使用scrapy爬取小说网站(一)
一、配置scrapy环境
1.安装scrapy依赖包:Twisted。
https://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted(找到与python版本对应的Twisted版本)
2.安装scrapy
使用pip install scrapy
3.安装pypiwin32
这里!如果不安装的话运行scrapy会报错。
二、采集任务分析
爬取纵横中文网小说相关数据。
①进入纵横中文网网页列表,设置循环列表,使得爬虫自动爬取每一页。
②爬取各小说名称、类别、更新时间、简介,获取小说详情页url。
③进入详情页,爬取小说字数、总推荐、总点击,获取小说目录url。
④通过url进入目录页面,爬取小说目录。
 列表页
列表页
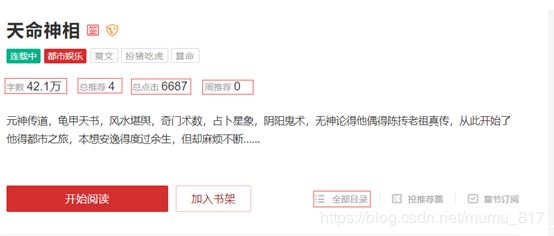 详情页
详情页
三、网页分析
在总列表页面,小说的相关信息都在.bookinfo下面,可以直接通过css构造路径进行定位爬取。详情也的url在.bookname的属性href中,可以通过::attr进行定位提取。
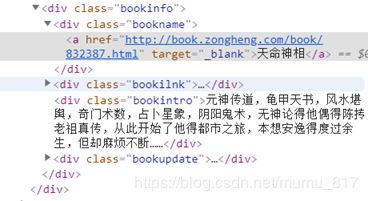
通过爬取到的详情页url进入到详情页,需要爬取的数据在.book-info中,主要在.nums的span中,因为该标签没有class名称,使用nth-child(i)子路径进行定位爬取。与数据信息不同的是,小说目录的url在.fr link-group中,这使得在刚开始构建类时需要扩大范围,将数据信息和url都包括进去。
小说目录数据所在路径较为统一,都在li标签下。
四、爬虫项目
1.创建爬虫项目
在cmd中使用scrapy指令创建爬虫项目。
scrapy startproject <项目名>创建之后进入到爬虫目录,创建spider。
scrapy genspider <目标网站> 2.修改item文件
在要item文件中定义所需要爬取的数据。其数据项有:小说名称,小说详情页连接,小说简介,小说作者,小说标签类别,小说更新状态,小说字数,小说总推荐,小说总点击,小说周推荐,全部目录链接,目录。
import scrapy
class BiqugeItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
href = scrapy.Field()
introduction = scrapy.Field()
author = scrapy.Field()
tag = scrapy.Field()
status = scrapy.Field()
new_chapter = scrapy.Field()
words = scrapy.Field()
total_recommend = scrapy.Field()
total_click = scrapy.Field()
week_recommend = scrapy.Field()
......3.编写spider
由于小说存在多页,需要进行翻页,观察页面的url,发现十分有规律,并不是通过js来进行内容加载,所以可以通过构url的方式进行页面循环。首先将要变动的页数项设置为count,构建一个动态的url。接着,写入一个for循环,当爬取到最后一个页面的时候跳出循环。
列表循环
url = 'http://book.zongheng.com/store/c0/c0/b0/u0/p'
count = 1
start_urls = [url + str(count) + '/v9/s9/t0/u0/i1/ALL.html']
if self.count < 1000:
self.count = self.count + 1
next_page = self.url + str(self.count) + '/v9/s9/t0/u0/i1/ALL.html'
yield scrapy.Request(next_page,callback=self.parse,dont_filter=True)使用css selector或者Xpath定位到具体的数据项
def parse(self, response):
for list in response.css(".bookinfo"):
item = BiqugeItem()
item['name'] = list.css('.bookname>a::text').extract_first()
item['author'] = list.css('.bookilnk>a:nth-child(1)::text').extract_first()
item['tag'] = list.css('.bookilnk>a:nth-child(2)::text').extract_first()
item['status'] = list.css('.bookilnk>span:nth-child(3)::text').extract_first().replace(' ','').replace('\r','').replace('\n','').replace('\t','')
item['introduction'] = list.css('.bookintro::text').extract_first().replace(' ','').replace('\r','').replace('\n','').replace('\t','')
item['new_chapter'] = list.css('.bookupdate > a::text').extract_first()获取到每一页的url,然后通过该url进入到详情页进行爬取。
url = list.css('.bookname>a::attr(href)').extract_first()
request = scrapy.Request(url, callback=self.parse_details)
request.meta['item'] = item
yield request4.执行爬虫
通过cmd执行爬虫
scrapy crawl (-o 文件名.json/csv...)