浅析分布式缓存弹性扩容下的一致性哈希算法
序曲:
本期不讲小程序,讲分布式哈!!!工作久了,容易在自己狭小的领域里停滞不前。为了跳出舒适圈,我时常观看一些互联网上的直播课程,以便持续更新自己的技术。当然了,这些课程都是采取了免费+付费的策略。初始都是免费给你看一个直播系列课程,如果你稍稍变得对讲师画的蓝图感兴趣,就要花费8000+以上学费以求短时间内练就神功。我发现这些讲师有一个共性,就是都喜欢用大保健来做比喻,以至于技师这个词出现的频次远高于技术,大概因为观众中女程序员比较少,讲师也无所顾忌。
正文:
我最近看的一期是利用一致性哈希算法来解决分布式缓存扩容带来的缓存雪崩的问题,我们来一起探讨下。话不多说,先上2张图镇文。
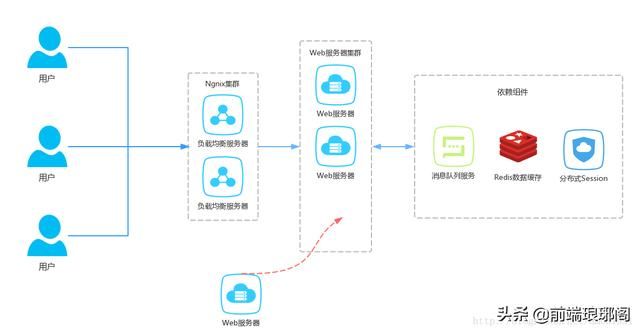
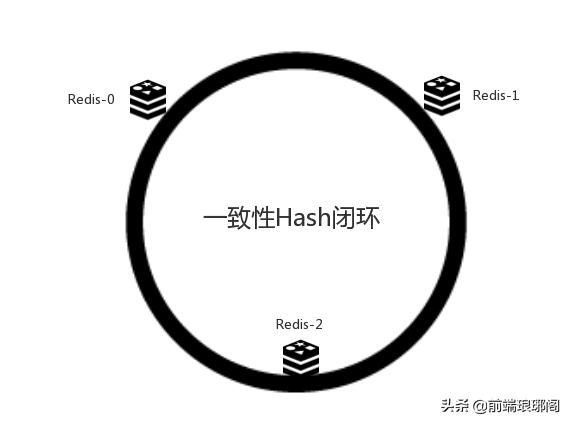
假设我们有一个网站,并发访问量是非常高的。直接读写数据库的方式肯定不能及时处理用户的大量请求,要知道3秒不返回,53%的用户可能就关掉页面离开了。为了降低数据库的访问压力,于是我们用nginx作负载均衡,引入Redis作为缓存机制(略掉应用服务器部分)。现在我们一共有三台机器可以作为Redis服务器,如上图所示。
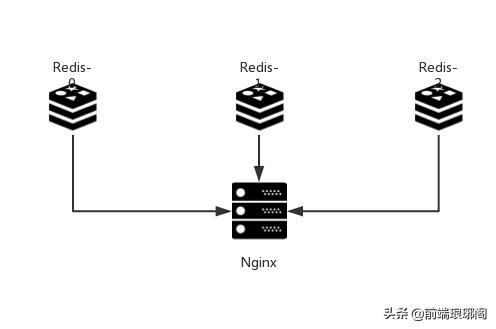
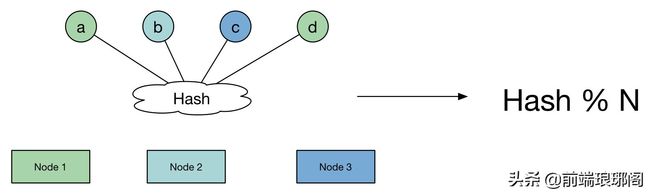
既然有3台机器,对于海量用户的每次访问,我们可以按照 h = Hash(key) % 3 算法简易计算其哈希值,那么如果我们将Redis Server分别编号为0、1、2,就可以根据上式和key计算出服务器编号h,然后去访问。大概数据的缓存就如下图这个样子。
老铁想想看,这样缓存数据可以想对均匀的分布在Redis Server上,这样真的就万事大吉了么? 对于热点数据或者近期数据,缓存在大部分时候都可以工作得很好,然而当机器需要扩容或者机器出现宕机的情况下,事情就比较棘手了,它的容错性和扩展性将会变得极差。
假如某天网站的访问剧增,我们需要增加一台机器来应对,假设机器由3台变成4台。因为取模的变化(0,1,2变成0,1,2,3),会导致原来缓存的数据的机器,与重新计算的hash值不一致。如果你仔细计算一下的话,机器由3台变成4台,大约有75%(3/4)的可能性出现缓存访问不命中的现象(例如数据缓存在Node3 ,按照新的hash值,你去访问Node4,显然是拿不到数据)。
随着机器集群规模的扩大,这个比例线性上升。当99台机器再加入1台机器时,不命中的概率是99%(99/100=====n=/n+m)。这样的结果显然是不能接受的,因为这会导致数据库访问的压力陡增,严重情况还可能导致数据库宕机(即发生缓存雪崩:缓存不可用或者大量缓存由于超时时间相同在同一时间段失效,大量请求直接访问数据库,数据库压力过大导致系统雪崩)。
