机器学习很难,sklearn很简单
好吧,我标题党了,sklearn的简单也是相对于机器学习原理本身,要学好也不容易!
人工智能、机器学习,一听就是高大上的东西,想学会肯定很难。这是当然的,要理解机器学习中的各种算法模型,还是需要较强的数学功底的,这无形中提高了机器学习的门槛。但是只是要用它,却并不困难,scikit-learn的出现给程序员带来了福音,极大的降低了机器学习使用的门槛,即使你不求甚解,也能纯熟的使用各种机器学习的算法来完成自己的目标。
1 sklearn介绍
Scikit learn 也简称 sklearn, 是机器学习领域当中最知名的 python 模块之一.
Sklearn 包含了很多种机器学习的方式:
- Classification 分类
- Regression 回归
- Clustering 非监督分类
- Dimensionality reduction 数据降维
- Model Selection 模型选择
- Preprocessing 数据预处理
我们总能够从这些方法中挑选出一个适合于自己问题的, 然后用来解决自己的问题.
scikit-learn官网:
https://scikit-learn.org/

2 一个栗子
我们还是用一个例子来直观感受一下sklearn的用法。
问题:一个分类问题,把下图所展示的红蓝点分开
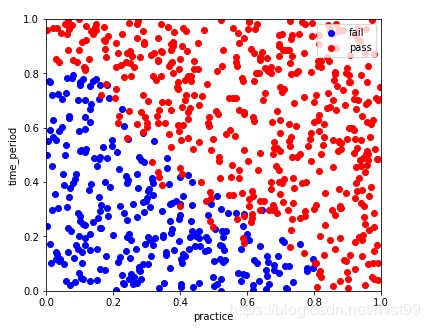
怎么做呢,几行代码搞定:
from sklearn.linear_model import LogisticRegression
#初始化模型
clf_LR = LogisticRegression()
#训练数据
clf_LR.fit(features_train,label_train)
#预测
label pred_LR = clf_LR.predict(features_test)
#评估模型
acc = accuracy_score(pred_LR, label_test)
得到结果:
0.93200000000000005
我们将结果绘制出来是这样的:
plot_pic(clf_LR, features_test, label_test)
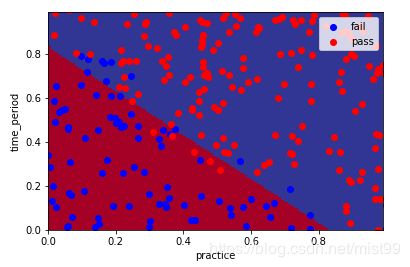
就这么简单的实现了机器学习中逻辑回归分类算法。
3 安装使用
执行安装
pip install scikit-learn
导入模块
需要使用什么算法就import什么模块,如果不知道那个算法对应那个库,这就只能自己记住一些常用的,如果是不常用的,在需要的时候查阅官方文档就行了。
比如上面例子中,我们要用逻辑回归算法,那么就是,从sklearn的linear_model模块中导入LogisticRegression算法子模块。
from sklearn.linear_model import LogisticRegression
4 常用的模块和函数
scikit-learn有哪些模块呢,直接看图吧。
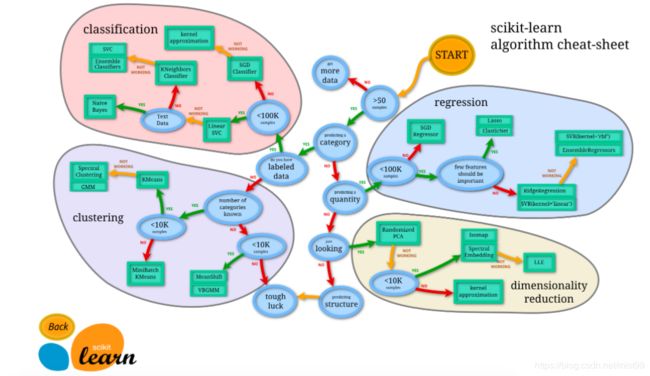
说明:
由图中,可以看到算法有四类,分类,回归,聚类,降维。
也就是我在上一篇文章中提到的四个类别。很多模型实际都覆盖了不同的应用类别。
- 分类和回归是监督式学习,即每个数据对应一个 label。
- 聚类 是非监督式学习,即没有 label。
- 降维,相对比较特殊,是当数据集有很多很多属性的时候,可以通过 降维 算法把属性归纳起来。
常用的算法和模块对应关系
注:以下都是监督学习,无监督学习我们基本用不上,就不列举了
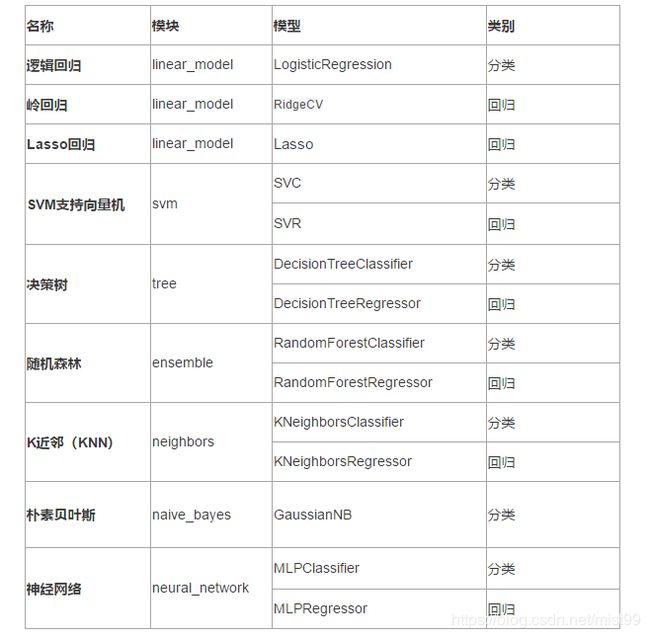
**注:**每个分类都可能对应了不只一个模型,这里只列举了最基本的那个模型,其他可能还有很多变种或扩展。
4、主要流程
下面从机器学习的流程我们来一步步看sklearn提供了什么的功能支持。
获取数据 -> 数据预处理 -> 训练和测试建模 -> 评估模型 -> 保存模型
第一步:获取数据
要进行数据分析,首先得有数据。sklearn提供了我们两种方法:
