Fast unfolding of communities in large networks
链接:https://zhuanlan.zhihu.com/p/19769897
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
接着上文,我们需要进一步了解Gephi工具计算modularity的算法。在Gephi社区中,有文档 Modularity - Gephi Wiki 说明了算法[1]。
What & Why Community Detection
在直接进入文章之前,需要先了解community detection的出发点和意图。直观地说,community detection的一般目标是要探测网络中的“块”cluster或是“社团”community;这么做的目的和效果有许多,比如说机房里机器的连接方式,这里形成了网络结构,那么,哪些机器可以视作一个“块”?进一步地,什么样的连接方式才有比较高的稳定性呢?如果我们想要让这组服务瘫痪,选择什么样的目标呢?How can Modularity help in Network Analysis
我们再看一个例子,word association network。即词的联想/搭配构成的网络:
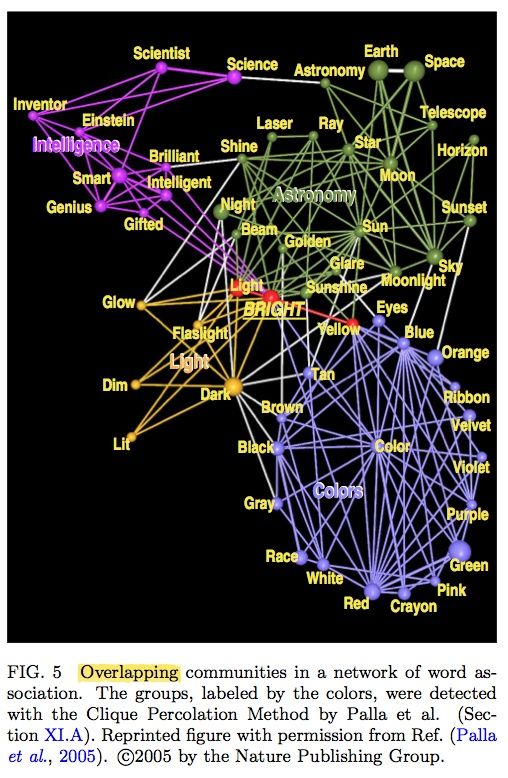
我们用不同的颜色对community进行标记,可以看到这种detection得到的结果很有意思。这个网络从词bright开始进行演化,到后面分别形成了4个组:Colors, Light, Astronomy & Intelligence。可以说以上这4个词可以较好地概括其所在community的特点;另外,community中心的词,比如color, Sun, Smart也有很好的代表性。
你或许也已发现,那些处在交叠位置的词呢?比如Bright、light等词,他们是义项比较多的词。这个图也揭示出了这一层含义。*以上给出的例子均是来自文章[2]
好,我们现在正式开始读文章!
算法思路概要
我们回忆一下,或者问自己:什么样的东西能成为团?嗯,对,同一团内的节点连接更紧密,即具有更大的density。那么,什么样的metrics可以用来描述这种density?好了,假设我们有了这个density定义了,要怎样继续下去呢?
嗯,这就是所谓method based on modularity optimization
Our method is a heuristic method that is based on modularity optimization.
optimization体现在哪?前面我们提到过density,那么,一个最完美的方案是什么样的?当然便是每个节点都找到了最好的去处,同时使得一个community间的紧密度最大!
Modularity & Density
这个问题,一方面是网络的拆分partition,另一方面是衡量这组partition的quality。我们用modularity of the partition来表示这组拆分的quality:
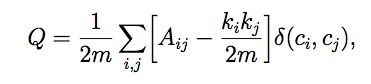 其中代表节点i,j间连接的权重,即与节点i相连的所有边的权重之和,表示节点i, j的commnity index;接下来的函数表示节点i,j是否在同一个community中(相同时取1,否则取0),最后表示整个网络的连接权重总和。
其中代表节点i,j间连接的权重,即与节点i相连的所有边的权重之和,表示节点i, j的commnity index;接下来的函数表示节点i,j是否在同一个community中(相同时取1,否则取0),最后表示整个网络的连接权重总和。
注意到,Q的取值范围是在[-1,1]之间的。当i,j没有边相连,我们便可以认为,然而其他项是可能大于0的;这个设定意味着,这样加入一个节点(但这个节点与该community中的某些点没有连接),会带来负的作用。
可以看到,这个定义,是通过link来描述的。我们下面直观地给出一个例子,来计算一下该分割的quality(也叫modularity):
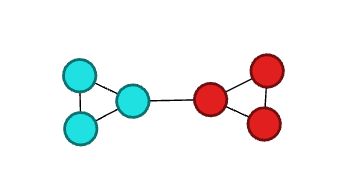 可以看到,这种分割方式是使Q最大的,即模块化程度越高越好(不超过1)。好了,我们在前面说过了模型的思路,有了一个overview以后,我们接下来把整个模型求解学习一下。
