暑期实习准备--操作系统
操作系统
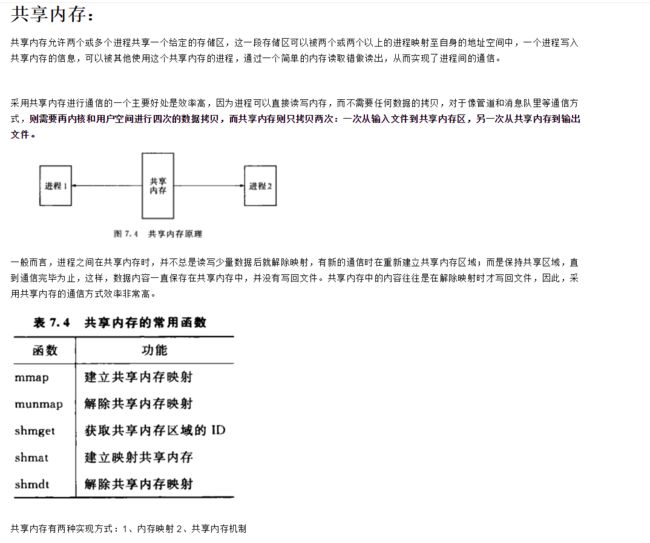
进程间通信:




Linux 系统下你关注过哪些内核参数,说说你知道的。

Tcp/ip io cpu memory
net.ipv4.tcp_syncookies = 1
#启用syncookies
net.ipv4.tcp_max_syn_backlog = 8192
#SYN队列长度
net.ipv4.tcp_synack_retries=2
#SYN ACK重试次数
net.ipv4.tcp_fin_timeout = 30
#主动关闭方FIN-WAIT-2超时时间
net.ipv4.tcp_keepalive_time = 1200
#TCP发送keepalive消息的频度
net.ipv4.tcp_tw_reuse = 1
#开启TIME-WAIT重用
net.ipv4.tcp_tw_recycle = 1
#开启TIME-WAIT快速回收
net.ipv4.ip_local_port_range = 1024 65000
#向外连接的端口范围
net.ipv4.tcp_max_tw_buckets = 5000
#最大TIME-WAIT数量,超过立即清除
net.ipv4.tcp_syn_retries = 2
#SYN重试次数
echo “fs.file-max=65535” >> /etc/sysctl.conf
sysctl -p
http://www.haiyun.me/category/system/
Linux 下 IO 模型有几种,各自的含义是什么。
阻塞式io,非阻塞io,io复用模型,信号驱动io模型,异步io模型。
https://yq.aliyun.com/articles/46404
https://yq.aliyun.com/articles/46402
epoll 和 poll 有什么区别。
select的本质是采用32个整数的32位,即32*32= 1024来标识,fd值为1-1024。当fd的值超过1024限制时,就必须修改FD_SETSIZE的大小。这个时候就可以标识32*max值范围的fd。
对于单进程多线程,每个线程处理多个fd的情况,select是不适合的。
1.所有的线程均是从1-32*max进行扫描,每个线程处理的均是一段fd值,这样做有点浪费
2.1024上限问题,一个处理多个用户的进程,fd值远远大于1024
所以这个时候应该采用poll,
poll传递的是数组头指针和该数组的长度,只要数组的长度不是很长,性能还是很不错的,因为poll一次在内核中申请4K(一个页的大小来存放fd),尽量控制在4K以内
epoll还是poll的一种优化,返回后不需要对所有的fd进行遍历,在内核中维持了fd的列表。select和poll是将这个内核列表维持在用户态,然后传递到内核中。但是只有在2.6的内核才支持。
epoll更适合于处理大量的fd ,且活跃fd不是很多的情况,毕竟fd较多还是一个串行的操作
https://yq.aliyun.com/articles/10525
平时用到哪些 Linux 命令。
Ls,find,tar,tail,cp,rm,vi,grep,ps,pkill等等
https://yq.aliyun.com/articles/69417?spm=5176.100240.searchblog.18.Zrbh9R
用一行命令查看文件的最后五行。
Tail -n 5 filename
用一行命令输出正在运行的 java 进程。
ps -ef|grep Java
介绍下你理解的操作系统中线程切换过程。
控制权的转换,根据优先级切换上下文(用户,寄存器,系统)
http://www.cnblogs.com/kkshaq/p/4544426.html
进程和线程的区别。
Linux 实现并没有区分这两个概念(进程和线程)
1. 进程:程序的一次执行
2. 线程:CPU的基本调度单位
一个进程可以包含多个线程。
http://www.ruanyifeng.com/blog/2013/04/processes_and_threads.html
多线程
多线程的几种实现方式,什么是线程安全。
实现runable接口,继承thread类。
http://ifeve.com/java-multi-threading-concurrency-interview-questions-with-answers/
volatile 的原理,作用,能代替锁么。
Volatile利用内存栅栏机制来保持变量的一致性。不能代替锁,其只具备数据可见性一致性,不具备原子性。
http://blog.csdn.net/gongzi2311/article/details/20715185
画一个线程的生命周期状态图。
新建,可运行,运行中, 睡眠,阻塞,等待,死亡。 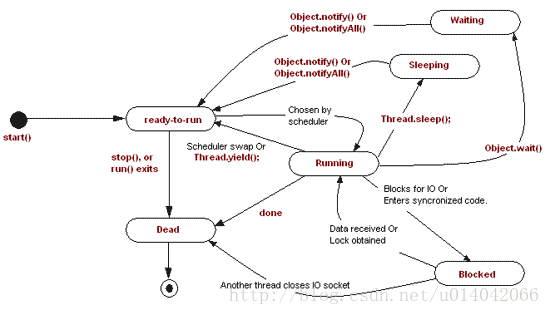
http://ifeve.com/thread-status
sleep 和 wait 的区别。
Sleep是休眠线程,wait是等待,sleep是thread的静态方法,wait则是object的方法。
Sleep依旧持有锁,并在指定时间自动唤醒。wait则释放锁。