- 直接导入sklearn小数据集做测试用。
- 用sklearn提供的接口自己创建数据集。
1.导入sklearn自带数据集
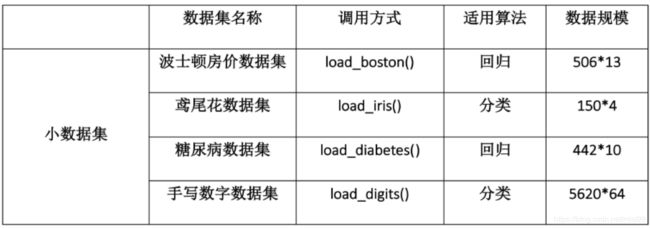
使用方式:
from sklearn import datasets
iris = datasets.load_iris() # 导入数据集
X = iris.data # 获得其特征向量
y = iris.target # 获得样本label
2.创建数据集
使用方式:
from sklearn.datasets.samples_generator import make_classification
X, y = make_classification(n_samples=6, n_features=5, n_informative=2,
n_redundant=2, n_classes=2, n_clusters_per_class=2, scale=1.0,
random_state=20)
#n_samples:指定样本数,n_features:指定特征数,
#n_classes:指定几分类,random_state:随机种子,使得随机状可重
更多内容参看官网文档
https://scikit-learn.org/stable/datasets/
说明:
在金融数据分析中,我们都是采用股票/期货等金融数据,有专门的数据获取渠道,上面这些通过sklearn获取数据的方式了解一下就行了。
第二步:数据预处理
数据预处理阶段是很重要的一环,只有预处理后的数据才能被模型或评估器所接受。数据的预处理主要包含这几个方面的工作:
- 特征提取
- 特征归一化
- 特征标准化
- 分割数据集
需要导入的模块
from sklearn import preprocessing
1.特征提取
我们获取的数据中很多数据往往有很多维度,但并不是所有的维度都是有用的,有意义的,所以我们要将对结果影响较小的维度舍去,保留对结果影响较大的维度。PCA(主成分分析)与LDA(线性评价分析)是特征提取的两种经典算法。
LDA用法举例
import sklearn.discriminant_analysis as sk_discriminant_analysis
lda = sk_discriminant_analysis.LinearDiscriminantAnalysis(n_components=2)
lda.fit(iris_X,iris_y)
reduced_X = lda.transform(iris_X) #reduced_X为降维后的数据
print('LDA:')
print ('LDA的数据中心点:',lda.means_) #中心点
print ('LDA做分类时的正确率:',lda.score(X_test, y_test)) #score是指分类的正确率
print ('LDA降维后特征空间的类中心:',lda.scalings_) #降维后特征空间的类中心
2.特征归一化
为了使得训练数据的标准化规则与测试数据的标准化规则同步,preprocessing中提供了很多Scaler:
data = [[0, 0], [0, 0], [1, 1], [1, 1]]
基于mean和std的标准化
scaler = preprocessing.StandardScaler().fit(train_data)
scaler.transform(train_data)
scaler.transform(test_data)
将每个特征值归一化到一个固定范围
scaler = preprocessing.MinMaxScaler(feature_range=(0, 1)).fit(train_data)
scaler.transform(train_data)
scaler.transform(test_data)
#feature_range: 定义归一化范围,注用()括起来
3.特征标准化
