(fp, 'read'):
return readData(fp)
return None
五、实例属性和类属性
由于Python是动态语言,根据类创建的实例可以任意绑定属性。即实例可以任意给自己添加类属性。
class Student(object):
def __init__(self, name):
self.name = name
s = Student('Bob')
s.score = 90 #添加自己的类属性
如果Student类本身需要绑定一个属性,可以直接在class中定义属性,这种属性是类属性,归Student类所有:
class Student(object):
name = 'Student'
定义了一个类属性后,这个属性虽然归类所有,但类的所有实例都可以访问到
>>> s = Student() # 创建实例s
>>> print(s.name) # 打印name属性,因为实例并没有name属性,所以会继续查找class的name属性
Student
>>> print(Student.name) # 打印类的name属性
Student
>>> s.name = 'Michael' # 给实例绑定name属性
>>> print(s.name) # 由于实例属性优先级比类属性高,因此,它会屏蔽掉类的name属性
Michael
>>> print(Student.name) # 但是类属性并未消失,用Student.name仍然可以访问
Student
>>> del s.name # 如果删除实例的name属性
>>> print(s.name) # 再次调用s.name,由于实例的name属性没有找到,类的name属性就显示出来了
Student
从上面的例子可以看出,在编写程序的时候,千万不要对实例属性和类属性使用相同的名字,因为相同名称的实例属性将屏蔽掉类属性,但是当你删除实例属性后,再使用相同的名称,访问到的将是类属性。
第七章 面向对象高级教程
一、使用__slots__
1.给实例绑定方法(函数)
函数内部有属性
>>> def set_age(self, age): # 定义一个函数作为实例方法
... self.age = age
...
>>> from types import MethodType
>>> s.set_age = MethodType(set_age, s) # 给实例绑定一个方法
>>> s.set_age(25) # **调用实例方法**
>>> s.age # **测试结果**
25
即通过MethodType给实例绑定一个函数。格式:实例.方法=MethodType(方法,实例)。
给一个实例绑定的方法,对另一个实例是不起作用的。
为了给所有实例都绑定方法,可以给class绑定方法:
2.给类绑定方法
>>> def set_score(self, score):
... self.score = score
...
>>> Student.set_score = cc.bb = MethodType(set_score,Student)
>>> s.set_score(100)
>>> s.score
100
>>> s2.set_score(99)
>>> s2.score
99
动态绑定允许我们在程序运行的过程中动态给class加上功能,这在静态语言中很难实现。
3.使用__slots__
但是,如果我们想要限制实例的属性怎么办?比如,只允许对Student实例添加name和age属性。
为了达到限制的目的,Python允许在定义class的时候,定义一个特殊的**__slots__变量**,来限制该class实例能添加的属性:
class Student(object):
__slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称
使用__slots__要注意,__slots__定义的属性仅对当前类实例起作用,对继承的子类是不起作用的:
>>> class GraduateStudent(Student):
... pass
...
>>> g = GraduateStudent()
>>> g.score = 9999
除非在子类中也定义__slots__,这样,子类实例允许定义的属性就是自身的__slots__加上父类的__slots__。
二、使用@property
s = Student()
s.score = 9999
class Student(object):
def get_score(self):
return self._score
def set_score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
>>> s = Student()
>>> s.set_score(60) # ok!
>>> s.get_score()
60
>>> s.set_score(9999)
Traceback (most recent call last):
...
ValueError: score must between 0 ~ 100!
以上第一段程序额外定义属性时,比较简单,但缺少对输入的检测;
第二段程序具有对输入检测的功能,但调用时比较复杂(即需要调用内部函数来读取属性)
使用@property解决以上问题:
class Student(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
加上@property,表示把一个getter(得到)方法变成属性,另一个装饰器@score.setter,负责把一个setter方法变成属性赋值(设置属性值)
如果只有@property,则只能读取,不能写入。
三、多重继承
class Dog(Mammal, Runnable):
pass
Dog同事继承Mammal和Runnable两个类。这种设计通常称之为MixIn
四、定制类
看到类似__slots__这种形如__xxx__的变量或者函数名就要注意,这些在Python中是有特殊用途的。
1.str
>>> class Student(object):
... def __init__(self, name):
... self.name = name
... def __str__(self):
... return 'Student object (name: %s)' % self.name
...
