TVCG Collaborative Large-Scale Dense 3D Reconstruction with Online Inter-Agent Pose Optimisation
Golodetz S, Cavallari T, Lord N A, et al. Collaborative Large-Scale Dense 3D Reconstruction with Online Inter-Agent Pose Optimisation[J]. IEEE transactions on visualization and computer graphics, 2018, 24(11): 2895-2905.

Abstract
—Reconstructing dense, volumetric models of real-world 3D scenes is important for many tasks, but capturing large scenes can take significant time, and the risk of transient changes to the scene goes up as the capture time increases. These are good reasons to want instead to capture several smaller sub-scenes that can be joined to make the whole scene. Achieving this has traditionally been difficult: joining sub-scenes that may never have been viewed from the same angle requires a high-quality camera relocaliser that can cope with novel poses, and tracking drift in each sub-scene can prevent them from being joined to make a consistent overall scene. Recent advances, however, have significantly improved our ability to capture medium-sized sub-scenes with little to no tracking drift: real-time globally consistent reconstruction systems can close loops and re-integrate the scene surface on the fly, whilst new visual-inertial odometry approaches can significantly reduce tracking drift during live reconstruction. Moreover, high-quality regression forest-based relocalisers have recently been made more practical by the introduction of a method to allow them to be trained and used online. In this paper, we leverage these advances to present what to our knowledge is the first system to allow multiple users to collaborate interactively to reconstruct dense, voxel-based models of whole buildings using only consumer-grade hardware, a task that has traditionally been both time-consuming and dependent on the availability of specialised hardware. Using our system, an entire house or lab can be reconstructed in under half an hour and at a far lower cost than was previously possible.
Approach
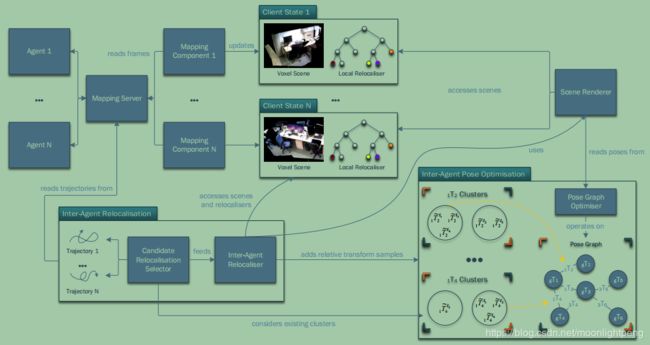
Fig. 3: The architecture of our system. Individual agents track their poses and feed posed RGB-D frames to the mapping server. A separate mapping component is instantiated for each agent, which reconstructs a voxel scene and trains a local relocaliser. Separately, the candidate relocalisation selector repeatedly selects a pose from one of the agents’ trajectories for relocalisation against another scene. The inter-agent relocaliser uses the scene renderer to render synthetic RGB and depth images of the corresponding scene from the selected pose, and passes them to the local relocaliser of the target scene. If a relocalisation succeeds (and is verified, see §3.3.1), a sample of the relative transform between the two scenes is recorded. The relative transform samples for each scene pair are clustered for robustness (see §3.3.2). Whenever the cluster to which a sample is added is sufficiently large, we construct a pose graph by blending the relative poses in the largest clusters, and trigger a pose
graph optimisation. The optimised poses are then used for rendering the overall scene.
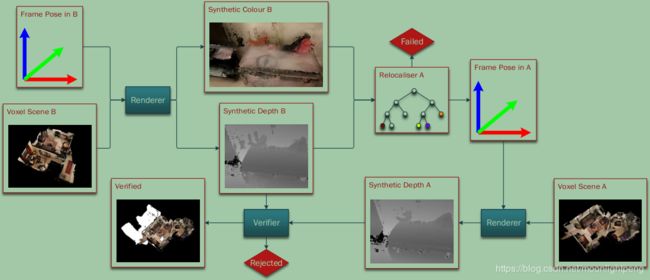
Fig. 4: To relocalise the scene of an agent b against that of another agent a, we first choose an arbitrary frame from b’s trajectory and render synthetic RGB and depth raycasts of b’s scene from the frame’s pose. Then, we try to relocalise them using a’s relocaliser, which either fails, or produces an estimated pose for the frame in a’s coordinate system. If a pose is proposed, we verify it by rendering a synthetic depth raycast of a’s scene from the proposed pose and comparing it to the synthetic depth raycast of b’s scene. We accept the pose if and only if the two depth raycasts are sufficiently similar .

Conclusion
In this paper, we have shown how to enable multiple agents to collaborate interactively to reconstruct dense, volumetric models of 3D scenes. Existing collaborative mapping approaches have traditionally suffered from an inability to trust the local poses produced by their mobile agents, forcing them to perform costly global optimisations (e.g. on a server) to ensure a consistent map, and limiting their ability to perform collaborative dense mapping interactively. By leveraging recent advances to construct rigid local sub-scenes that do not need further refinement, and joining them using a state-of-the-art regression-based relocaliser, we avoid expensive global optimisations, opting only to refine the relative poses between individual agents’ maps. Our system allows multiple users to collaboratively reconstruct consistent dense models of entire buildings in under half an hour using only consumer-grade hardware, providing a low-cost, time-efficient and interactive alternative to existing whole-building reconstruction methods based on panorama scanners, and making it easier than ever before for users to capture detailed 3D scene models at scale.