DotNetty完全教程(四)
ByteBuffer
Netty中ByteBuffer的介绍
Netty 的数据处理 API 通过两个组件暴露——abstract class ByteBuf 和 interface
ByteBufHolder
DotNetty中有AbstractByteBuffer IByteBuffer IByteBufferHolder
优点:
- 它可以被用户自定义的缓冲区类型扩展;
- 通过内置的复合缓冲区类型实现了透明的零拷贝;
- 容量可以按需增长(类似于 JDK 的 StringBuilder);
- 在读和写这两种模式之间切换不需要调用 ByteBuffer 的 flip()方法;
- 读和写使用了不同的索引;
- 支持方法的链式调用;
- 支持引用计数;
- 支持池化
原理:
每一个ByteBuf都有两个索引,读索引和写索引,read和write会移动索引,set和get不会引动索引。
使用ByteBuf
- 堆缓冲区(使用数组的方式展示和操作数据)
使用支撑数组给ByteBuf提供快速的分配和释放的能力。适用于有遗留数据需要处理的情况。
public override void ChannelRead(IChannelHandlerContext ctx, object msg)
{
IByteBuffer message = msg as IByteBuffer;
// 检查是否有支撑数组
if (message.HasArray)
{
// 获取数组
byte[] array = message.Array;
// 计算第一个字节的偏移
int offset = message.ArrayOffset + message.ReaderIndex;
// 获取可读字节数
int length = message.ReadableBytes;
// 调用方法,处理数据
HandleArray(array, offset, length);
}
Console.WriteLine("收到信息:" + message.ToString(Encoding.UTF8));
ctx.WriteAsync(message);
}
- 直接缓冲区
public override void ChannelRead(IChannelHandlerContext ctx, object msg)
{
IByteBuffer message = msg as IByteBuffer;
if (message.HasArray)
{
int length = message.ReadableBytes;
byte[] array = new byte[length];
message.GetBytes(message.ReaderIndex, array);
HandleArray(array, 0, length);
}
Console.WriteLine("收到信息:" + message.ToString(Encoding.UTF8));
ctx.WriteAsync(message);
}
- CompositeByteBuffer 复合缓冲区
如果要发送的命令是由两个ByteBuf拼接构成的,那么就需要复合缓冲区,比如Http协议中一个数据流由头跟内容构成这样的逻辑。
public override void ChannelRead(IChannelHandlerContext ctx, object msg)
{
IByteBuffer message = msg as IByteBuffer;
// 创建一个复合缓冲区
CompositeByteBuffer messageBuf = Unpooled.CompositeBuffer();
// 创建两个ByteBuffer
IByteBuffer headBuf = Unpooled.CopiedBuffer(message);
IByteBuffer bodyBuf = Unpooled.CopiedBuffer(message);
// 添加到符合缓冲区中
messageBuf.AddComponents(headBuf, bodyBuf);
// 删除
messageBuf.RemoveComponent(0);
Console.WriteLine("收到信息:" + message.ToString(Encoding.UTF8));
ctx.WriteAsync(message);
}
字节级操作
- 读取(不移动索引)
public override void ChannelRead(IChannelHandlerContext ctx, object msg)
{
IByteBuffer message = msg as IByteBuffer;
for (int i = 0; i < message.Capacity; i++)
{
// 如此使用索引访问不会改变读索引也不会改变写索引
byte b = message.GetByte(i);
Console.WriteLine(b);
}
Console.WriteLine("收到信息:" + message.ToString(Encoding.UTF8));
ctx.WriteAsync(message);
}
- 丢弃可丢弃字节
所谓可丢弃字节就是调用read方法之后,readindex已经移动过了的区域,这段区域的字节称为可丢弃字节。
message.DiscardReadBytes();
只有在内存十分宝贵需要清理的时候再调用这个方法,随便调用有可能会造成内存的复制,降低效率。
3. 读取所有可读字节(移动读索引)
while (message.IsReadable())
{
Console.WriteLine(message.ReadByte());
}
- 写入数据
// 使用随机数填充可写区域
while (message.WritableBytes > 4)
{
message.WriteInt(new Random().Next(0, 100));
}
- 管理索引
- MarkReaderIndex ResetReaderIndex 标记和恢复读索引
- MarkWriterIndex ResetWriterIndex 标记和恢复写索引
- SetReaderIndex(int) SetWriterIndex(int) 直接移动索引
- clear() 重置两个索引都为0,但是不会清除内容
- 查找
- IndexOf()
- 使用Processor
// 查找\r
message.ForEachByte(ByteProcessor.FindCR);
- 派生
派生的意思是创建一个新的ByteBuffer,这个ByteBuf派生于其他的ByteBuf,派生出来的子ByteBuf具有自己的读写索引,但是本质上指向同一个对象,这样就导致了改变一个,另一个也会改变。
- duplicate();
- slice();
- slice(int, int);
- Unpooled.unmodifiableBuffer(…);
- order(ByteOrder);
- readSlice(int)。
- 复制
复制不同于派生,会复制出一个独立的ByteBuf,修改其中一个不会改变另一个。
- copy
- 释放
// 显式丢弃消息
ReferenceCountUtil.release(msg);
- 增加引用计数防止释放
ReferenceCountUtil.retain(message)
- 其他api

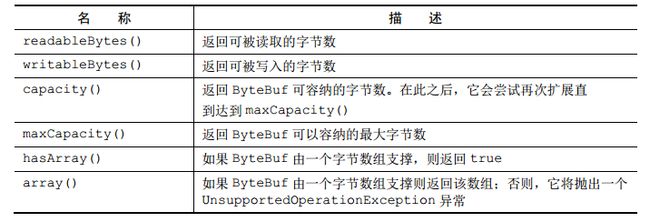
ByteBufHolder
- 目的
再数据处理的过程中不仅仅有字节数据内容本身,还会有一些附加信息,比如HTTP响应的状态码,Cookie等。给ByteBuf附加信息就要用到ByteBufHolder. - API

管理ByteBuffer
- 按需分配 ByteBufAllocator

注意分配是池化的,最大程度上降低分配和释放内存的开销。// 获取Allocator // 1 IChannelHandlerContext ctx = null; IByteBufferAllocator allocator = ctx.Allocator; // 2 IChannel channel = null; allocator = channel.Allocator;
有两种ByteBufAllocator的实现:PooledByteBufAllocator和UnpooledByteBufAllocator,前者池化了ByteBuf的实例,极大限度的提升了性能减少了内存碎片。
2. Unpooled缓冲区
获取不到 ByteBufAllocator的引用的时候我们可以使用Unpooled工具类来操作ByteBuf。

- ByteBufUtil
这个类提供了一些通用的API,都是静态的辅助方法,例如hexdump方法可以以十六进制的方式打印ByteBuf的内容。还有equal方法判断bytebuf是否相等。
引用计数
-
目的
ByteBuf和ByteBufHolder都有计数的机制。引用计数都从1开始,如果计数大于0则不被释放,如果等于0就会被释放。它的目的是为了支持池化的实现,降低了内存分配的开销。
-
异常
如果访问一个计数为0的对象就会引发IllegalReferenceCountException。