Java IO笔记(StreamTokenizer)
本篇讲述的是java io包中的StreamTokenizer类。
StreamTokenize类可以将任意的输入流分割为一系列标记(token),然后可以每次读取一个标记,先附上源码,进行简单地分析。
StreamTokenizer.java:
package java.io;
import java.util.Arrays;
public class StreamTokenizer {
//内部声明了一个Reader对象句柄和一个InputStream对象句柄,用于接收读取流。
private Reader reader = null;
private InputStream input = null;
//声明了一个char类型的数组,初始容量为20,用于存储读取时标记的内容,读取时,可以根据实际需要自动扩容。
private char buf[] = new char[20];
//声明了一个int型变量peekc,当调用nextToken方法的时候,peekc作为一个状态,用于判断是否需要继续读取下一个字符放入到标记中,初始化时赋值为NEED_CHAR。
private int peekc = NEED_CHAR;
//定义了两个常量,NEED_CHAR和SKIP_LF都表示要读取下一个字符,但后者如果遇到一个'\n',则会将它丢弃然后读取下一个字符。
private static final int NEED_CHAR = Integer.MAX_VALUE;
private static final int SKIP_LF = Integer.MAX_VALUE - 1;
//声明了一个boolean型变量pushedBack,该变量用于控制执行nextToken方法时,是否需要进行回退。
private boolean pushedBack;
//声明了一个boolean型变量forceLower,该变量用于控制sval是否需要进行小写处理。
private boolean forceLower;
//声明了一个int型变量,用于记录最后一次读取标记时的行数。
private int LINENO = 1;
private boolean eolIsSignificantP = false;
private boolean slashSlashCommentsP = false;
private boolean slashStarCommentsP = false;
//声明了一个一个数组作为一个语法表,存放几种类型,依次为空格,数字,字母,引号,注解等类型。
private byte ctype[] = new byte[256];
private static final byte CT_WHITESPACE = 1;
private static final byte CT_DIGIT = 2;
private static final byte CT_ALPHA = 4;
private static final byte CT_QUOTE = 8;
private static final byte CT_COMMENT = 16;
//声明了一个int型变量,表明当前标记的标记类型,初始化时为TT_NOTHING类型。
public int ttype = TT_NOTHING;
//定义了一个常量,表示此时已经读取到了流的末尾。
public static final int TT_EOF = -1;
//定义了一个常量,表示此时已经读到了一行的末尾。
public static final int TT_EOL = '\n';
//定义了一个常量,表示此时读到的标记是一个数字标记。
public static final int TT_NUMBER = -2;
//定义了一个常量,表示此时读到的标记是一个文本标记。
public static final int TT_WORD = -3;
//定义了一个常量,表示此时并没有进行标记的读取,用于初始化ttype。
private static final int TT_NOTHING = -4;
//声明了一个字符串型变量sval,如果当前的标记为字符串,那么此时将当前标记的值赋值给sval。
public String sval;
//声明了一个double型变量nval,如果当前的标记为数值,那么此时将当前标记的值赋值给nval。
public double nval;
/**
* 一个私有的构造函数,用于初始化内置的语法表,即ctype数组。
*/
private StreamTokenizer() {
wordChars('a', 'z');
wordChars('A', 'Z');
wordChars(128 + 32, 255);
whitespaceChars(0, ' ');
commentChar('/');
quoteChar('"');
quoteChar('\'');
parseNumbers();
}
/**
* 一个带一个参数的构造函数,传入的参数为一个InputStream对象,先对其进行安全检测,如果不为null,则赋值给最初声明的InputStream对象句柄,input。值得注
* 意的是该方法如今已经被弃用了。
*/
@Deprecated
public StreamTokenizer(InputStream is) {
this();
if (is == null) {
throw new NullPointerException();
}
input = is;
}
/**
*一个带一个参数的构造函数,传入的参数为一个Reader对象,先对其进行安全检测,如果不为null,则赋值给最初声明的Reader对象句柄,reader。
*/
public StreamTokenizer(Reader r) {
this();
if (r == null) {
throw new NullPointerException();
}
reader = r;
}
/**
* 该方法用于重置标记的语法表,通过一个循环,将语法表中的每一个元素都置为0,即当做普通字符进行处理。
*/
public void resetSyntax() {
for (int i = ctype.length; --i >= 0;)
ctype[i] = 0;
}
/**
* 用于初始化语法表,传入的两个参数,为语法表的前后区间,将传入区间内的数据
*/
