Web技术的发展 网络发展简介(三)
Web技术的发展 网络发展简介(三)
在上一篇文章中,对TCP/IP通信协议进行了简单的介绍
通信协议是通信的理论基石,计算机、操作系统以及各种网络设备对通信的支持是计算机网络通信的物质基础
而web服务则是运行于应用层,借助于应用层的协议,建立了客户端与服务器,对等层之间的联系,底层的硬件以及软件为其提供服务。
本文对web发展架构进行简单介绍,并且对web开发技术进行简单介绍,不是要介绍细节,而是要展示一个宏观的概念。
WEB架构起源
80年代中期ARPANET才逐渐开始进入民用
20世纪90年代之前,因特网的主要使用者还是研究人员、学者和大学生
他们登录远程主机,在本地主机和远程主机之间传输文件,收发新闻,收发电子邮件等,但是因特网基本上不为学术界和研究界之外所知。
此时,计算机网络通信的底层技术已经相对比较成熟,一个叫做Tim的人,开始尝试建立互联世界的文档
其实他并不是第一个有这个想法的人,但是在此之前,鉴于计算机科学技术的发展限制,都并没有成功
1989年CERN(欧洲粒子物理研究所)中由Tim Berners-Lee领导的小组
提交了一个针对Internet的新协议和一个使用该协议的文档系统
该小组将这个新系统命名为Word Wide Web,它的目的在于使全球的科学家能够利用Internet交流自己的工作文档。
这个新系统被设计为允许Internet上任意一个用户都可以从许多文档服务计算机的数据库中搜索和获取文档。
1990年末,这个新系统的基本框架已经在CERN中的一台计算机中开发出来并实现了
1991年该系统移植到了其他计算机平台,并正式发布。
1989年,Tim提出Web计划,1991年正式发布,速度真的好快。
HTML, HTTP, URI,浏览器,web服务器,就此发明问世
Word Wide Web又被称为“Web”、“WWW”、“W3”,中文名字为“万维网”,"环球网"等,常简称为Web
万维网并不等同互联网,万维网只是互联网所能提供的服务其中之一,是靠着互联网运行的一项服务。
所有连接到网络上的计算机,通过运行的web服务器程序,提供给内容的所有内容、服务,才是我们说的万维网
分为Web客户端和Web服务器程序, WWW可以让Web客户端(常用浏览器)访问浏览Web服务器上的页面。
计算机网络的互连,让全世界各地的计算机能够进行通信
而web则让全世界各地的计算机能够进行超文本文档的共享,完成了计算机网络内容的互连
web的发明,让互联网开始爆炸式增长
Web的起源某种程度上可以认为是“一蹴而就”的(我加引号了),不过前提是计算机网络已经发展到了一定阶段,具备了先决条件,而且已经累积了很多计算机科学方面的理论
Tim搭建了web的雏形,设计了web的架构,是BS结构的始祖。
web的基本核心就是内容的共享
比如,你问你的语文老师,XXX的作者是谁。
- 你就是请求发起者,语文老师就是请求应答者;
- 问题就是资源的标识符;
- 而你通过语言表达出来,普通话就是协议;
- 而作者到底是谁,则是被请求的内容;
- 而内容也有表示形式,比如说出来?写在纸上交给你?则是超文本格式;

BS形式共享超文本文档的架构方案,定义了浏览器客户端和服务器程序是两个通讯主体,双方通过HTTP协议进行对话,通过URI进行资源定位,消息通过HMTL格式化。
web核心组成
- URI 解决了文档的命名和寻址识别问题
- HTTP解决了浏览器与服务器应用层之间的交流问题
- HTML 定义了超文本文档的表示
- 浏览器用于发起请求,并且解析文档
- 服务器用于保存文档
URI
统一资源标识符(Uniform Resource Identifier,或URI)
