Python -advanced feature - N
https://mp.weixin.qq.com/s/eA6xXn13gAF_ms7ZWik8Tw
https://mp.weixin.qq.com/s/cgqejOR59N_WgLFKKjlGSw
https://mp.weixin.qq.com/s/KJY2_Vw5emI3HnUh2Ms4kQ
https://mp.weixin.qq.com/s/7ikWKvY4iYgTI9mzsa2MNQ
https://mp.weixin.qq.com/s/MrPB9dTjK68icPlQ97n4LA
https://mp.weixin.qq.com/s/EZxOuqxMZ-Gioni35zjacw
https://mp.weixin.qq.com/s/d-MrELK94yEQYwD__R2V6Q
https://mp.weixin.qq.com/s/sAS6g-xe0AcJEr1VwqQYwg
https://mp.weixin.qq.com/s/ya_cjadndL2icwezDV0ScQ
Python 多好用不用多说,大家看看自己用的语言就知道了。但是 Python 隐藏的高级功能你都 get 了吗?本文中,作者列举了 Python 中10种略高级的特征以及它们的使用方法,快来一探究竟吧!
1、isinstance
isinstance 函数可用于判断实例的类型,其实它的第二个参数可以是多个数据类型组成的元组。例如:
isinstance(x, (int, float))
# 等价于
isinstance(x, int) or isinstance(x, float)类似的函数还有字符串的 startswith 方法和 endswith 方法,例如:
s.startswith(('"""', "'''"))
# 等价于
s.startswith("'''") or s.startswith('"""')2、用 http.server ftp.server共享文件
# python3
python3 -m http.server
# python2
python -m SimpleHTTPServer
#FTP:
python -m pyftpdlib效果如下图所示,通过浏览器方便局域网共享文件
3、zip 函数实现字典键值对互换
lang = {"python":".py", "java":".java"}
dict(zip(lang.values(), lang.keys()))
{'.java': 'java', '.py': 'python'}4、查找列表中出现次数最多的数字
[1, 2, 3, 4, 2, 2, 3, 1, 4, 4, 4, 5]
max(set(test), key=test.count)
45、使用 __slots__ 节省内存
class MyClass(object):
def __init__(self, name, identifier):
self.name = name
self.identifier = identifier
self.set_up()
print(sys.getsizeof(MyClass))
>>> 1016
class MyClass(object):
__slots__ = ['name', 'identifier']
def __init__(self, name, identifier):
self.name = name
self.identifier = identifier
self.set_up()
print(sys.getsizeof(MyClass))
>>> 8886、Lambda 函数
Lambda 函数是一种比较小的匿名函数——匿名是指它实际上没有函数名。
Python 函数通常使用 def a_function_name() 样式来定义,但对于 lambda 函数,我们根本没为它命名。这是因为 lambda 函数的功能是执行某种简单的表达式或运算,而无需完全定义函数。
lambda 函数可以使用任意数量的参数,但表达式只能有一个。
x = lambda a, b : a * b
print(x(5, 6)) # prints '30'
x = lambda a : a*3 + 3
print(x(3)) # prints '12'
7 Map 函数
Map() 是一种内置的 Python 函数,它可以将函数应用于各种数据结构中的元素,如列表或字典。对于这种运算来说,这是一种非常干净而且可读的执行方式。
def square_it_func(a):
return a * a
x = map(square_it_func, [1, 4, 7])
print(x) # prints '[1, 16, 47]'
def multiplier_func(a, b):
return a * b
x = map(multiplier_func, [1, 4, 7], [2, 5, 8])
print(x) # prints '[2, 20, 56]'看看上面的示例!我们可以将函数应用于单个或多个列表。实际上,你可以使用任何 Python 函数作为 map 函数的输入,只要它与你正在操作的序列元素是兼容的。
8 Filter 函数
filter 内置函数与 map 函数非常相似,它也将函数应用于序列结构(列表、元组、字典)。二者的关键区别在于 filter() 将只返回应用函数返回 True 的元素。
详情请看如下示例:
# Our numbers
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
# Function that filters out all numbers which are odd
def filter_odd_numbers(num):
if num % 2 == 0:
return True
else:
return False
filtered_numbers = filter(filter_odd_numbers, numbers)
print(filtered_numbers)
