新手快看!python爬取数据+数据分析,有这一篇就够啦
推荐用Jupyter
爬取二手车之家的部分数据
# 爬取二手车网站的数据
#Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库
from bs4 import BeautifulSoup
# 用于网络请求
import urllib.request
#操作csv文件
import csv
#指定编码
import codecs
#添加newline可以避免一行之后的空格,这样需要在python3环境下运行
csvfile= open(r'D:\360MoveData\Users\lenovo\Desktop\爬取演示.csv', 'w' , newline='',encoding='gb18030')
#指定逗号作为分隔符,并且指定quote方式为引用。这意味着读的时候都认为内容是被默认引用符(")包围的
writer=csv.writer(csvfile,delimiter=',',quoting = csv.QUOTE_ALL)
keys=['车型','信息','价格']
writer.writerow(keys)
for page in range(2,100):
# 目标网址
# url = 'http://www.che168.com/china/a0_0msdgscncgpi1lto8cspexx0/#pvareaid=106289'
url = 'http://www.che168.com/china/a0_0msdgscncgpi1lto8csp'+str(page)+'exx0/?pvareaid=102179#currengpostion'
# 发送请求
# urllib.request 是一个用于获取 URL (统一资源定位地址)的 Python 模块
f=urllib.request.urlopen(url)
resp=f.read()
# print(resp) # 203
# 网页源代码 (文本显示)
# print(resp.text)
# 用BeautifulSoup解析数据 python3 必须传入参数二'html.parser' 得到一个对象,接下来获取对象的相关属性
html = BeautifulSoup(resp, 'html.parser')
#解析返回的数据
lis=html.findAll(class_='cards-li list-photo-li')
for li in lis:
carType=li.h4.text
carInfo=li.p.text
carPrice=li.s.text
print(carType)
print(carInfo)
print(carPrice)
oneCar=[carType,carInfo,carPrice]
writer.writerow(oneCar)
csvfile.close()
爬取出来的csv文件用excel打开就是这样的

数据分析
原始数据
数据清洗:填充或删除缺失数据,删除重复值,数据类型转换,字符串处理,删掉异常数据,数据替换
数据分析
数据结论
进行数据分析
准备工作
#as 别名
import numpy as np
#处理csv的文件
import pandas as pd
#数据分析,画图的库
import matplotlib.pyplot as plt
#可视化工具
import seaborn as sns
#解决中文问题 matplotlib.pypolt不支持中文
plt.rcParams['font.sans-serif']=['SimHei']
#解决负号显示
plt.rcParams['axes.unicode_minus']=False
#%matplotlb inline #plt.show 直接显示生产的图表 在这个文档写的代码就不用加了
import pandas as pd
#原始数据
#加r和不加''r是有区别的 \t 相当于按了tab键
#'r'是防止字符转义的 如果路径中出现'\t'的话 不加r的话\t就会被转义 而加了'r'之后'\t'就能保留原有的样子
#另外;字符串赋值的时候 前面加'r'可以防止字符串在使用的时候不被转义 原理是在转义字符前加'\'
#UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb3 in position 0: invalid start byte
pd.set_option('display.max_rows',None)
data=pd.read_csv(r'D:\360MoveData\Users\lenovo\Desktop\课堂演示.csv',encoding='gb18030')
data
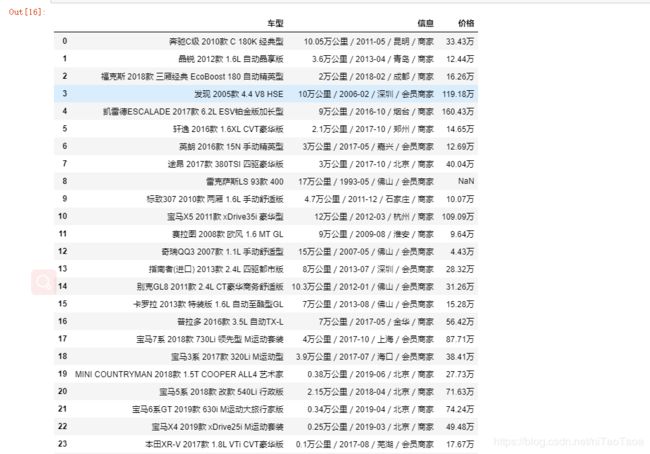
这就是刚刚爬取的数据,舒服,一下出来数据,笔者卡了好久
#数据清洗 删除价格为NaN类型的数据
data.drop([8,48,54],inplace=True) #参数1 删除的行号 参数2 表示在原始数据上删除
data #再打印一下数据
#删除原价为 NaN 缺失值的数据
data.dropna(subset=['价格'],inplace=True)
#删除价格为 已涨价xx元 已降价xx元的数据
data=data[ ~data['价格'].str.contains('已')] #删除某列包含特殊字符的行
data