URI采用一种特定语法标识一个资源的字符串,所标识的资源可能是服务器上的一个文件,也可能是一个邮件地址、新闻消息、图书、人名、互联网上的主机或者任何其它内容。
重点在于唯一标识
URI有两种形式,URL和URN

URL是Uniform Resource Locator的缩写,译为“统一资源定位符”
URL的格式由下列三部分组成:
- 协议(或称为服务方式);
- 存有该资源的主机名称(域名)或者IP地址(有时也包括端口号);
- 主机资源的具体地址,如目录和文件名等;
URN是统一资源名称 (Uniform Resource Name, URN)
URN它命名资源但不指定如何定位资源
URI描述了这么一个东西:可以用来唯一标识一个资源,URL和URN是他的两种具体形式
所以一个URI可能是一个URL,也可能是一个URN,或者二者兼具。
但是任何一个URL或者URN他们肯定都是URI
比如,“阿里巴巴马云”当你听到这个名字的时候,你不知道他是谁吗?这就是唯一标识一个资源URN
但是马云在哪里?电话号码多少?你是不知道的,虽然“马云”两个字可以唯一标识他本人,但是你联系不上他
如果你有了他家的地址呢?XXX小区XXX号,你就可以定位马云的位置了,这就是URL
不管是“阿里巴巴马云”还是马云家的地址XXX小区XXX号,他们都是URI
HTTP协议
设计HTTP最初的目的是为了提供一种发布和接收HTML页面的方法
最早版本是1991年发布的0.9版。该版本极其简单,只有一个命令GET。
GET /index.html
表示,TCP 连接(connection)建立后,客户端向服务器请求(request)网页index.html。
协议规定,服务器只能回应HTML格式的字符串,不能回应别的格式。
HTTP协议就是浏览器与web服务器两个应用之间通信的“协议”“语言”
计算机不能像人类一样沟通,他只是0,1的世界,想要交流就必须制定通信的格式,而这个HTTP协议就是浏览器与Web服务器的沟通方式
这就是它的根本,如同你对别人竖大拇指表示称赞,服务器看到GET方法就会返回数据,这就是浏览器与服务器沟通交流的方式。
换句话说,人类用语言和文字进行沟通,CS世界中的各种协议,都是计算机的沟通方式。
HTML
HTML超文本标记语言,标准通用标记语言下的一个应用
标准通用标记语言(简称“通用标言”),是一种定义电子文档结构和描述其内容的国际标准语言;
早在万维网发明之前“通用标言”就已存在,HTML也是由他发展演变而来,
可以简单理解为一种借助于标记符格式化电子文档的语言,平时的书写中你可以换行,可以设置标题、段落,但是在电子文档中如何表达?
计算机不能像人类一样用眼分辨,用脑思考,想要说明这是一个标题,你必须显式的告诉他
标记语言就是一种非常合适的解决方案
比如HTML中的"
这是个标题
",h1是标签,标签中的内容就是标题,我们使用h1来标志这是一个一级标题,当计算机程序解读到时,就可以意识到这是个标题
超级文本标记语言是万维网(Web)编程的基础,也就是说万维网是建立在超文本基础之上的。
超级文本标记语言之所以称为超文本标记语言,是因为文本中包含了所谓“超级链接”点
之所以没有直接使用通用标记语言,是因为他过于复杂,HTML是简化的变种。
需要注意,电子文档的出现远比web起源要早
电子文档的最初动机就是“将书稿、文件塞到计算机中”,一份文件,有内容也有格式(文字字体,大小,间距等)
电子化的目的是通过计算机呈现,所以电子化不仅仅需要记录文件的内容,还需要记录内容的格式(样式),你讲两行字之间空白多一点,行间距就大一点,在计算机中如何呈现?