# filtered_numbers = [2, 4, 6, 8, 10, 12, 14]我们不仅评估了每个列表元素的 True 或 False,filter() 函数还确保只返回匹配为 True 的元素。非常便于处理检查表达式和构建返回列表这两步。
9 Itertools 模块
Python 的 Itertools 模块是处理迭代器的工具集合。迭代器是一种可以在 for 循环语句(包括列表、元组和字典)中使用的数据类型。
使用 Itertools 模块中的函数让你可以执行很多迭代器操作,这些操作通常需要多行函数和复杂的列表理解。关于 Itertools 的神奇之处,请看以下示例:
from itertools import *
# Easy joining of two lists into a list of tuples
for i in izip([1, 2, 3], ['a', 'b', 'c']):
print i
# ('a', 1)
# ('b', 2)
# ('c', 3)
# The count() function returns an interator that
# produces consecutive integers, forever. This
# one is great for adding indices next to your list
# elements for readability and convenience
for i in izip(count(1), ['Bob', 'Emily', 'Joe']):
print i
# (1, 'Bob')
# (2, 'Emily')
# (3, 'Joe')
# The dropwhile() function returns an iterator that returns
# all the elements of the input which come after a certain
# condition becomes false for the first time.
def check_for_drop(x):
print 'Checking: ', x
return (x > 5)
for i in dropwhile(should_drop, [2, 4, 6, 8, 10, 12]):
print 'Result: ', i
# Checking: 2
# Checking: 4
# Result: 6
# Result: 8
# Result: 10
# Result: 12
# The groupby() function is great for retrieving bunches
# of iterator elements which are the same or have similar
# properties
a = sorted([1, 2, 1, 3, 2, 1, 2, 3, 4, 5])
for key, value in groupby(a):
print(key, value), end=' ')
# (1, [1, 1, 1])
# (2, [2, 2, 2])
# (3, [3, 3])
# (4, [4])
# (5, [5])
10 Generator 函数
Generator 函数是一个类似迭代器的函数,即它也可以用在 for 循环语句中。这大大简化了你的代码,而且相比简单的 for 循环,它节省了很多内存。
比如,我们想把 1 到 1000 的所有数字相加,以下代码块的第一部分向你展示了如何使用 for 循环来进行这一计算。
如果列表很小,比如 1000 行,计算所需的内存还行。但如果列表巨长,比如十亿浮点数,这样做就会出现问题了。使用这种 for 循环,内存中将出现大量列表,但不是每个人都有无限的 RAM 来存储这么多东西的。Python 中的 range() 函数也是这么干的,它在内存中构建列表。
代码中第二部分展示了使用 Python generator 函数对数字列表求和。generator 函数创建元素,并只在必要时将其存储在内存中,即一次一个。这意味着,如果你要创建十亿浮点数,你只能一次一个地把它们存储在内存中!Python 2.x 中的 xrange() 函数就是使用 generator 来构建列表。
上述例子说明:如果你想为一个很大的范围生成列表,那么就需要使用 generator 函数。如果你的内存有限,比如使用移动设备或边缘计算,使用这一方法尤其重要。
也就是说,如果你想对列表进行多次迭代,并且它足够小,可以放进内存,那最好使用 for 循环或 Python 2.x 中的 range 函数。因为 generator 函数和 xrange 函数将会在你每次访问它们时生成新的列表值,而 Python 2.x range 函数是静态的列表,而且整数已经置于内存中,以便快速访问。
# (1) Using a for loopv
numbers = list()
for i in range(1000):
numbers.append(i+1)
total = sum(numbers)
# (2) Using a generator
def generate_numbers(n):
num, numbers = 1, []
while num < n:
numbers.append(num)
num += 1
return numbers
total = sum(generate_numbers(1000))
# (3) range() vs xrange()
total = sum(range(1000 + 1))
total = sum(xrange(1000 + 1))
原文链接:https://towardsdatascience.com/5-advanced-features-of-python-and-how-to-use-them-73bffa373c84
-
PEP 8 是什么?Python 之禅(import this)是什么?
-
Python 常用的容器类型有哪些以及它们之间的差别?