可以看到,这种分割方式是使Q最大的,即模块化程度越高越好(不超过1)。好了,我们在前面说过了模型的思路,有了一个overview以后,我们接下来把整个模型求解学习一下。
Method
算法可分为两个阶段,并不断重复迭代。例如我们有N个节点的网络:
- 为每一个节点都分配一个community index,即此时网络有N个community。此为初始状态
- 对每个节点i,我们考虑它的邻接节点j;我们让i的community变成j的,看这个动作对modularity的值有怎样的作用。如果这个变动带来的是正的,那我们就接纳这个变动,否则就保持原来的分配方式
好,第一个phase就是这样。当整个过程做到无法再提升的时候便停止。这里需要再注意一点,就是...初始点要怎么选?文章提到,初始点的选择对整个结果不会有太大影响,然而对整个计算时间有很大影响。
下面这个式子给出了“将节点i加入community C带来的modularity的变动:
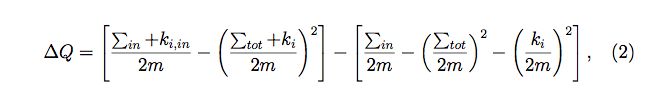 其中是该community内部的连接权重总和,是所有与该community相连的边之权重和。
其中是该community内部的连接权重总和,是所有与该community相连的边之权重和。
第二个phase在第一步结果的基础上继续进行:
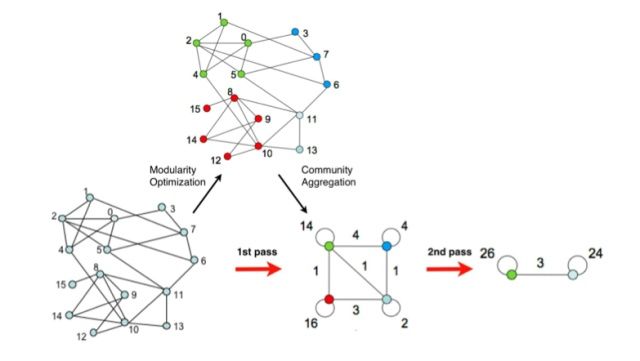 首先我们有一个原始的网络,然后在第一阶段,使用Modularity Optimization给出一个划分。随后将同一个community进行折叠,折叠后形成一个新的网络,其中:
首先我们有一个原始的网络,然后在第一阶段,使用Modularity Optimization给出一个划分。随后将同一个community进行折叠,折叠后形成一个新的网络,其中:
- community间的连接权重为连接两个community的节点之权重和
- community内部的连接形成一个自环,其权重为该community内部连接的和
这两个phase做完一轮后,称作pass;显然每次pass都会让community的数量变小,不过,这个过程其实也是在建立节点间的层次结构hierarchical structure。如下面这个图的例子,虽然左边这个网络是分成了2个组,但其中的一部分可以继续划分。
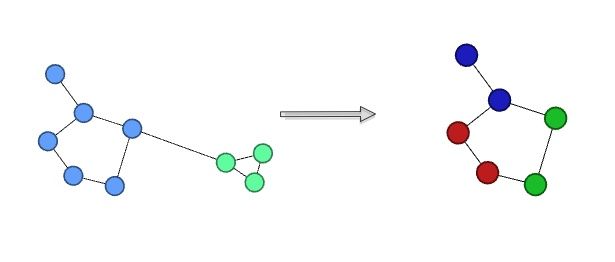 对此,作者这样说道:
对此,作者这样说道:
The algorithm is reminiscent of the self-similar nature of complex networks and naturally incorporates a notion of hierarchy, as communities of communities are built during the process
------------
那么现在我们就用站上的数据来做一些preliminary analysis
我们做这个事情,大概有两种思路:一是沿用话题树的结构做连接,二是对问题中的tags作为连接标准。这次我们先做第一种情况。
全站话题结构
 可以看到大部分节点都是整合起来的,所谓stongly-connected;颜色代表了不同的community。图太大了,我们选其中一个community来看看。
可以看到大部分节点都是整合起来的,所谓stongly-connected;颜色代表了不同的community。图太大了,我们选其中一个community来看看。
其中一个community

同一个community仍可以继续进行划分
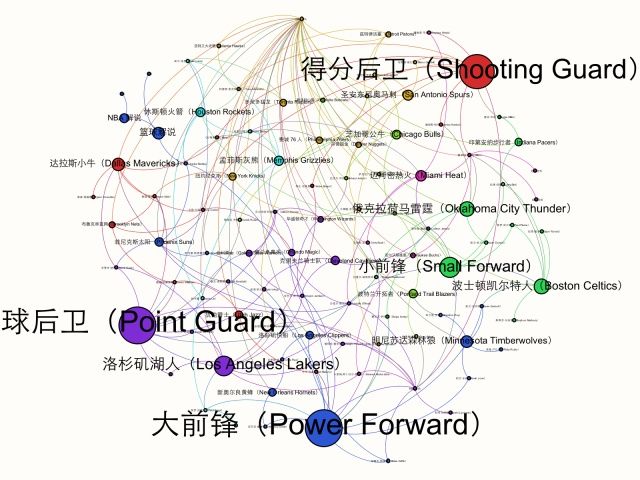 这里的节点大小是根据Betweenness Centrality调节的...挺有趣的结果。下一次,我们将用另一种方法进行实验。
这里的节点大小是根据Betweenness Centrality调节的...挺有趣的结果。下一次,我们将用另一种方法进行实验。
为什么要做这些?
这样做的目的,大概是为了找到一把适度的尺子,为后面的文本分类做一种标准。