HTML就是标记语言的一种应用,他也只是一种电子文档。
浏览器
浏览器就是一个应用软件,他可以通过HTTP协议与服务器进行交互
根本功能也很简单,发送HTTP请求,解析显式获得的响应数据
1991年,世界上第一个浏览器World Wide Web(后改名为Nexus)由Tim Berners-Lee创建于欧洲核子物理实验室
同时他还写了第一个网页服务器httpd
这个浏览器并不支持图片的显示
1993年,伊利诺伊大学厄巴纳-香槟分校的NCSA组织发表NCSA Mosaic,简称Mosaic
是互联网历史上第一个获普遍使用和能够显示图片的网页浏览器
并于1997年1月7日正式终止开发和支持
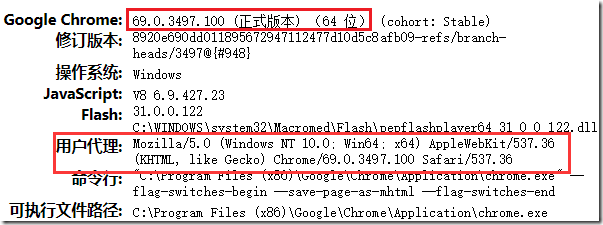
Mosaic发布后,到底怎么分辨你的浏览器是否支持显示图片呢?UserAgent就是在这样的场景下诞生了
Mosaic将自己标志为NCSA_Mosaic/2.0(windows 3.1)
这也是我们使用浏览器发送请求的时候请求头有一个字段为UserAgent的最开始原因
著名的浏览器如下,国内的浏览器厂商都是用国外的浏览器内核
浏览器发展历史:
http://www.cnw.com.cn/zhuanti/2009-ie/
| 1991 | www(nexus) |
| 1993 | Mosaic |
| 1994 | Netscape |
| 1996 | IE |
| 1996 | Opera |
| 2003 | safari |
| 2004 | firefox |
| 2008 | chrome |
有一篇很有意思的文章, 可以一看
http://www.cnblogs.com/ifantastic/p/3481231.html
https://webaim.org/blog/user-agent-string-history/
chrome可以通过在浏览器地址栏输入“about:version”查看UA信息
还可以通过网站查看:http://www.useragentstring.com/
服务器
Web服务器是可以向发出请求的浏览器提供文档的程序,也是一种软件。
遵循HTTP协议,接受浏览器客户端发起的请求,并按照HTTP协议的规定响应的一种软件。
现在也把提供web服务的专用计算机叫做web服务器,提供web服务的程序叫做web容器。
https://en.wikipedia.org/wiki/Web_server中有关于web server的介绍
还可以通过:https://w3techs.com/technologies/overview/web_server/all 查看目前各大web Server的使用率

现代的web 容器都是强大而复杂的,但是根本是相同的,那就是接受HTTP请求,并且按照HTTP协议进行响应。
WEB周边组件-域名与DNS
域名(Domain Name),简称域名、网域
是由一串用点分隔的名字组成的,表示Internet上某一台计算机或计算机组的名称
用于在数据传输时标识计算机的位置
我们知道计算机在网络中的通信需要借助于ip地址,但是ip地址即使是点分十进制,依然难以记忆
域名就是为了简化记忆,更加便于使用
简言之,域名等于一个ip的名字
如果每个ip相当于电话号码,那么域名就是姓名

姓名和号码之间必然是要有映射关系
早期,网络上计算机个数很少
将对应关系保存在一个共享的静态文件hosts中即可,再由hosts文件来实现网络中域名的管理
也就是说,大家通过共享这个文件来完成ip与域名的映射,这个hosts文件就是域名IP的解析器
但是随着网络上计算机的增多,显然不能将所有的域名与ip地址的对应关系都记录在文件中
所以出现了DNS(Domain Name System),为了解决互联网上域名与IP地址的映射解析
百度百科:“域名解析服务,最早于1983年由保罗·莫卡派乔斯发明;
原始的技术规范在882号因特网标准草案(RFC 882)中发布。
1987年发布的第1034和1035号草案修正了DNS技术规范,并废除了之前的第882和883号草案。
在此之后对因特网标准草案的修改基本上没有涉及到DNS技术规范部分的改动。”
现在的操作系统中仍旧保留hosts这一文件,只不过不再是全网的了,已经有专门的DNS了

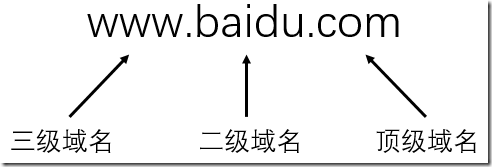
域名采用树状的层级结构,任何一个连接在互联网上的主机和路由器,都有一个唯一的层次结构名字,也就是域名
这里的域(domain)是名字空间中的一个可被管理的划分。域还可以划分为子域,而子域还可以继续被划分为子域
这就形成了子域,二级域,三级域...