http://www.jianshu.com/p/4ec3f4b3903d
Lock 与 Synchronized 的区别。
首先两者都保持了并发场景下的原子性和可见性,区别则是synchronized的释放锁机制是交由其自身控制,且互斥性在某些场景下不符合逻辑,无法进行干预,不可人为中断等。
而lock常用的则有ReentrantLock和readwritelock两者,添加了类似锁投票、定时锁等候和可中断锁等候的一些特性。此外,它还提供了在激烈争用情况下更佳的性能。
http://blog.csdn.net/vking_wang/article/details/9952063
synchronized 的原理是什么,解释以下名词:重排序,自旋锁,偏向锁,轻量级锁,可重入锁,公平锁,非公平锁,乐观锁,悲观锁。
Synchronized底层是通过监视器的enter和exit实现
https://my.oschina.net/cnarthurs/blog/847801
http://blog.csdn.net/a314773862/article/details/54095819
用过哪些原子类,他们的原理是什么。
AtomicInteger; AtomicLong; AtomicReference; AtomicBoolean;基于CAS原语实现 ,比较并交换、加载链接/条件存储,最坏的情况下是旋转锁
https://www.ibm.com/developerworks/cn/java/j-jtp11234/index.html
http://www.jmatrix.org/java/848.html
用过线程池吗,newCache 和 newFixed 有什么区别,他们的原理简单概括下,构造函数的各个参数的含义是什么,比如 coreSize,maxsize 等。
newSingleThreadExecutor返回以个包含单线程的Executor,将多个任务交给此Exector时,这个线程处理完一个任务后接着处理下一个任务,若该线程出现异常,将会有一个新的线程来替代。
newFixedThreadPool返回一个包含指定数目线程的线程池,如果任务数量多于线程数目,那么没有没有执行的任务必须等待,直到有任务完成为止。
newCachedThreadPool根据用户的任务数创建相应的线程来处理,该线程池不会对线程数目加以限制,完全依赖于JVM能创建线程的数量,可能引起内存不足。
底层是基于ThreadPoolExecutor实现,借助reentrantlock保证并发。
coreSize核心线程数,maxsize最大线程数。
http://ifeve.com/java-threadpoolexecutor/
线程池的关闭方式有几种,各自的区别是什么。
Shutdown shutdownNow tryTerminate 清空工作队列,终止线程池中各个线程,销毁线程池
http://blog.csdn.net/xxcupid/article/details/51993235
假如有一个第三方接口,有很多个线程去调用获取数据,现在规定每秒钟最多有 10 个线程同时调用它,如何做到。
ScheduledThreadPoolExecutor 设置定时,进行调度。
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory) {
super(corePoolSize, Integer.MAX_VALUE, 0, TimeUnit.NANOSECONDS,
new DelayedWorkQueue(), threadFactory);
}
http://ifeve.com/java-scheduledthreadpoolexecutor/
spring 的 controller 是单例还是多例,怎么保证并发的安全。
单例
通过单例工厂 DefaultSingletonBeanRegistry实现单例
通过保AsyncTaskExecutor持安全
用三个线程按顺序循环打印 abc 三个字母,比如 abcabcabc。
public static void main(String[] args) {
final String str=”abc”;
ExecutorService executorService= Executors.newFixedThreadPool(3);
executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println(“1”+str);
}
});executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println(“2”+str);
}
});executorService.execute(new Runnable() {
@Override
public void run() {
System.out.println(“2”+str);
}
});
}
ThreadLocal 用过么,用途是什么,原理是什么,用的时候要注意什么。