public void wordChars(int low, int hi) {
if (low < 0)
low = 0;
if (hi >= ctype.length)
hi = ctype.length - 1;
while (low <= hi)
ctype[low++] |= CT_ALPHA;
}
/**
* 用于初始化语法表,传入的两个参数,为语法表的前后区间,将传入区间内的数据都做为空白空格处理。
*/
public void whitespaceChars(int low, int hi) {
if (low < 0)
low = 0;
if (hi >= ctype.length)
hi = ctype.length - 1;
while (low <= hi)
ctype[low++] = CT_WHITESPACE;
}
/**
* 用于初始化语法表,传入的两个参数,为语法表的前后区间,将传入区间内的数据都做为普通字符处理。
*/
public void ordinaryChars(int low, int hi) {
if (low < 0)
low = 0;
if (hi >= ctype.length)
hi = ctype.length - 1;
while (low <= hi)
ctype[low++] = 0;
}
/**
* 用于初始化语法表,通过传入的参数作为语法表的索引,将对应的类型该为0,这样便会当做普通字符处理。
*/
public void ordinaryChar(int ch) {
if (ch >= 0 && ch < ctype.length)
ctype[ch] = 0;
}
/**
* 用于初始化语法表,以传入的int型值为索引,将其对应的数组划分到CT_COMMENT注解类型。
*/
public void commentChar(int ch) {
if (ch >= 0 && ch < ctype.length)
ctype[ch] = CT_COMMENT;
}
/**
* 用于初始化语法表,以传入的int型值为索引,将其对应的数组划分到CT_QUOTE引用类型。
*/
public void quoteChar(int ch) {
if (ch >= 0 && ch < ctype.length)
ctype[ch] = CT_QUOTE;
}
/**
* 用于初始化语法表,将数字0-9,'.','-'划分到CT_DIGIT数字类型。
*/
public void parseNumbers() {
for (int i = '0'; i <= '9'; i++)
ctype[i] |= CT_DIGIT;
ctype['.'] |= CT_DIGIT;
ctype['-'] |= CT_DIGIT;
}
/**
* 该方法用于设置eolIsSignificant变量的值,该值用来恒定是否将行的结尾当做一个标记来处理。
*/
public void eolIsSignificant(boolean flag) {
eolIsSignificantP = flag;
}
/**
* 该方法用于设置slashStarCommnetsP的值,该值用于恒定是否将c语言形式的注释当做特殊字符处理,如果为true,则所有包含在注释内的内容会被丢弃。为false,则
* 当做普通字符处理。
*/
public void slashStarComments(boolean flag) {
slashStarCommentsP = flag;
}
/**
* 该方法与上一个方法类似,不过是用来恒定是否认可c++形式的注释。
*/
public void slashSlashComments(boolean flag) {
slashSlashCommentsP = flag;
}
/**
* 该方法用于修改forceLower变量的值。
*/
public void lowerCaseMode(boolean fl) {
forceLower = fl;
}
/**
* 定义了一个read方法,实际上是通过调用内置的reader/input 的read方法,从中看出,优先是使用reader来进去读取的。
*/
private int read() throws IOException {
if (reader != null)
return reader.read();
else if (input != null)
return input.read();
else
throw new IllegalStateException();
}
/**
* 该方法用于获取下一个标记。
*/
public int nextToken() throws IOException {
//判断是否需要进行回退,如果pushedBack值为true,则直接返回上一个标记的类型,同时将pushedBack的值重置为false。
if (pushedBack) {
pushedBack = false;
return ttype;
}
byte ct[] = ctype;
sval = null;
int c = peekc;
if (c < 0)
c = NEED_CHAR;
if (c == SKIP_LF) {
c = read();
if (c < 0)
return ttype = TT_EOF;
if (c == '\n')
c = NEED_CHAR;
}
if (c == NEED_CHAR) {
c = read();
if (c < 0)
return ttype = TT_EOF;
}
ttype = c;
//将peekc重置,方便下一次进入方法时使用
peekc = NEED_CHAR;
//如果当前类型是空格,进行的操作
int ctype = c < 256 ? ct[c] : CT_ALPHA;
while ((ctype & CT_WHITESPACE) != 0) {
if (c == '\r') {
LINENO++;
if (eolIsSignificantP) {
peekc = SKIP_LF;
return ttype = TT_EOL;
}
c = read();
if (c == '\n')
c = read();
} else {
if (c == '\n') {
LINENO++;
if (eolIsSignificantP) {
return ttype = TT_EOL;
}
}
c = read();
}
if (c < 0)