每个域名都由一个标号构成,标号之间使用小数点分割,如下图所示
可以认为,将域名空间按照顶级域名进行划分,形成了域名的基本格局,就像“四大洋,七大洲”
也可以理解成国家行政区域的划分。
中国
江苏.中国
南京.江苏.中国
所以要深入理解域的概念,顶级域的并集就是全部的域空间
比如说,全世界共有XXX个国家和地区,那么,就是只有那么多个国家和地区
任何一个域名,都是一个顶级域名的子域,顶级域的划分,完成了域名空间的顶层管理
DNS规定,每一个标号不允许超过63个字符,也不区分大小写,标号中除了使用连字符外不能使用其他的标点符号
级别最低的标号位于域名最左边,级别最高的顶级域名位于域名最右边
既不规定每一个域名需要有多少个下级域名
也不固定每一级的域名代表什么意思
各级域名由他的上级域名管理机构进行管理
最高的顶级域名由ICANN进行管理
叶子节点指向物理机器
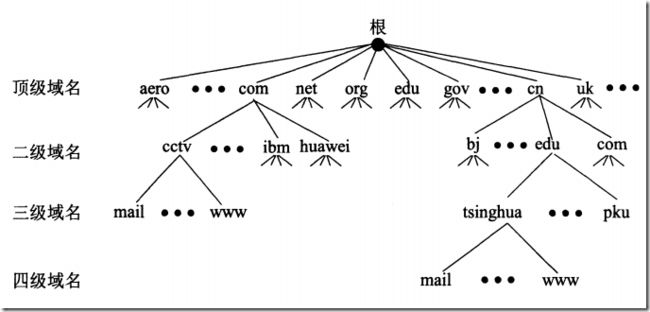
DNS解析过程
上面介绍的域名体系是逻辑上的,DNS服务器的运行按照“区”来进行划分
域名的体系结构按照“域”来划分,服务器实际的查询解析,则是按照“区”,
简言之,逻辑上就相当于按照行政区域划分,实际管辖上则是分片区管理
区可能小于或者等于一个域,但是肯定不会大于域
一个区中所有的节点必须是联通的,每一个区设置相应的权限域名服务器(authoritative name server),用来保存该区中所有的域名与IP地址的映射
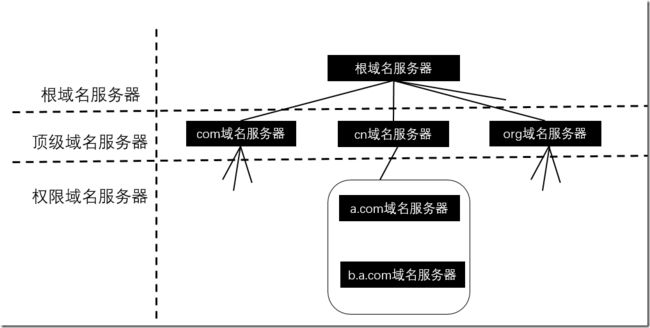
域名服务器分类
根域名服务器
最高层次的域名服务器,最重要的域名服务器,所有的根域名服务器都知道所有的顶级域名服务器的域名和IP地址
如果所有的根域名服务器挂掉,整个互联网将会瘫痪
顶级域名服务器
管理在该顶级域名服务器注册的所有的二级域名,收到请求后,给出响应(要么直接返回结果,要么给出下一步应该查询的域名服务器的IP地址)
权限域名服务器
负责一个区的域名服务器
如果一个权限域名服务器不能给出最后的查询结果,会通知发出请求的DNS客户,下一步应该找哪个权限域名服务器
本地域名服务器
本地域名服务器不是域名管理层次中的一环,主要作用是为了高效节能
每个互联网ISP ,每个大学、机构都可以有一个本地域名服务器
windows中关于DNS的设置就是本地域名服务器,也叫做默认域名服务器
查询方式
查询方式共有两种:迭代查询,递归查询
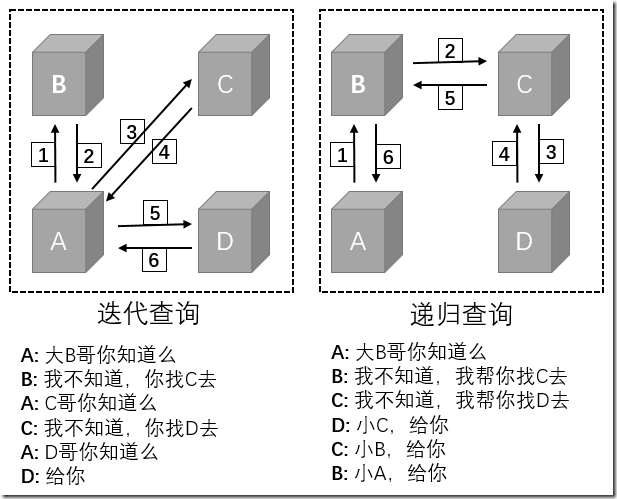
迭代查询-->我不知道你找XXX去,一直踢皮球
递归查询-->我去帮你查,一直很仗义
主机向本地域名服务器的查询一般都是采用递归查询