Threadlocal底层是通过threadlocalMap进行存储键值 每个ThreadLocal类创建一个Map,然后用线程的ID作为Map的key,实例对象作为Map的value,这样就能达到各个线程的值隔离的效果。
ThreadLocal的作用是提供线程内的局部变量,这种变量在线程的生命周期内起作用,减少同一个线程内多个函数或者组件之间一些公共变量的传递的复杂度。
谁设置谁负责移除
http://qifuguang.me/2015/09/02/[Java%E5%B9%B6%E5%8F%91%E5%8C%85%E5%AD%A6%E4%B9%A0%E4%B8%83]%E8%A7%A3%E5%AF%86ThreadLocal/
如果让你实现一个并发安全的链表,你会怎么做。
Collections.synchronizedList() ConcurrentLinkedQueue
http://blog.csdn.net/xingjiarong/article/details/48046751
有哪些无锁数据结构,他们实现的原理是什么。
LockFree,CAS
基于jdk提供的原子类原语实现,例如AtomicReference
http://blog.csdn.net/b_h_l/article/details/8704480
讲讲 java 同步机制的 wait 和 notify。
首先这两个方法只能在同步代码块中调用,wait会释放掉对象锁,等待notify唤醒。
http://blog.csdn.net/ithomer/article/details/7685594
多线程如果线程挂住了怎么办。
根据具体情况(sleep,wait,join等),酌情选择notifyAll,notify进行线程唤醒。
http://blog.chinaunix.net/uid-122937-id-215913.html
countdowlatch 和 cyclicbarrier 的内部原理和用法,以及相互之间的差别。
CountDownLatch是一个同步辅助类,在完成一组正在其他线程中执行的操作之前,它运行一个或者多个线程一直处于等待状态。
CyclicBarrier要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
CyclicBarrier初始化的时候,设置一个屏障数。线程调用await()方法的时候,这个线程就会被阻塞,当调用await()的线程数量到达屏障数的时候,主线程就会取消所有被阻塞线程的状态。
前者是递减,不可循环,后者是递加,可循环用
countdowlatch 基于abq cb基于ReentrantLock Condition
http://www.jianshu.com/p/a101ae9797e3
http://blog.csdn.net/tolcf/article/details/50925145
使用 synchronized 修饰静态方法和非静态方法有什么区别。
对象锁和类锁
https://yq.aliyun.com/articles/24226
简述 ConcurrentLinkedQueue LinkedBlockingQueue 的用处和不同之处。
LinkedBlockingQueue 是一个基于单向链表的、范围任意的(其实是有界的)、FIFO 阻塞队列。
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,它采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部,当我们获取一个元素时,它会返回队列头部的元素。它采用了“wait-free”算法来实现,该算法在Michael & Scott算法上进行了一些修改, Michael & Scott算法的详细信息可以参见参考资料一。
http://ifeve.com/concurrentlinkedqueue/
http://ifeve.com/juc-linkedblockingqueue/
http://blog.csdn.net/xiaohulunb/article/details/38932923
导致线程死锁的原因?怎么解除线程死锁。
死锁问题是多线程特有的问题,它可以被认为是线程间切换消耗系统性能的一种极端情况。在死锁时,线程间相互等待资源,而又不释放自身的资源,导致无穷无尽的等待,其结果是系统任务永远无法执行完成。死锁问题是在多线程开发中应该坚决避免和杜绝的问题。
一般来说,要出现死锁问题需要满足以下条件:
1. 互斥条件:一个资源每次只能被一个线程使用。
2. 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
3. 不剥夺条件:进程已获得的资源,在未使用完之前,不能强行剥夺。
4. 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
只要破坏死锁 4 个必要条件之一中的任何一个,死锁问题就能被解决。
https://www.ibm.com/developerworks/cn/java/j-lo-deadlock/
非常多个线程(可能是不同机器),相互之间需要等待协调,才能完成某种工作,问怎么设计这种协调方案。
此问题的本质是保持顺序执行。可以使用executors