值为NaN的值就删了,大数据处理,忽略小细节
data.head(10) #默认5行,这里显示10行

#缺失值 检测当前的数据有没有缺失值
data.isnull()
print('当前缺失值为')
(data.isnull()).sum()

#重复值的检测
data.duplicated()

#重复值数目
data.duplicated().sum()

后面的参数代表,在本对象上删除,不是形式上的删除
#删除重复值
data.drop_duplicates(inplace=True)
#查看剩余所有数据的个数
len(data)

#查看列名为 价格 的列包含 万 的数据的个数
data.价格.str.contains('万').sum()

# 字符串处理
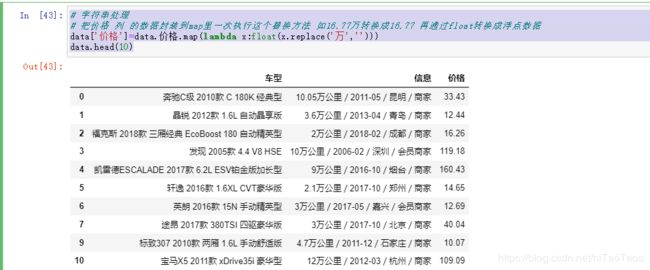
# 把价格 列 的数据封装到map里一次执行这个替换方法 如16.77万转换成16.77 再通过float转换成浮点数据
data['价格']=data.价格.map(lambda x:float(x.replace('万','')))
data.head(10)
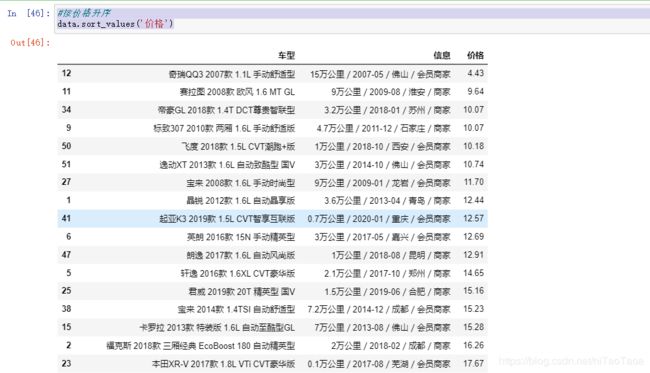
#按价格升序
data.sort_values('价格')
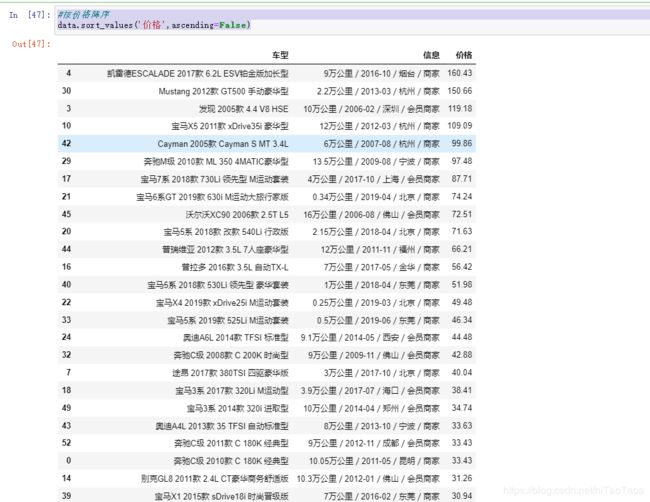
#按价格降序
data.sort_values('价格',ascending=False)
数据分析