本地域名服务器向根域名服务器的查询通常是采用迭代查询
简单理解就是域名逻辑上是树形的层级结构,按照域进行划分
DNS域名服务器按照区进行划分,每个区小于等于一个域,对域进行分片管理
DNS的域名服务器就是与域名层次等级结构相对应的一个服务器结构体系
WEB技术发展
最初,所有Web页面都是静态的
用户请求一个资源,服务再返回这个资源,在浏览器中主要展现的是静态的文本或图像信息。
GIF图片则第一次为HTML页面引入了动态元素
这些网站的Web页面只是电子形式的文本,内容生成之后就是固定不变的,然后发布到多处
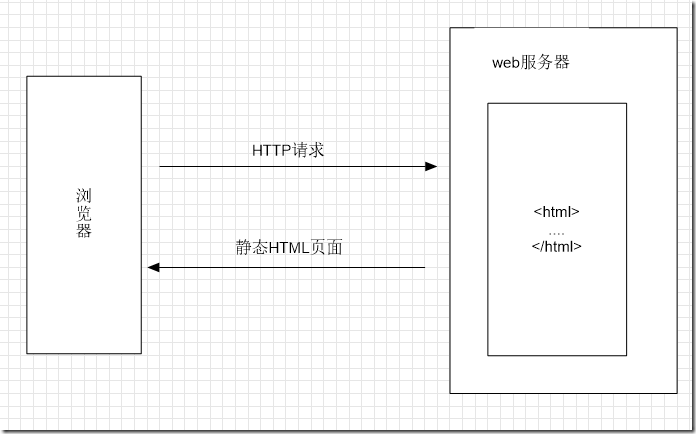
在浏览器发展的最初阶段,Web页面的这种静态性不成问题,科学家只是使用Internet来交换研究论文,大学院校也只是通过Internet在线发布课程信息等
随着网页从学术机构走向公众社会,网页承载的功能便超出了学术范围而变得愈加丰富,因此早期网页的局限性也逐渐显露出来
学术自然是枯燥的,走向社会就不一样了,娱乐生活等等,所以用户自然对web能提供的服务有了更多的需求(期望),这是一个很自然的需求演变
CGI
人们当然不满足于访问web服务器上的静态资源
1993年CGI(Common Gateway Interface)出现了
CGI定义了Web服务器与外部应用程序之间的通信接口标准,Web服务器可以通过CGI执行外部程序,让外部程序根据Web请求内容生成动态的内容。
通常的处理流程是:
- 通过Internet把用户请求送到web服务器。
- web服务器接收用户请求并交给CGI程序处理。
- CGI程序把处理结果传送给web服务器。
- web服务器把结果送回到用户。
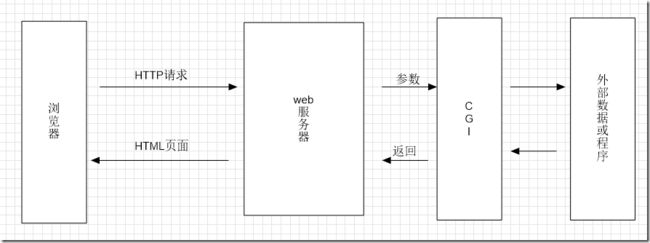
服务器在认为这是一个CGI请求时
会调用相关CGI程序,并通过环境变量和标准输出将数据传送给CGI程序
CGI程序处理完数据,生成html,然后再通过标准输出将内容返回给服务器,服务器再将内容交给用户,CGI进程退出
在这个过程中,服务器的标准输出对应了CGI程序的标准输入,CGI程序的标准输出对应着服务器的标准输入。
可以理解为,请求转变为了CGI程序的参数(以环境变量的形式传递),CGI的输出变成了web服务器的响应(CGI程序中直接向标准输出打印HTML页面)
CGI是一种标准,并不限定语言。所以Java、PHP、Python都可以通过这种方式来生成动态网页。
它规定了web服务器向CGI程序发送数据的格式约定(比如环境变量中有哪些值),以及响应的约定等内容(生成HTML页面)。
为什么使用CGI接口,而不是直接web服务器就提供这些功能?