return ttype = TT_EOF;
ctype = c < 256 ? ct[c] : CT_ALPHA;
}
//如果当前类型为数字的操作
if ((ctype & CT_DIGIT) != 0) {
boolean neg = false;
if (c == '-') {
c = read();
if (c != '.' && (c < '0' || c > '9')) {
peekc = c;
return ttype = '-';
}
neg = true;
}
double v = 0;
int decexp = 0;
int seendot = 0;
while (true) {
if (c == '.' && seendot == 0)
seendot = 1;
else if ('0' <= c && c <= '9') {
v = v * 10 + (c - '0');
decexp += seendot;
} else
break;
c = read();
}
peekc = c;
if (decexp != 0) {
double denom = 10;
decexp--;
while (decexp > 0) {
denom *= 10;
decexp--;
}
v = v / denom;
}
nval = neg ? -v : v;
return ttype = TT_NUMBER;
}
//如果当前类型为字母符号的操作
if ((ctype & CT_ALPHA) != 0) {
int i = 0;
do {
if (i >= buf.length) {
//自动扩容
buf = Arrays.copyOf(buf, buf.length * 2);
}
buf[i++] = (char) c;
c = read();
ctype = c < 0 ? CT_WHITESPACE : c < 256 ? ct[c] : CT_ALPHA;
} while ((ctype & (CT_ALPHA | CT_DIGIT)) != 0);
peekc = c;
sval = String.copyValueOf(buf, 0, i);
if (forceLower)
sval = sval.toLowerCase();
return ttype = TT_WORD;
}
//如果当前类型为引用符号的操作
if ((ctype & CT_QUOTE) != 0) {
ttype = c;
int i = 0;
int d = read();
while (d >= 0 && d != ttype && d != '\n' && d != '\r') {
if (d == '\\') {
c = read();
int first = c; /* To allow \377, but not \477 */
if (c >= '0' && c <= '7') {
c = c - '0';
int c2 = read();
if ('0' <= c2 && c2 <= '7') {
c = (c << 3) + (c2 - '0');
c2 = read();
if ('0' <= c2 && c2 <= '7' && first <= '3') {
c = (c << 3) + (c2 - '0');
d = read();
} else
d = c2;
} else
d = c2;
} else {
switch (c) {
case 'a':
c = 0x7;
break;
case 'b':
c = '\b';
break;
case 'f':
c = 0xC;
break;
case 'n':
c = '\n';
break;
case 'r':
c = '\r';
break;
case 't':
c = '\t';
break;
case 'v':
c = 0xB;
break;
}
d = read();
}
} else {
c = d;
d = read();
}
if (i >= buf.length) {
buf = Arrays.copyOf(buf, buf.length * 2);
}
buf[i++] = (char)c;
}
peekc = (d == ttype) ? NEED_CHAR : d;
sval = String.copyValueOf(buf, 0, i);
return ttype;
}
//关于对待注解形式的处理。
if (c == '/' && (slashSlashCommentsP || slashStarCommentsP)) {
c = read();
if (c == '*' && slashStarCommentsP) {
int prevc = 0;
while ((c = read()) != '/' || prevc != '*') {
if (c == '\r') {
LINENO++;
c = read();
if (c == '\n') {
c = read();
}
} else {
if (c == '\n') {
LINENO++;
c = read();
}
}
if (c < 0)
return ttype = TT_EOF;
prevc = c;
}
return nextToken();
} else if (c == '/' && slashSlashCommentsP) {
while ((c = read()) != '\n' && c != '\r' && c >= 0);
peekc = c;
return nextToken();
} else {
if ((ct['/'] & CT_COMMENT) != 0) {
while ((c = read()) != '\n' && c != '\r' && c >= 0);
peekc = c;
return nextToken();
} else {
peekc = c;
return ttype = '/';
}
}
}
//对于当前类型是注解时的操作。
if ((ctype & CT_COMMENT) != 0) {
while ((c = read()) != '\n' && c != '\r' && c >= 0);
peekc = c;
return nextToken();
}
return ttype = c;
}
/**