价格的分析
#定义分类标准 分析各区间的数据
bins=[0,30,60,90,120,150,180]
pd.cut(data.价格,bins).value_counts()

#画成直方图
pd.cut(data.价格,bins).value_counts().plot.bar()
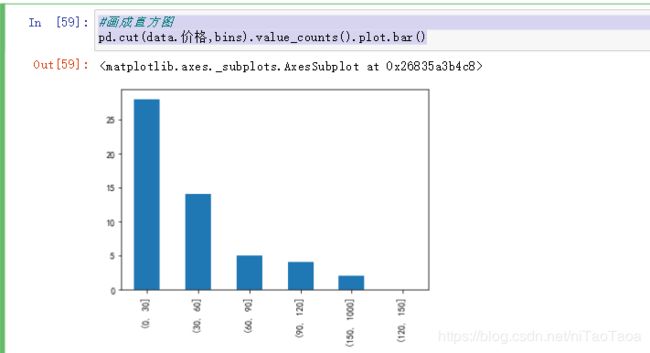
#画成直方图 rot 把x轴的数据进行旋转 ,如旋转水平角度为0度
pd.cut(data.价格,bins).value_counts().plot.bar(rot=0)

#直方图,x轴水平,并加上标题
pd.cut(data.价格,bins).value_counts().plot.bar(rot=0,title='价格分析')

品牌的分析
data['车型']=data.车型.map(lambda x:x.split(' ')[0])
data
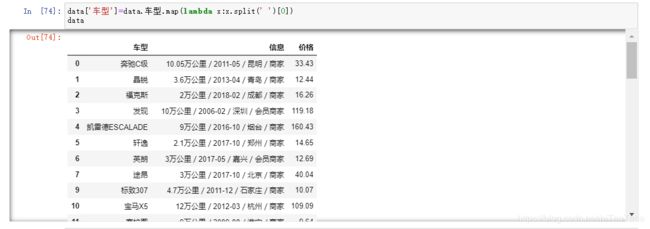
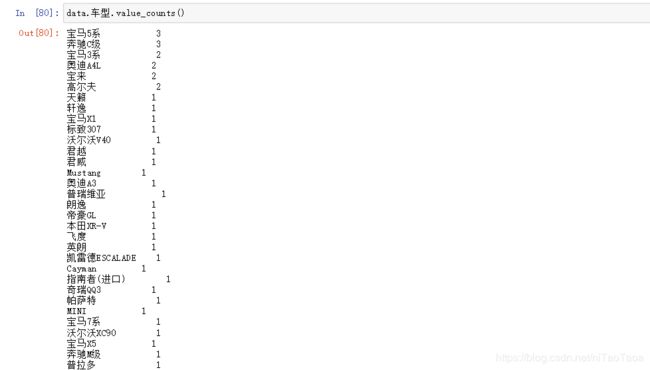
data.车型.value_counts()
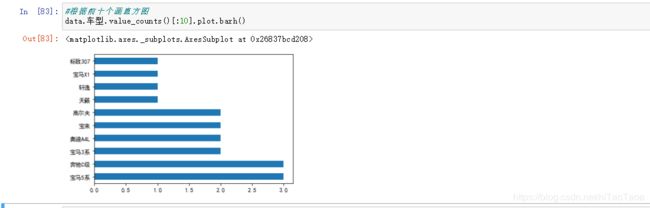
#根据前十个画直方图
data.车型.value_counts()[:10].plot.barh()
#分组 对所以车辆按地点分组 显示该组的平均价格
data.groupby(['车型'])['价格'].mean()