如果web服务器提供这些功能,必然会导致web服务器的设计与开发过于复杂
而且,一旦web服务器实现了这些功能,开发者势必要按照web服务器提供的技术框架基础下进行开发,大大限制了生产力
所以借助于CGI接口,即能够提供调用外部程序处理的能力,也将这些功能从web服务器中解耦,解放了生产力。
可想而知,有了CGI,web发生了多大的变化
不仅仅可以提供静态的资源了,还能够进行动态的处理,数据的计算等
但是,每当一个CGI请求过来时,web服务器会fork一个子进程来执行相应的CGI程序,当请求结束时,该CGI进程也随之结束
这样不停fork进程的开销是非常大的,这是造成CGI程序效率低下的主要原因
后来出现了fastcgi,是改良版的CGI
而且,试想一下,当你要用C语言或者C++等等去一点点的处理html的内容,去拼接,去打印,是不是很辛苦?
char MimeType[]="text/html";
fprintf(stdout, "Content-type: %s\r\n\r\n", MimeType); //输出响应头,响应头之后要加两个"\r\n"
fprintf(stdout, "
fprintf(stdout, "这是一个由C编写的CGI小程序\n");
做过js拼接的就可以理解,但是很显然,之前的CGI比你做过的js的拼接还要恶心
web编程脚本语言
人们发现,对于一个HTML页面,往往发生变化的只是很少一部分数据,很大一部分仍旧是静态的
比如一个只有一个页面访问计数器的页面,唯一动态的数据就是那个“计数”,整个的页面的其他部分都是静态的。
是不是可以将不变的部分与变化的部分进行解耦呢?
于是又进化出后来的web编程脚本语言
PHP于1994年由Rasmus Lerdorf创建,刚刚开始是Rasmus Lerdorf为了要维护个人网页而制作的一个简单的用Perl语言编写的程序。
这些工具程序用来显示 Rasmus Lerdorf 的个人履历,以及统计网页流量。
后来又用C语言重新编写,包括可以访问数据库。
他将这些程序和一些表单直译器整合起来,称为 PHP/FI,也就是说最初是C语言编写的CGI程序的封装集成整合
PHP实现了与数据库的交互以及用于生产动态页面的模板引擎
PHP可以把程序(动态内容)嵌入到HTML(模版)中去执行,不仅能更好的组织Web应用的内容,而且执行效率比CGI还更高
之后96年出现的ASP和98年出现的JSP本质上也都可以看成是一种支持某种脚本语言编程(分别是VB和Java)的模版引擎
web编程脚本语言是CGI的进一步演化与抽象,使CGI的开发使用更加高效易用,核心思想还是CGI
有了这些脚本语言,搭配上后端的数据库技术,Web的功能更加强劲,可以通过Web技术来构建几乎所有的应用系统。

企业开发平台
两大重要阵营J2EE/.NET
Sun公司在1998年发表JDK1.2版本的时候, 使用了新名称Java 2 Platform,即“Java2平台”
修改后的JDK称为Java 2 Platform Software Develping Kit,即J2SDK。