-
解释下闭包是什么,以及日常中什么场景会用到?
-
GIL 是什么?它的影响和具体原理是什么?
-
进程、协程、线程分别是什么,以及区别是什么?
-
如何理解 Django 被称为 MTV 模式?
-
解释下什么是 ORM 以及它的优缺点是什么?
-
如何排查 Django 系统中的性能问题?
-
Django 系统中如何配置数据库的长连接?
-
如何部署并监控 Django 系统?
咳咳!别说,有几个问题也把狗哥难住了。是时候请出胡阳老师了!掌声响起来~

Hi,我是胡阳,网名 the5fire,前搜狐资深开发工程师,现任知乎资深开发工程师,负责部分业务的后端开发和团队管理。同时也是腾讯云最具价值专家(TVP)。
我平时喜欢通过代码来构建一些有价值的东西,有着近 10 年编程经验和写博客经验,爱好记录和分享自己的经验。
2011 年Java转到Python后,主要熟悉 Web 框架 Django 和 Tornado。赞叹于Python 的开发效率,欣赏 Django 完备的功能点对实际项目开发中程序员生产力的提升。
今天狗哥请我来帮一位读者解决面试的问题,其实我们都是从这个阶段过来的。所以能帮上大家也是比较开心的。那今天我从面试的角度给大家归纳下 Django 工程师面试时面试官都会问些啥。
其实解析这些问题之前,大家要明白一个基本原则:面试的目的是找到合适的候选人,提问的目的是为了考察当前候选人对当前岗位的匹配度。所以,所有的问题基本上都会围绕着工作内容来展开,但最终还是会落到具体的技术点上。
不知道你有没有自己思考下对应问题的答案。这十个问题可能只是面试的开始,要知道技术类的面试要是聊的嗨了,聊一两个小时是常事儿。所以,如果你在面试,这十个问题你要怎么来答呢?
Q1:PEP8是什么?Python之禅(import this)是什么?
这题是考察你对编码规范的认识,无论是自己写代码还是在团队中写代码,了解并遵循代码规范是很基础的要求。企业中在提交代码后都会有对应的工具来对代码进行检查,比如 pep8、flake8、pylint 等,但是 PEP 8 是什么一定要了解。
即 Style Guide for Python Code(Python编码风格指南)。如果面试时不知道什么是 PEP 8 ,那聊起来想必不会很愉快。速战速决的面试,如果不是你把面试官“秒杀”了,那就是面试官把你“秒杀”了,大部分是后者。 Python 之禅,也就是 import this。这属于对 Python 文化的了解了。什么意思?你去 Python shell 里执行一下:import this,然后搜索下答案自然就出来了。
Q2:Python常用的容器类型有哪些以及它们之间的差别?
这是一道基础题。如果被问到了这个问题,说明面试官在探测你对 Python 基础的掌握。如果不知道,那就会被“秒杀”。当然聊得好了,也可以聊到实现原理层面。
在 Python 中常用的数据类型,有一些是基础数据类型,比如 int、bool、string,还有容器类型,比如 list、set、dict 等。所有的类型又可以氛分为:可变类型和不可变类型(不知道是什么的可以动手搜索一下)。单说容器类型,每种容器类型都有使用的场景,比如 list 可以存放不同类型的元素,特点是支持索引和切片操作,支持 insert 和 pop 操作,属于可变类型。由此也可以展开很多面试题中遇到的坑,比如说这个代码:
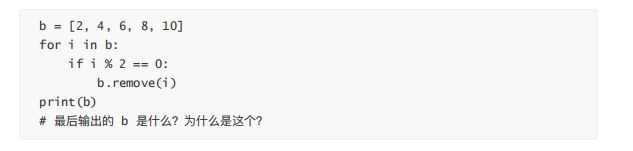 然后再来说到 tuple,也可以当做列表,支持迭代、索引、切片等操作,但因为它是不可变类型,所以不支持 append、insert 等操作,为什么不支持呢?在从应用上来说,在实际编程中经常会用到它,比如:参数传递,解包。这一部分可以继续聊下去的就是namedtuple。再然后就是 set 和 dict,它们跟 list 和 tuple有这么几个差别:1. 存放的值不是顺序的;2. 无法通过索引获取到数据; 3. 存放的元素不可重复,并且必须是 hashable(可哈希的),针对 key 来说;4. 更快的查找速度,因为是通过哈希表来存储的。当然还可以继续深入 set 和 dict 的原理,如何解决哈希碰撞。
然后再来说到 tuple,也可以当做列表,支持迭代、索引、切片等操作,但因为它是不可变类型,所以不支持 append、insert 等操作,为什么不支持呢?在从应用上来说,在实际编程中经常会用到它,比如:参数传递,解包。这一部分可以继续聊下去的就是namedtuple。再然后就是 set 和 dict,它们跟 list 和 tuple有这么几个差别:1. 存放的值不是顺序的;2. 无法通过索引获取到数据; 3. 存放的元素不可重复,并且必须是 hashable(可哈希的),针对 key 来说;4. 更快的查找速度,因为是通过哈希表来存储的。当然还可以继续深入 set 和 dict 的原理,如何解决哈希碰撞。
Q3:解释下闭包是什么,以及日常中什么场景会用到?