* 调用该方法时,首先进行安全检测,如果ttype不为TT_NOTHING,即已经调用过nextToken方法,那么将pushedBack的值设为true,下一次执行nextToeken方法时,
* 便不会修改当前标记的类型,同时也不会去修改当前nval或者sval的值。
*/
public void pushBack() {
if (ttype != TT_NOTHING)
pushedBack = true;
}
/**
* 该方法返回LINENO的值,即分割标记后最后的行数,值得注意的是如果将换行符设置为普通字符的话,会影响该方法的准确性。
*/
public int lineno() {
return LINENO;
}
/**
* 该方法可以得到一个字符串,字符串内容为当前标记的类型,以及标记所在的行数。
*/
public String toString() {
String ret;
switch (ttype) {
case TT_EOF:
ret = "EOF";
break;
case TT_EOL:
ret = "EOL";
break;
case TT_WORD:
ret = sval;
break;
case TT_NUMBER:
ret = "n=" + nval;
break;
case TT_NOTHING:
ret = "NOTHING";
break;
default: {
if (ttype < 256 &&
((ctype[ttype] & CT_QUOTE) != 0)) {
ret = sval;
break;
}
char s[] = new char[3];
s[0] = s[2] = '\'';
s[1] = (char) ttype;
ret = new String(s);
break;
}
}
return "Token[" + ret + "], line " + LINENO;
}
}package dataInOut;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.StreamTokenizer;
import java.io.UnsupportedEncodingException;
public class DataTest {
public static void main(String[] args) throws UnsupportedEncodingException,
FileNotFoundException {
//通过传入一个FileReader来构建一个StreamTokenizer。这里读取的是本地的一个txt文件。
StreamTokenizer stk = new StreamTokenizer(new FileReader(new File(
"E:\\workspaceforlibgdx\\IOStudy\\src\\file\\test.txt")));
//1 stk.resetSyntax();
//2 stk.ordinaryChar('\"');
//3 stk.ordinaryChar('/');
try {
//当没有读取到文件结尾时,不停调用nextToken方法,然后将每一个token及其行号打印出来。
while (stk.nextToken() != StreamTokenizer.TT_EOF) {
String s = null;
switch (stk.ttype) {
case StreamTokenizer.TT_WORD:
s = stk.sval;
break;
case StreamTokenizer.TT_NUMBER:
s = String.valueOf(stk.nval);
break;
default:
s = stk.sval;
}
System.out.println(stk.toString());
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
这是读取的test.txt文本的内容:

这是控制台打印的内容:
这里我们注意到的是通过nextToken中方法读取的数字型数据都是double类型的,如果不符合要求,需自行进行转换。
下面我们通过修改test.txt文本中的内容,再次运行时,会得到不一样的输出打印:
从打印中可以看出,被引号所包裹的内容无论长短,都被当做一个token处理,被注释掉的内容在读取时会被舍弃。如果想让这写符号被当做普通符号来进行处理,只需调用StreamTokenizer类中的ondinaryChar或者ondinaryChars方法便可以将特殊的字符也当做普通字符处理,比如我们本次的例子中,放开注释2,3,便可以将引号和注释符号当做普通符号处理,执行代码后可以得到如下打印: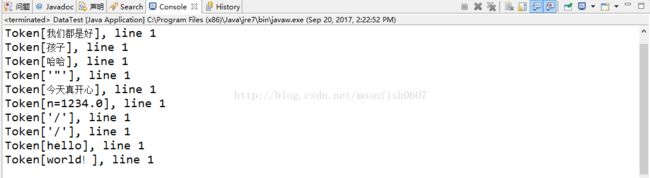
如果放开注释1的话,则会把所有的字符都当做普通字符处理。这里要注意的是有时有人会把token数和字符数混淆在一起,从上面的例子中也可以看出,token数是不等于字符数的。StreamTokenizer类可以用于分析一个流中文本,数字等不同类型数据的次数。最后它还有一个使用方法,用于我们基本的输入操作:
package dataInOut;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.io.StreamTokenizer;
public class DataTest
{
public static void main(String[] args) throws IOException
{
//将标准输入流传入StreamTokenizer中。
StreamTokenizer in = new StreamTokenizer(new BufferedReader(new InputStreamReader(System.in)));
PrintWriter out = new PrintWriter(new OutputStreamWriter(System.out));
int a, b;
while(in.nextToken() != StreamTokenizer.TT_EOF)
{
a = (int)in.nval;
in.nextToken();
b = (int)in.nval;
//out.println(a + b);
System.out.println("a + b = "+(a+b));
}
//将缓存区中的数据真实写出。
out.flush();
}
}以上为本篇内容。