并分为标准版(Standard Edition,J2SE), 企业版(Enterprise Edition,J2EE),微型版(MicroEdition,J2ME)。J2EE便由此诞生。
当Web开始广泛用于构建大型应用时,系统的稳定性安全性分布式等方面的要求变得更高
在许多企业级应用中,例如数据库连接、邮件服务、事务处理等都是一些通用企业需求模块
这些模块如果每次在开发中都由开发人员来完成的话,将会造成开发周期长和代码可靠性差等问题
于是许多大公司开发了自己的通用模块服务,这些服务性的软件系列统称为中间件
J2EE就是使用Java语言,开发企业级web应用的一整套的解决方案
Java Servlet、Java Server Pages (JSP)和Enterprise Java Bean (EJB )是Java EE中的核心规范
Servlet和JSP是运行在服务器端的Web组件
让Java开发者同时拥有了类似CGI程序的集中处理功能和类似PHP的HTML嵌入功能
此外,Java的运行时编译技术也大大提高了Servlet和JSP的执行效率
Sun正式发布了J2EE版本后,紧接着,遵循J2EE标准,为企业级应用提供支撑平台的各类应用服务软件争先恐后地涌现了出来。
IBM的WebSphere、BEA的WebLogic都是这一领域里最为成功的商业软件平台。
简言之,Java本身的跨平台性非常适合web应用开发,Java也抓住了这一机遇,提供了企业级应用一整套的开发方案。
框架的百家争鸣时代
随者两大平台的诞生,web的技术发展趋于成熟与稳定,人们希望能够更好更快更高效的开发web
各种辅助web开发的技术,百花齐放,百家争鸣
web应用越来越复杂,各种功能的页面,各种各样的URL地址,大量的后台数据
MVC的概念被引入到web项目中来,出现了Structs Spring MVC等
控制器Controller负责响应请求,协调Model和View
Model,View和Controller的分开,是一种典型的关注点分离的思想,
不仅使得代码复用性和组织性更好,使得Web应用的配置性和灵活性更好。
此时,数据的访问也不仅仅是直接sql访问,出现了ORM(Object Relation Mapping)的概念
2001年出现的Hibernate就是其中的佼佼者
更多的全栈框架开始出现,比如2003年出现的Java开发框架Spring
同时更多的动态语言也被加入到Web编程语言的阵营中
2004年出现的Ruby开发框架Rails,2005出现的Python开发框架Django
都提供了全栈开发框架,或者自身提供Web开发的各种组件,或者可以方便的集成各种组件。
前端技术发展
JavaScript
随着web服务器的发展,在能够进行动态数据的处理之后,涌现出来了新的问题。
服务器负责表单的一些校验工作
看起来好像没什么,但是站在当时的环境下,在那个绝大多数用户都在使用调制解调器上网的时代,网络是很低速的
用户填写完一个表单点击提交,需要很多秒,才能得到服务器的反馈
然而最后完了服务器反馈给你说某个地方填错了......你是不是会崩溃?
