回归方法(三)logistic regression(数据集Titanic)
1logistic 分布:设X是连续随机变量,X服从logistic分布是指X具有以下分布函数和密度函数:![]()
![]()
分布函数F(x)属于逻辑斯蒂函数,图形是一条S曲线,该曲线以点( ,1/2)为中心对称,曲线在中心点附近增长速度较快,在两端增长速度较慢,形状参数
,1/2)为中心对称,曲线在中心点附近增长速度较快,在两端增长速度较慢,形状参数 的值越小,曲线在中心附近增长越快。
的值越小,曲线在中心附近增长越快。
二项逻辑斯蒂回归模型是一种分类模型,由条件概率分布P(Y\X)表示,形式为参数化的逻辑斯蒂分布,这里随机变量x取值为实数,随机变量y的取值为1或0.通过监督学习的方法来估计模型参数。
![]()
![]() 这里,w和b都是参数,分别称为权值向量和偏置。 几率(odds)是指该事件发生的概率与改时间不发生的概率比值。事件的对数几率(log odds)的函数是logit(p)=log(p/1-p) 对于逻辑斯蒂回归而言
这里,w和b都是参数,分别称为权值向量和偏置。 几率(odds)是指该事件发生的概率与改时间不发生的概率比值。事件的对数几率(log odds)的函数是logit(p)=log(p/1-p) 对于逻辑斯蒂回归而言![]() 也就是说,在这个回归模型中输出Y=1的对数几率是输入x的线性函数。或者说,输出Y=1的对数几率是由输入x的线性函数表示的模型,即逻辑斯蒂回归模型。
也就是说,在这个回归模型中输出Y=1的对数几率是输入x的线性函数。或者说,输出Y=1的对数几率是由输入x的线性函数表示的模型,即逻辑斯蒂回归模型。
换一个角度而言,对输入x进行分类线性函数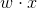 ,值域为实数域。通过逻辑斯蒂回归定义,可以将线性函数转换为概率。
,值域为实数域。通过逻辑斯蒂回归定义,可以将线性函数转换为概率。![]() 这是线性函数的值越接近正无穷,概率值就越接近1.线性函数的值越接近负无穷,概率值就越接近0。这就是逻辑斯蒂回归模型。
这是线性函数的值越接近正无穷,概率值就越接近1.线性函数的值越接近负无穷,概率值就越接近0。这就是逻辑斯蒂回归模型。
(模型参数估计 多项逻辑斯蒂回归 待补充)
2与线性回归的对比:
在线性回归中,因变量的取值范围是整个实轴,这里仅取两个值。
误差项不是正态分布
因变量服从伯努利分布而不是正态分布
3应用
人力资源分析(应聘结果) 足彩预测 银行风控
4用R进行案例分析 实现的函数为glm(),需要同时设置参数family="binomial"
用逻辑回归模型来分析kaggle中Titanic数据集合,通过已知变量来预测乘客是否生还。
training.data.raw <- read.csv('https://raw.githubusercontent.com/agconti/kaggle-titanic/master/data/train.csv')#读取数据集
head(training.data.raw,1)#查看数据项目和类型
> head(training.data.raw,1)
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
1 1 0 3 Braund, Mr. Owen Harris male 22 1 0 A/5 21171 7.25 S
可以看到数据包括12项信息,这里我们想通过 pclass(社会地位),sex(性别),age(年龄),sibsp(家庭关系1,是否夫妻),parch(家庭关系2,父母,孩子,和保姆一起的孩子),fare(票价),embarked(出发港口)这7个变量预测乘客的是否生还。
data <- subset(training.data.raw,select=c(2,3,5,6,7,8,10,12))#用subset函数选取所需的列
data$Age[is.na(data$Age)] <- mean(data$Age,na.rm=T)
data <- data[!is.na(data$Embarked),]#处理NA
rownames(data) <- NULL
train <- data[1:800,]#划分训练集
test <- data[801:889,]#测试集
model <- glm(Survived ~.,family=binomial(link='logit'),data=train)#模型拟合
summary(model)#显示拟合细节
Call:
glm(formula = Survived ~ ., family = binomial(link = "logit"),
data = train)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.6059 -0.5933 -0.4250 0.6215 2.4148
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 15.947761 535.411378 0.030 0.9762
Pclass -1.087576 0.151088 -7.198 6.10e-13 ***
Sexmale -2.754348 0.212018 -12.991 < 2e-16 ***
Age -0.037244 0.008192 -4.547 5.45e-06 ***
SibSp -0.293478 0.114660 -2.560 0.0105 *
Parch -0.116828 0.128113 -0.912 0.3618
Fare 0.001515 0.002352 0.644 0.5196
EmbarkedC -10.810682 535.411254 -0.020 0.9839
EmbarkedQ -10.812679 535.411320 -0.020 0.9839
EmbarkedS -11.126837 535.411235 -0.021 0.9834
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1066.33 on 799 degrees of freedom
Residual deviance: 708.93 on 790 degrees of freedom
AIC: 728.93
Number of Fisher Scoring iterations: 12预测模型的精度
fitted.results <- predict(model,newdata=subset(test,select=c(2,3,4,5,6,7,8),type='response'))
fitted.results <- ifelse(fitted.results > 0.5,1,0)
misClasificError <- mean(fitted.results != test$Survived)
round(1-misClasificError,3)
[1] 0.809输出结果为0.809 (即预测精度)
预测评估
install.packages("ROCR")
library(ROCR)
p <- predict(model, newdata=subset(test,select=c(2,3,4,5,6,7,8)), type="response")
pr <- prediction(p, test$Survived)
auc <- performance(pr, measure = "auc")
auc <- [email protected][[1]]
auc
[1] 0.866342画图
prf <- performance(pr, measure = "tpr", x.measure = "fpr")
plot(prf) 
参考资料:李航《统计学》公众号:数萃大数据
推荐阅读:https://www.cnblogs.com/nxld/p/6170690.html