闭包是指持有了自由变量的函数,那怎么理解呢,用代码来看一下:
 日常使用场景是什么呢?最常用会用到的地方就是装饰器,上面的示例代码也能看出来,比如我曾写过 Cache 的演进部分,部分代码如下:
日常使用场景是什么呢?最常用会用到的地方就是装饰器,上面的示例代码也能看出来,比如我曾写过 Cache 的演进部分,部分代码如下:
 这就是个典型的场景。
这就是个典型的场景。
Q4:GIL 是什么?它的影响和具体原理是什么?
GIL:Global Interpreter Lock(全局解释器锁)。具体表现就是:在一个进程中,同一时刻只能有一个线程能到解释器,为什么只能有一个线程拿到解释器呢?因为在 CPython 中,内存管理不是线性安全的,所以,为了避免多个线程同时访问到一个对象,就有了这么一个锁。顺带着也提到了线程安全的概念,有了 GIL 了,那么 Python 中有哪些类型是线程安全的呢?哪些不是呢?又是一个新的问题。那么 GIL 的影响是什么呢?就是同一时刻只有一个线程在真实执行,对于 CPU 密集型的应用影响比较大,对于 IO 密集型的应用影响没那么大。当然还可以具体展开来说。
Q5:进程、协程、线程分别是什么,以及区别是什么?
从操作系统角度来讲,进程是资源分配单元,线程是执行单元,多个线程可以共享所在进程的资源。而协程是从程序运行角度来叫,是由用户(程序)控制和调度的一个过程,在 Python 中,协程是一个包含了 yield 的函数,比如下图:
 在Python 3里面你可以用 asyncio.iscoroutine(coro) 来判断是否为协程。需要了解的是在协程执行时,是通过 event loop 来调度的。如果聊到这,可能会接着聊下 Tornado 的 IOLoop 的事。总体来说,协程可以理解为更轻量级的线程,能够在单线程中运行多个协程。需要注意的是,在 Python 中协程执行是串行的,这个是由于它的调度机制决定的,这点不同于 Golang。
在Python 3里面你可以用 asyncio.iscoroutine(coro) 来判断是否为协程。需要了解的是在协程执行时,是通过 event loop 来调度的。如果聊到这,可能会接着聊下 Tornado 的 IOLoop 的事。总体来说,协程可以理解为更轻量级的线程,能够在单线程中运行多个协程。需要注意的是,在 Python 中协程执行是串行的,这个是由于它的调度机制决定的,这点不同于 Golang。
Q6:如何理解 Django 被称为 MTV 模式?
如果是我来问这个问题,这个题就是面向对象设计和设计模式的开始。简单来说大家耳熟能详的模式叫: MVC。说是 Model View Controller,而在 Django 中因为 Template 来处理视图展现,所以称为: MTV。接下里会问到的就是分层的概念,有句话叫:“没有什么问题是不能通过增加一层解决的,如果有,那就再加一层。”当然还会有设计模式的一些原则等着你,比如开-闭原则、单一职责原则等。
Q7:解释下什么是 ORM 以及它的优缺点是什么?