>>> print(Student('Michael'))
Student object (name: Michael)
即类运行后,出现提示字符串。
但是:
>>> s = Student('Michael')
>>> s
<__main__.Student object at 0x109afb310>
这是因为直接显示变量调用的不是__str__(),而是__repr__(),两者的区别是__str__()返回用户看到的字符串,而__repr__()返回程序开发者看到的字符串,也就是说,repr()是为调试服务的。
解决办法是再定义一个__repr__()。但是通常__str__()和__repr__()代码都是一样的,所以,有个偷懒的写法:
class Student(object):
def init(self, name):
self.name = name
def str(self):
return ‘Student object (name=%s)’ % self.name
repr = str
2.iter
iter()方法,该方法返回一个迭代对象,然后,Python的for循环就会不断调用该迭代对象的__next__()方法拿到循环的下一个值,直到遇到StopIteration错误时退出循环。
class Fib(object):
......
def __iter__(self):
return self # 实例本身就是迭代对象,故返回自己
3.getitem
要表现得像list那样按照下标取出元素.
class Fib(object):
def __getitem__(self, n):
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a
>>> f = Fib()
>>> f[0]
1
>>> f[1]
1
切片方法:
getitem()传入的参数可能是一个int,也可能是一个切片对象slice,所以要做判断:
class Fib(object):
def __getitem__(self, n):
if isinstance(n, int): # n是索引
a, b = 1, 1
for x in range(n):
a, b = b, a + b
return a
if isinstance(n, slice): # n是切片
start = n.start
stop = n.stop
if start is None:
start = 0
a, b = 1, 1
L = []
for x in range(stop):
if x >= start:
L.append(a)
a, b = b, a + b
return L
也没有对负数作处理,所以,要正确实现一个__getitem__()还是有很多工作要做的。
此外,如果把对象看成dict,getitem()的参数也可能是一个可以作key的object,例如str。
与之对应的是__setitem__()方法,把对象视作list或dict来对集合赋值。最后,还有一个__delitem__()方法,用于删除某个元素。
4.getattr
调用类的方法或属性时,如果不存在,就会报错,要避免这个错误,除了可以加上一个score属性外,Python还有另一个机制,那就是写一个__getattr__()方法,动态返回一个属性。修改如下:
class Student(object):
def __init__(self):
self.name = 'Michael'
def __getattr__(self, attr):
if attr=='score':
return 99
只有在没有找到属性的情况下,才调用__getattr__,已有的属性,比如name,不会在__getattr__中查找。
此外,注意到任意调用如s.abc都会返回None,这是因为我们定义的__getattr__默认返回就是None。要让class只响应特定的几个属性,我们就要按照约定,抛出AttributeError的错误:
class Student(object):
def __getattr__(self, attr):
if attr=='age':
return lambda: 25
raise AttributeError('\'Student\' object has no attribute \'%s\'' % attr)
即除了age其他属性会抛出异常。
5.call
一个类实例也可以变成一个可调用对象,只需要实现一个特殊方法__call__()
class Person(object):
def init(self, name, gender):
self.name = name
self.gender = gender
def __call__(self, friend):
print 'My name is %s...' % self.name
print 'My friend is %s...' % friend
现在可以对 Person 实例直接调用:
p = Person(‘Bob’, ‘male’)
p(‘Tim’)
My name is Bob…
My friend is Tim…
五、使用枚举类
枚举的定义
首先,定义枚举要导入enum模块。枚举定义用class关键字,继承Enum类。
from enum import Enum
class Color(Enum):
red = 1
orange = 2
yellow = 3
green = 4
blue = 5
indigo = 6
默认情况下,不同的成员值允许相同。但是两个相同值的成员,第二个成员的名称被视作第一个成员的别名
如果要限制定义枚举时,不能定义相同值的成员。可以使用装饰器@unique【要导入unique模块】
from enum import Enum, unique
@unique
class Color(Enum):
red = 1
red_alias = 1
from enum import Enum, unique
@unique
class Color(Enum):
red = 1
red_alias = 1
再执行就会提示错误:ValueError: duplicate values found in
枚举取值
(1)通过成员的名称来获取成员
Color[‘red’]
(2) 通过成员值来获取成员
Color(2)
(3) 通过成员,来获取它的名称和值
red_member = Color.red
red_member.name
red_member.value
枚举支持迭代器,可以遍历枚举成员,想把值重复的成员也遍历出来,要用枚举的一个特殊属性__members__
for color in Color.__members__.items():
print(color)
六、使用元类
动态语言和静态语言最大的不同,就是函数和类的定义,不是编译时定义的,而是运行时动态创建的。
1.type()
type()函数既可以返回一个对象的类型,又可以创建出新的类型
>>> def fn(self, name='world'): # 先定义函数
... print('Hello, %s.' % name)
...