当你想要计算两个样本的相似度时必不可少的一个操作,就是正则化。其思想是:首先求出样本的p-范数,然后该样本的所有元素都要除以该范数,这样最终使得每个样本的范数都为1。
>>> X = [[ 1., -1., 2.],
... [ 2., 0., 0.],
... [ 0., 1., -1.]]
>>> X_normalized = preprocessing.normalize(X, norm='l2')
>>> X_normalized
array([[ 0.40..., -0.40..., 0.81...],
[ 1. ..., 0. ..., 0. ...],
[ 0. ..., 0.70..., -0.70...]])
4.分割数据集
在得到训练数据集时,通常我们经常会把训练数据集进一步拆分成训练集和验证集,这样有助于我们模型参数的选取。
作用:将数据集划分为 训练集和测试集
格式:train_test_split(*arrays, **options)
from sklearn.mode_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
第三步:训练和测试模型
定义模型
在这一步我们首先要分析自己数据的类型,搞清出你要用什么模型来做,然后我们就可以在sklearn中定义模型了。使用上几乎都是同一种模式,只是参数不同。
拟合模型
model.fit(X_train, y_train)
预测模型
model.predict(X_test)
前面例子中已经包含了,这儿再抄一遍。以逻辑回归为例子,如果是其他模型,直接替换相应的名称就可以了
#导入模型
from sklearn.linear_model import LogisticRegression #从sklearn中引入逻辑回归算法;必背;
#定义了逻辑回归的分类器
clf_LR = LogisticRegression()
#训练和学习
clf_LR.fit(features_train,label_train)
#预测测试集
pred_LR = clf_LR.predict(features_test)
#拿预测的测试集的label去跟真实的测试集的label去比较、打分
acc = accuracy_score(pred_LR, label_test)
得到结果:
0.93200000000000005
第四步:评估模型
model.predict(x_test) 返回测试样本的预测标签
model.score(predict,label_test) 根据预测值和真实值计算平分
为模型进行打分
model.score(data_X, data_y)
score()对不同类型模型评价标准是不一样的。
- 回归模型:使用“决定系数”评分(coefficient of Determination)
- 分类模型:使用“准确率”评分(accuracy)
第五步:保存模型
最后,我们可以将我们训练好的model保存到本地,或者放到线上供用户使用,那么如何保存训练好的model呢?主要有下面两种方式:
1.读取pickle文件
import pickle
#保存模型
with open('model.pickle', 'wb') as f:
pickle.dump(model, f)
#读取模型
with open('model.pickle', 'rb') as f:
model = pickle.load(f)
model.predict(X_test)
2.使用joblib模块
from sklearn.externals import joblib
#保存模型
joblib.dump(model, 'model.pickle')
#载入模型
model = joblib.load('model.pickle')
至此,用sklearn进行机器学习的方法已经介绍完了,下一篇会进行实战应用:
选择一种模型来对真实的股票数据进行涨跌预测
参考文档
官方例子
https://scikit-learn.org/stable/auto_examples/index.html
中文文档
http://sklearn.apachecn.org/#/