----分割线------
普通Hash算法的劣势,即当node数发生变化(增加、移除)后,数据项会被重新“打散”,导致大部分数据项不能落到原来的节点上,从而导致大量数据需要迁移。
那么,一个亟待解决的问题就变成了:当node数发生变化时,如何保证尽量少引起迁移呢?即当增加或者删除节点时,对于大多数item,保证原来分配到的某个node,现在仍然应该分配到那个node,将数据迁移量的降到最低。
我们利用一致性hash算法来解决之前的缓存雪崩的问题,一致性哈希算法(Consistent Hashing)最早在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中被提出。简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),这个环的起点是0,终点是2^32 - 1,并且起点与终点连接,环的中间的整数按逆时针分布,故这个环的整数分布范围是[0, 2^32-1]。
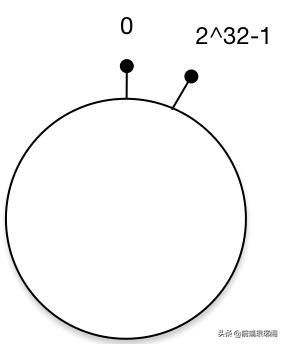
那么老铁会说了,圆你也画好了,还带俩“天线”呢,但是我就想知道数据怎么缓存?我们先把三台Redis机器给它挂到环上去。
(这里我们可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中三台服务器使用ip地址哈希后在环空间的位置如上图,当然这比较理想化,事实上肯定不是均匀分布在环上)
好了,机器挂上去了,现在我们放置待缓存的数据。
数据缓存的方式:将数据key使用相同的函数H计算出哈希值h,通根据h确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
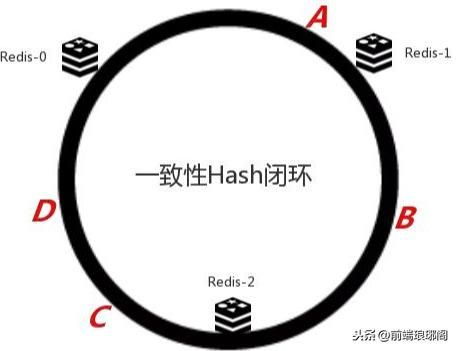
例如我们缓存服务器中有A、B、C、D四个key对应的数据对象,经过哈希计算后,在环空间上的位置如下图,
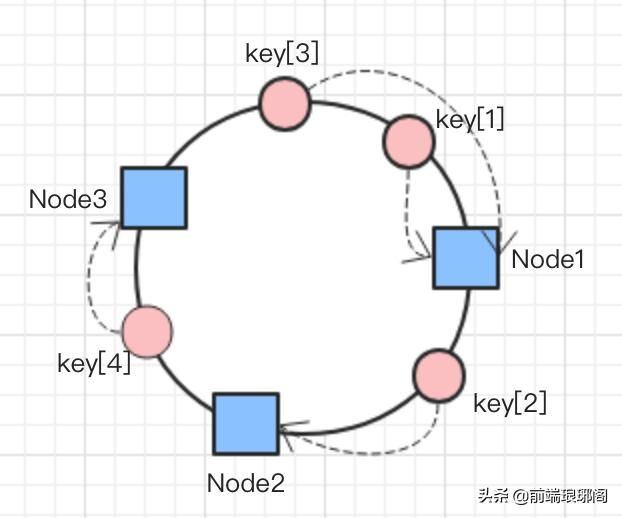
如果我们将缓存节点和待缓存的数据关系进一步抽象,将会是类似下面这张图:
那么显然的,A、B、C、D四个野孩子按照顺时针找到各自的归宿,分别是A=>Redis-1 ,B=>Redis-2 ,C、D =>Redis-0 。
好了,一切工作的是那么完美,我们现在考虑另外一种情况,如果我们在系统中增加一台服务器Redis-3 Server来扩容:
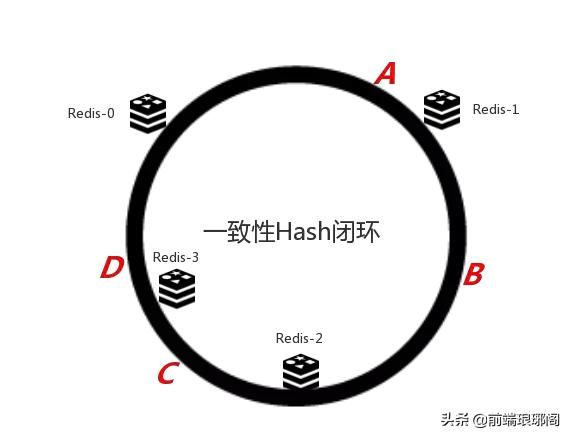