>>> Hello = type('Hello', (object,), dict(hello=fn)) # 创建Hello class
>>> h = Hello()
>>> h.hello()
Hello, world.
>>> print(type(Hello))
>>> print(type(h))
type()函数依次传入3个参数:
(1)class的名称;
(2)继承的父类集合,注意Python支持多重继承,如果只有一个父类,别忘了tuple的单元素写法;(object ,)
(3)class的方法名称与函数绑定,这里我们把函数fn绑定到方法名hello上。
定义了类class hello,然后定义继承(object,),然后定内部函数hello,绑定了fn函数。
正常情况下,我们都用class Xxx…来定义类,但是,type()函数也允许我们动态创建出类来
2.metaclass
metaclass,直译为元类,简单的解释就是:
当我们定义了类以后,就可以根据这个类创建出实例,所以:先定义类,然后创建实例。
但是如果我们想创建出类呢?那就必须根据metaclass创建出类,所以:先定义metaclass,然后创建类。
连接起来就是:先定义metaclass,就可以创建类,最后创建实例。
第八章 错误、调试和测试
一、错误处理
try:
print('try...')
r = 10 / int('a')
print('result:', r)
except ValueError as e:
print('ValueError:', e)
except ZeroDivisionError as e:
print('ZeroDivisionError:', e)
finally:
print('finally...')
print('END')
try内部函数出现某种错误,则会抛出错误类型,except会接受符合自己错误的类型,int()函数可能会抛出ValueError,所以我们用一个except捕获ValueError,用另一个except捕获ZeroDivisionError。
执行完except后,如果有finally语句块,则执行finally语句块,至此,执行完毕。
Python的错误其实也是class,所有的错误类型都继承自BaseException,所以在使用except时需要注意的是,它不但捕获该类型的错误,还把其子类也“一网打尽”。如下:
try:
foo()
except ValueError as e:
print('ValueError')
except UnicodeError as e:
print('UnicodeError')
第二个except永远也捕获不到UnicodeError,因为UnicodeError是ValueError的子类,如果有,也被第一个except给捕获了。
如果错误没有被捕获,它就会一直往上抛,最后被Python解释器捕获,打印一个错误信息,然后程序退出。
# err.py:
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
bar('0')
main()
结果:
$ python3 err.py
Traceback (most recent call last):
File "err.py", line 11, in
main()
File "err.py", line 9, in main
bar('0')
File "err.py", line 6, in bar
return foo(s) * 2
File "err.py", line 3, in foo
return 10 / int(s)
ZeroDivisionError: division by zero
分析:
错误信息第1行:
Traceback (most recent call last):
告诉我们这是错误的跟踪信息。提示信息
第2~3行:
File “err.py”, line 11, in
main()
调用main()出错了,在代码文件err.py的第11行代码,但原因是第9行:
File “err.py”, line 9, in main
bar(‘0’)
调用bar(‘0’)出错了,在代码文件err.py的第9行代码,但原因是第6行:
File “err.py”, line 6, in bar
return foo(s) * 2
原因是return foo(s) * 2这个语句出错了,但这还不是最终原因,继续往下看:
File “err.py”, line 3, in foo
return 10 / int(s)
原因是return 10 / int(s)这个语句出错了,这是错误产生的源头,因为下面打印了:
ZeroDivisionError: integer division or modulo by zero
根据错误类型ZeroDivisionError,我们判断,int(s)本身并没有出错,但是int(s)返回0,在计算10 / 0时出错,至此,找到错误源头。
二、调试
1.print()
print()把可能有问题地方,把可能有问题的变量打印出来看看。
2. 断言
凡是用print()来辅助查看的地方,都可以用断言(assert)来替代:
def foo(s):
n = int(s)
assert n != 0, 'n is zero!'
return 10 / n
def main():
foo('0')
assert的意思是,表达式n != 0应该是True,否则,根据程序运行的逻辑,后面的代码肯定会出错。
如果断言失败,assert语句本身就会抛出AssertionError:并且打印出断言后面的语句。
$ python err.py
Traceback (most recent call last):
...
