python3中使用requests库出现的编码问题
最近在使用python完成爬虫任务时遇到了编码问题,查看了很多资料,现总结一些编码的知识。
1、编码解码
1、1 字符和字节
“字节”是一个8位的物理存贮单元。而“字符”则是一个文化相关的符号。
字符是人类能够识别的符号,而这些符号要保存到计算的存储中就需要用计算机能够识别的字节来表示。一个字符往往有多种表示方法,不同的表示方法会使用不同的字节数。这里所说的不同的表示方法就是指字符编码,比如字母A-Z都可以用ASCII码表示(占用一个字节),也可以用UNICODE表示(占两个字节),还可以用UTF-8表示(占用一个字节)。字符编码的作用就是将人类可识别的字符转换为机器可识别的字节码。
1、1 编码与解码概念
编码(encode):字符与二进制串的对应关系,即:字符(str)→二进制串(bytes)
解码(decode):二进制串与字符的对应关系,即:二进制串(bytes)→字符(str)
编码实际上是解码的逆向过程。编码与解码有着严格的指向性(bytes类型只有通过解码decode转为str类型,其不可能decode;str类型只能通过encode编码为bytes类型,str类型不可decode。)
概念搞清就不会出现以下两种错误。
错误1
AttributeError: 'bytes' object has no attribute 'encode'
错误2
AttributeError: 'str' object has no attribute 'decode'1、2 常见编码方式
ASCII :占1个字节,是最基本的编码,它定义了0~127对应的字符,包括最基本的英文字母、标点符号。无法表示中文
GB2312 :占2个字节,支持6700+汉字。
GBK :(GB2312的升级版),占2个字节,支持21000+汉字。
Unicode : 收录了各个国家的字符,全球通用,一个汉字占两个字节。在python 3 中字符是以Unicode的形式存储的,当然这里所说的存储是指存储在计算机内存当中,如果是存储在硬盘里,Python 3的字符是以bytes形式存储。也就是说如果要将字符写入硬盘,就必须对字符进行encode。
Utf-8 :属于Unicode的一种(为了节省空间)。优先使用1个字节(英文字母),若不满足则增加字节。汉字占3个字节。最多使用4个。
iso8859-1 通常叫做Latin-1 属于单字节编码,最多能表示的字符范围是0-255,应用于英文系列。无法表示汉字。
1、3 编码转换
编码方式转化图
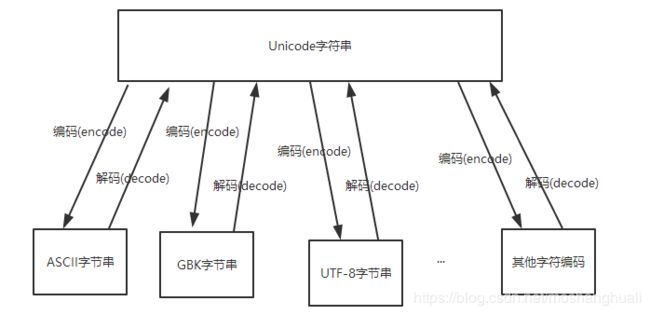
2、python3中编码
python3中默认使用的是 'utf-8' 编码
在python命令行中输入如下即可查看默认编码方式:
import sys
sys.getdefaultencoding()结果显示如下:

3、requests库

requests对象的get和post方法都会返回一个Response对象,这个对象里面存的是服务器返回的所有信息,包括响应头,响应状态码等。其中返回的网页部分会存在Response.content和Response.text两个对象中。
两者区别在于,content中间存的是字节码,而text中存的是Beautifulsoup根据猜测的编码方式将content内容解码成字符串。
直接输出content,会发现前面存在b'这样的标志,这是字节串的标志,而text是,没有前面的b,对于纯ascii码,这两个可以说一模一样,对于其他的文字,需要正确解码才能正常显示。大部分情况建议使用Response.text,因为显示的是汉字,但有时会显示乱码,这时需要用Response.content.decode('utf-8'),中文常用utf-8和GBK,GB2312等。这样可以手工选择文字编码方式.
所以简而言之,.text是现成的字符串,Response.content还要编码,但是Response.text不是所有时候显示都正常,这是就需要用Response.content进行手动编码。
3.1 编码出现错误问题
错误源头:就是reqeusts对当前返回信息的编码方式的判断出现了错误。
如果返回response对象中头部信息中有charset=utf-8 信息时,那么requests库就能准确知道返回信息的方式为utf-8编码形式。
如果返回response对象中头部信息中没有charset=? 信息时,requests会进行猜测,一般猜测为ISO-8859-1编码形式。
tips:
简单来说 r.encoding 就是requests库“认为”返回的Response信息的编码形式。(不一定正确)
而 r.text 就是将r.content根据r.encoding编码形式进行解码.
r.text = r.content.decode(r.encoding)
example 1
import requests
url = 'http://www.baidu.com'
r = requests.get(url)
print(r.status_code)
print(r.encoding) #注意此时requests认为r.content编码形式为ISO-8859-1(推断错误)
#输出状态码为 200
#输出编码形式 ISO-8859-1
#查看网页返回的headers头部信息
print(r.headers)
#输出 {'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform', 'Connection': 'Keep-Alive', 'Content-Encoding': 'gzip', 'Content-Type': 'text/html', 'Date': 'Thu, 20 Dec 2018 08:45:21 GMT', 'Last-Modified': 'Mon, 23 Jan 2017 13:28:12 GMT', 'Pragma': 'no-cache', 'Server': 'bfe/1.0.8.18', 'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/', 'Transfer-Encoding': 'chunked'}
# 没有charset内容,此时requests开始进行猜测编码为ISO-8859-1。
# 到这个地方,会有疑问,requests没有判断出来你是怎么判断出来的呢? 第一:现在utf-8编码使用最广泛,第二:你可以查看r.content,可见这一语句,实际上从这儿可以看出编码为utf-8.
# 此时用ISO-8859-1去解码的话,肯定是不可以的,因为网页实际编码为utf-8。中文肯定会出现乱码
print(r.text)
ç¾åº¦ä¸ä¸ï¼ä½ å°±ç¥é ©2017 Baidu 使ç¨ç¾åº¦åå¿
读 æè§åé¦ äº¬ICPè¯030173å· 

出现中文乱码现象。
解决办法:r.encoding = 'utf-8'。输出成功。
百度一下,你就知道