可以发现对于C这个key,重新定位至Redis-3 服务器,其他非C的key均不受影响。如果一台机器宕机了,情况也是类似的,我就不上图了。
如上文前面所述,使用简单的求模方法,当新添加机器后会导致大部分缓存失效的情况,使用一致性hash算法后这种情况则会得到大大的改善。前面提到3台机器变成4台机器后,缓存命中率只有25%(不命中率75%)。而使用一致性hash算法,理想情况下缓存命中率则有75%,而且,随着机器规模的增加,命中率会进一步提高,99台机器增加一台后,命中率达到99%,这大大减轻了增加缓存机器带来的数据库访问的压力。
我们的一致性哈希算法的大招如同降龙十八掌,我们刚才才打到第十七式,最后一招是虚拟节点。
在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如我们的系统中有两台服务器,其环分布如下:
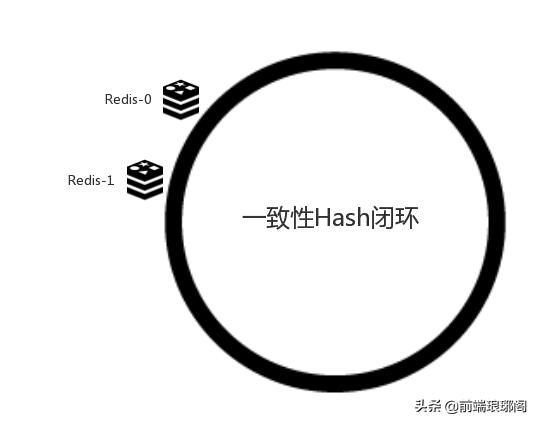
此时必然造成大量数据集中到Redis-1上,而只有极少量会定位到Redis-0上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点(虚拟节点技术实则是做了两次matching)。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,我们决定为每台服务器计算三个虚拟节点,于是可以分别计算“Redis-1 #1”、“Redis-1 #2”、“Redis-1 #3”、“Redis-0 #1”、“Redis-0 #2”、“Redis-0 #3”的哈希值,于是形成六个虚拟节点:
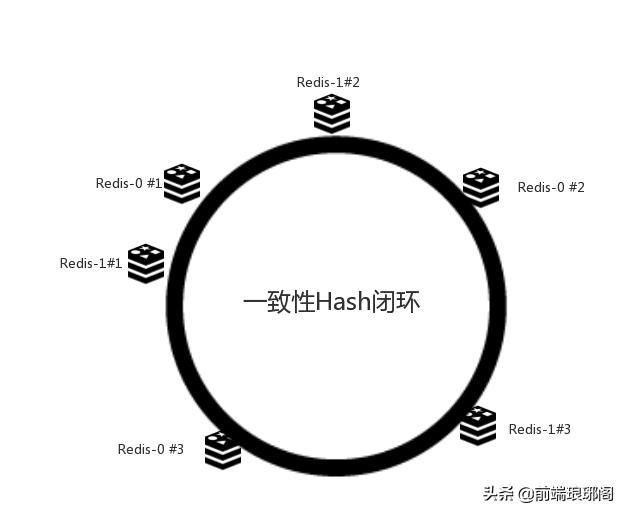
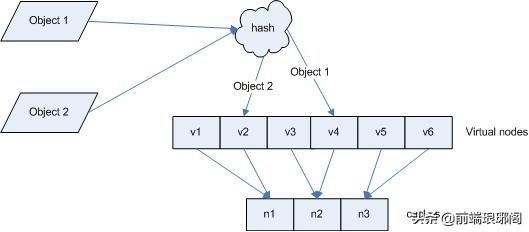
但是6个虚拟节点显然是不能满足海量数据的缓存需要的,在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
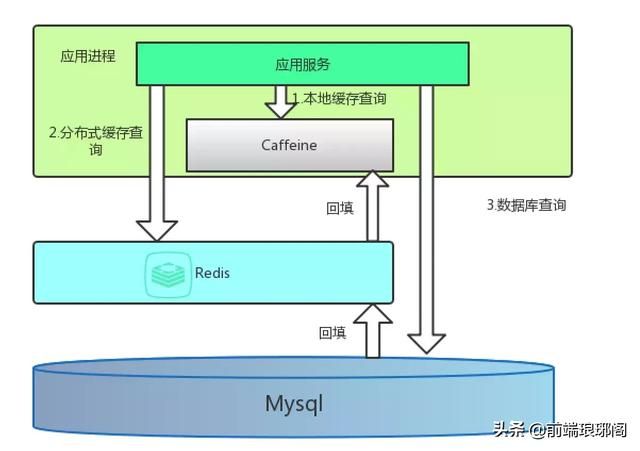
好了,打完收工。虽然是个知识搬运工,但为了加深自己的印象,我也加入了很多个人理解,希望各位看官手下留情,关注技术本身,希望对你有所裨益。能读到这的,算是真老铁了,我送一张 利用Caffeine做一级缓存,Redis作为二级缓存的美丽的图,给你加餐。
老铁别急着走,关注我微信公众号和头条号——“前端琅琊阁”,回复“hash”,可以获取延伸阅读


或者向我提问:

歌德说:“向着某一天终于要达到的那个终极目标迈步还不够,还要把每一步骤看成目标,使它作为步骤而起作用。” 每天完成一小步,我们一起进步。直到有一天,会当凌绝顶,一览众山小。