AssertionError: n is zero!
程序中如果到处充斥着assert,和print()相比也好不到哪去。不过,启动Python解释器时可以用-O参数来关闭assert:
$ python -0 err.py
关闭后,你可以把所有的assert语句当成pass来看。
3.logging
把print()替换为logging是第3种方式,和assert比,logging不会抛出错误,而且可以输出到文件:
import logging
logging.basicConfig(level=logging.INFO) #配置level等级
s = '0'
n = int(s)
logging.info('n = %d' % n)
print(10 / n)
这就是logging的好处,它允许你指定记录信息的级别,有debug,info,warning,error等几个级别,当我们指定level=INFO时,logging.debug就不起作用了。同理,指定level=WARNING后,debug和info就不起作用了。
3.pdb.set_trace()
这个方法也是用pdb,但是不需要单步执行,我们只需要import pdb,然后,在可能出错的地方放一个pdb.set_trace(),就可以设置一个断点:
# err.py
import pdb
s = '0'
n = int(s)
pdb.set_trace() # 运行到这里会自动暂停
print(10 / n)
程序会自动在pdb.set_trace()暂停并进入pdb调试环境,可以用命令p查看变量,或者用命令c继续运行:
第九章 IO编程
1.文件读写
(1)普通文件读写
>>> f = open('/Users/michael/test.txt', 'r')
>>>> f.read()
'Hello, world!'
>>> f.close()
调用read()方法可以一次读取文件的全部内容,Python把内容读到内存,用一个str对象表示。
最后一步是调用close()方法关闭文件。文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的:
由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用。所以,为了保证无论是否出错都能正确地关闭文件,我们可以使用try … finally来实现:
try:
f = open('/path/to/file', 'r')
print(f.read())
finally:
if f:
f.close()
但是每次都这么写实在太繁琐,所以,Python引入了with语句来自动帮我们调用close()方法:
with open('/path/to/file', 'r') as f:
print(f.read())
这和前面的try … finally是一样的,但是代码更佳简洁,并且不必调用f.close()方法。
调用readline()可以每次读取一行内容,调用readlines()一次读取所有内容并按行返回list。因此,要根据需要决定怎么调用。
如果文件很小,read()一次性读取最方便,每次最多读取size个字节的内容。;如果不能确定文件大小,反复调用read(size)比较保险;如果是配置文件,调用readlines()最方便:
(2)读取二进制文件
要读取二进制文件,比如图片、视频等等,用’rb’模式打开文件即可:
>>> f = open('/Users/michael/test.jpg', 'rb')
>>> f.read()
(3)字符编码
要读取非UTF-8编码的文本文件,需要给open()函数传入encoding参数,例如,读取GBK编码的文件:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk')
>>> f.read()
'测试'
遇到有些编码不规范的文件,你可能会遇到UnicodeDecodeError,因为在文本文件中可能夹杂了一些非法编码的字符。遇到这种情况,open()函数还接收一个errors参数,表示如果遇到编码错误后如何处理。最简单的方式是直接忽略:
>>> f = open('/Users/michael/gbk.txt', 'r', encoding='gbk', errors='ignore')
(4)写文件
你可以反复调用write()来写入文件,但是务必要调用f.close()来关闭文件。当我们写文件时,操作系统往往不会立刻把数据写入磁盘,而是放到内存缓存起来,空闲的时候再慢慢写入。只有调用close()方法时,操作系统才保证把没有写入的数据全部写入磁盘。忘记调用close()的后果是数据可能只写了一部分到磁盘,剩下的丢失了。所以,还是用with语句来得保险:
with open('/Users/michael/test.txt', 'w') as f:
f.write('Hello, world!')
写入‘hello,world!’
细心的童鞋会发现,以’w’模式写入文件时,如果文件已存在,会直接覆盖(相当于删掉后新写入一个文件)。如果我们希望追加到文件末尾怎么办?可以传入’a’以追加(append)模式写入。
先总结这些吧,其他内容后面边用边学。
参考文献:
廖雪峰官网:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000