ORM:Object Relational Mapping(对象关系映射),它做的事就是帮我们封装一下对数据库的操作,避免我们来写不太好维护的 SQL 代码。优点就是让我们写的代码更容易维护,因为里面不用夹杂着各种 SQL 代码。缺点是失去了 SQL 的灵活,并且越是通用的 ORM 框架,性能损耗会越大。
说到性能损耗,可以接着聊的是 Django 中的 raw sql,也就是说 Model.objects.raw 这个方法的使用,它的作用、原理、性能提升等。还可以继续聊另外一个老生常谈的问题:N+1 的问题。
Q8:如何排查 Django 系统中的性能问题?
对于 Django 这样一个非常成熟的框架来说,丰富的周边能够让我们快速的找到别人开源出来的优秀插件,比如说 Django-debug-toolbar,或者是 Django-silk 。但是一个基础问题是:在 Django 的 settings 中,设置DEBUG = True 和 DEBUG = False 的差别是什么?还可以聊的是对于 Django 处理请求到返回响应的具体流程。因为只有熟悉了整体流程,才能在合理的位置进行排查。比方说,当我们判断可能是数据库的问题时,那可能需要在 Model 层的某个方法上加上执行时间监测的逻辑。如果是 View 层的其他逻辑导致的,可能会在 Middleware 上增加执行时间监测的逻辑。
Q9:Django 系统中如何配置数据库的长连接?
这涉及到 Django 如何处理数据库连接细节的问题。默认情况下对于每一个请求 Django 都会建立一个新的数据库连接。这意味着当请求量过大时就会出现数据库(MySQL)的 Too many connection 的问题,对于这个问题,在其他的语言框架中有连接池这样的东西来减少数据库的连接数,来提升连接的使用效率。而在 Django 中,为了处理这一问题,增加了一个配置: CONN_MAX_AGE,在 settings 的 DATABASES 配置中。配置了该选项后,Django 会跟数据库保持链接(时长取决于 CONN_MAX_AGE 设定的值 ),不再会针对每个请求都创建新的连接了。但是需要注意的是,这跟数据库连接池的概念还不太一样。
Q10:如何部署并监控 Django 系统?
这个就是考察候选人对于真实项目的部署和线上问题排查的了解了。如果没有真实工作过,可能不太有概念。首先需要理解的是开发的流程,代码在程序员的电脑(开发机)上开发完成,然后部署到测试环境进行测试,这个过程可能是自动的(由 GitLab CI 触发或者其他类似逻辑),也可能是需要人工操作的(比如使用 Fabric 或者 ansible)手动执行部署操作。然后测试同学进行测试,没问题之后,代码合并到主分支(涉及Git相关的使用流程),再部署上线。
这时系统就可以对外提供服务了,那么问题来了,用户的访问是如何到你部署的系统中来的?再来说监控。监控的目的是为了保证程序的正常运行,如果出现问题我们可以及时发现并修复。所以,简单来说有两个确定的指标可以观察,第一个是状态码,对于 HTTP 服务来说,监控非 200 的状态码的数量是很有必要的;第二个就是应用内的异常监控,这个就是 Sentry 之类的系统来做了,通过它可以收集到具体的异常详情,完成的 Traceback,可以帮助我们快速地定位问题所在。
虽然说只有十个问题,但是在正式聊的时候,每个问题都是可以层层追问的,其实面试有个原则,就是:要追问到候选人答不出来,或者面试官不知道该问什么为止,因为需要确定候选人的技术掌握的边界(深度)。
Zope: www.zope.com
一个应用程序服务器,具有内容管理、团队开发、 XML、面向对象、 SOAP接口等一系先进特性,开源。
Gadfly:http://www.chordate.com/gadfly.html
一个用Python写的面向对象关系型数据库,具有小巧、快速、可移植性好的特点,具有大部分SQL语言特性。开源。
Wallbase:http://wallbase.net
Python编写的图片站点。
uTorrent :http://www.utorrent.com
BitTorrent下载软件,主程序仅2Mb,支持ipv6地址解析。开源。
Torchlight:torchlight.perfectworld.com
Python编写的大型3D游戏,原Blizzard公司人员制作发行,开源