# 类型转换
#data['列名']=data.列名.map(lambda x:目标数据类型(x))
#重新排列索引,并删除原索引
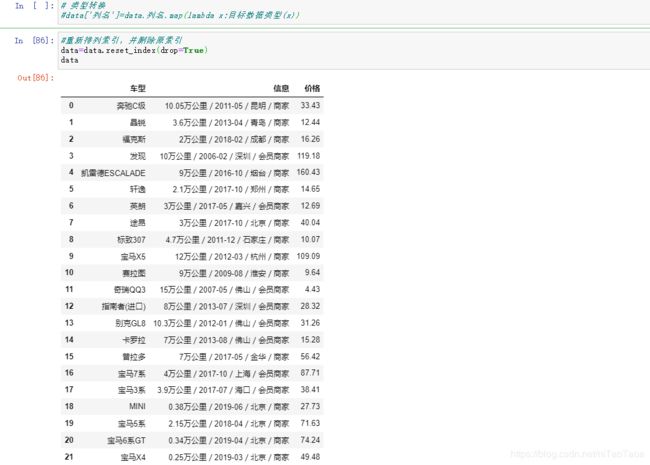
data=data.reset_index(drop=True)
data
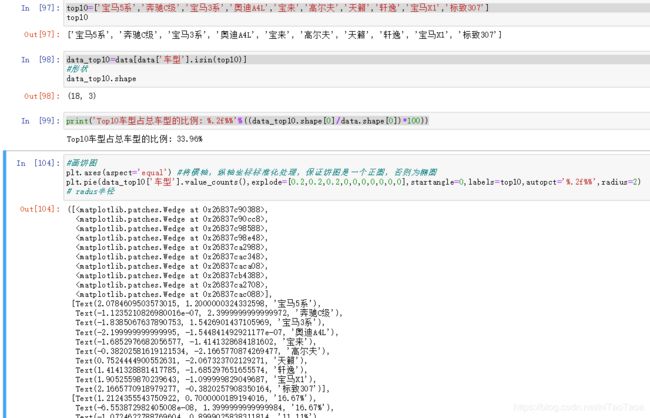
top10=['宝马5系','奔驰C级','宝马3系','奥迪A4L','宝来','高尔夫','天籁','轩逸','宝马X1','标致307']
top10

饼图
top10=['宝马5系','奔驰C级','宝马3系','奥迪A4L','宝来','高尔夫','天籁','轩逸','宝马X1','标致307']
data_top10=data[data['车型'].isin(top10)]
print('Top10车型占总车型的比例: %.2f%%'%((data_top10.shape[0]/data.shape[0])*100))
#画饼图
plt.axes(aspect='equal') #将横轴,纵轴坐标标准化处理,保证饼图是一个正圆,否则为椭圆
plt.pie(data_top10['车型'].value_counts(),explode=[0.2,0.2,0.2,0,0,0,0,0,0,0],startangle=0,labels=top10,autopct='%.2f%%',radius=2)
# radus半径
 这里。很容易出错,因为数据是动态获取,前十的车型可能会变,如何把上面的前十数据获取到一个动态的数组里,笔者也不知道。
这里。很容易出错,因为数据是动态获取,前十的车型可能会变,如何把上面的前十数据获取到一个动态的数组里,笔者也不知道。
尽力了。
别问我参数,我也不知道,,,也许有人会问
这些数据怎么不分开,我也不会,,我知道用正则,分割其他还好,但一遇到 / 怎么分都不行,去班群里问也没人回我,5555
看了的感觉有用的小伙伴点个赞哈,小胖谢过。