人们希望是否可以在客户端进行这些基础校验工作,这就是Js诞生的背景
JavaScript诞生于1995年,前身是livescript
最开始是由浏览器厂商Netscape(网景)着手开发的,起初这是一种“自导自演”的语言。
你可以这么理解,浏览器是我自己开发的一个软件,我为了实现某种功能定义了一些规范条件语法,创造了一种语言
比如我说在我这个软件内var可以定义一个变量,我的这个软件就认识这个var,别人家的浏览器其实是不认识的
我自己的软件,可以解释我自定义的语言
就好比你定义了一个XML文件的格式,然后你编写相应的方法用于解析XML,是类似的逻辑
当然,浏览器不止一家,出现了这么一个好东西,大家就会都去搞,撕逼大战热火朝天
最终出来机构调节停火,也就是出台了ECMAScript,这是一个规范
由ECMA-262定义的ECMAScript其实与Web浏览器没有依赖关系,Web浏览器只是ECMAScript实现可能的宿主环境之一
JavaScript是一个ECMAScript规范的实现,就好像HotSpot遵循java虚拟机规范一样
完整的js实现包括
1.核心(ECMAScript)
2.文档对象模型(DOM)
3.浏览器对象模型(BOM)
CSS
另外由于项目应用规模的不断扩大,页面也越来越越复杂,你会发现,将样式与模板放到一个页面上
是一个非常糟糕的设计思路
1996年12月W3C推出了CSS规范的第一个版本
CSS(Cascading Style Sheets,层叠样式表)是一种将表示样式应用到标记的系统
CSS以设计、改变其HTML页面的样式而知名,并使用于Web和其他媒介,如XML文档中
CSS依附于HTML的结构对其样式进行渲染
AJAX/前端框架/Node
而对于浏览器端,除了前面提到的js css
在98年还出现了AJAX,05年之后大放异彩
一个页面上,有绝大多数的数据是固定不变的,所以演变出模板的形式,动态的渲染数据
然而,在很多时候,也并不是页面上的数据全部都需要变化,可能需要变化的仅仅只有很细微的一个地方
但是,哪怕你仅仅需要变动的是一个数字而已,也仍旧需要重新载入整个页面,这显然是资源的浪费,以及没必要的等待
ajax就是为了解决这个问题的而出现的一种局部刷新的技术
AJAX即“Asynchronous JavaScript and XML”(异步的JavaScript与XML技术)
指的是一套综合了多项技术的浏览器端网页开发技术
可以基于JavaScript的XmlHttpRequest的用于创建交互性更强的Web应用。
ajax的出现,可以让前后端工程师以ajax接口为分界点进行前后端分离
规定好交互接口后,前后端工程师就可以根据约定,分头开工
开发环境中通过Mock等方式进行测试,同时在特定时间节点进行前后端集成测试。
但是,随着业务功能的愈发复杂
这种模式本质上和JSP时代的Web开发并无本质区别,只不过是将复杂的业务逻辑从JSP文件转移到了JavaScript文件中而已。
所以很自然的又把MVC模式应用到了前端
前端开发也出现了大量的MVC框架
比较典型的包括BackboneJS, AngularJS, EmberJS, KnockoutJS。
随着各大浏览器的竞争,引擎越来越牛逼
Google V8引擎的性能已经足以运行大型Javascript程序
在V8之上加以网络、文件系统等内置模块,形成了如今的Node.js
随着Node.js的出现,JavaScript开始拥有在服务端运行的能力
它的异步本质使得Node.js在处理I/O密集型业务中优势凸显
而大多Web业务中I/O性能都是瓶颈
关于网络的演变,可以查看 http://www.evolutionoftheweb.com/ 图形化的展示了演进过程。
总结
以上可以看得出来,WEB的发展从提出一直都是在迅猛发展,WEB架构的核心思想一直都没有变化过:BS结构浏览器和服务器,通过HTTP协议交互,借助于URL进行资源定位,最终获取响应,而响应的内容则是HTML。
尽管WEB的规模在不断的变化,甚至可以说与日俱增的变化,核心是没有变化的
而WEB变化的方向也可以说是非常明确的,那就是工作的精细化拆分,不断地分工,不断地分工。
最开始需要动态处理的能力,所以借助于CGI程序,将处理能力外包;
项目不断扩大,所以按照功能进行拆分引入MVC模式;
引入模式后为了更便于开发维护,又出现了各种框架简化开发;
静态的模板内容和动态的数据内容相互耦合,所以进行分离;
模板与样式相互偶尔交织在一起,所以HTML结构与样式分离;
动态能力全部位于服务器所以出现了JS使客户端具有处理能力;
同步的处理数据量太大却有时又没有必要,所以出现了AJAX;
请求太多,一台服务器无法处理,所以出现了负载均衡;
一个数据库数据量太大,所以开始分库分表;
应用体量太大,所以将应用服务本身进行拆分,出现了分布式;
等等................................
可以看得出来,整个WEB项目发展基调如此:
活范围太宽,事儿太多怎么办?拆分、解耦!!!
活还是太多了干不完,咋整?分工!!!
分工、解耦、拆分、分工、解耦,拆分、水平拆分、垂直拆分、各种拆分.........
原文地址:互联网与Web技术的发展 网络发展简介(三)

posted @ 2019-01-09 09:50 noteless 阅读(...) 评论(...) 编辑 收藏