文章目录
- 1. path_or_buf 要读取的json对象
- 2. orient 指定解析json的格式
- 3. tye 指定返回的数据类型
- 4. dtype 推断或指定列的数据类型
- 5. convert_axes
- 6. convert_dates
- 7. keep_default_dates
- 8. numpy
- 9. precise_float 解析浮点型
- 10. date_unit 解析时间戳的单位
- 11. encoding 编码
- 12. lines
- 13. chunksize
- 14. compression 压缩
1. path_or_buf 要读取的json对象
- json字符串, json文件路径, json文件URL, json字符串IO对象
- 会自动推断json格式, 当无法自动推断或有异议时请指定orient
- 以下示例是可以自动推断出格式的json字符串
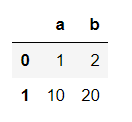
data1 = [{"a" : 1, "b" : 2}, {"a" : 10, "b" : 20}]
data2 = {"A": {"a" : 1, "b" : 2}, "B": {"a" : 10, "b" : 20}}
data3 = {"A": [1, 2], "B": [3, 4]}
pd.read_json(json.dumps(data1))
2. orient 指定解析json的格式
- split: {index -> [index], columns -> [columns], data -> [values]}
- records: [{column -> value}, … , {column -> value}]
- index: {index -> {column -> value}}
- columns: {column -> {index -> value}}
- values: 数组
- 当 typ == ‘series’ 时,仅支持 {‘split’,‘records’,‘index’}, 默认为 index
- 当 typ == ‘frame’ 时, 支持 {‘split’,‘records’,‘index’, ‘columns’,‘values’, ‘table’} 默认为 columns
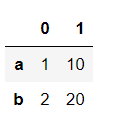
data1 = [{"a" : 1, "b" : 2}, {"a" : 10, "b" : 20}]
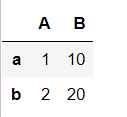
data2 = {"A": {"a" : 1, "b" : 2}, "B": {"a" : 10, "b" : 20}}
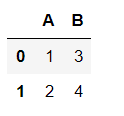
data3 = {"A": [1, 2], "B": [3, 4]}
data4 = {"index": ["a", "b"], "columns": ["A", "B"], "data": [[1, 2], [3, 4]]}
pd.read_json(json.dumps(data1), orient="index")
pd.read_json(json.dumps(data2), orient="index")
pd.read_json(json.dumps(data3), orient="index")
pd.read_json(json.dumps(data4), orient="split")



3. tye 指定返回的数据类型
- frame 默认值, 返回DataFrame
- series 返货Series
data5 = {"index": ["a", "b"], "data": [[1, 2], [3, 4]]}
pd.read_json(json.dumps(data5), orient="split", typ="series")

4. dtype 推断或指定列的数据类型
- True 默认值,自动推断
- False 不推断数据类型
- dict 根据列名指定数据类型
data2 = {"A": {"a" : 1, "b" : 2}, "B": {"a" : 10, "b" : 20}}
pd.read_json(json.dumps(data2), dtype={"A": float})

5. convert_axes
6. convert_dates
- True 默认值,会尝试解析列名类似如下规则的列为日期
- 以 _at 结尾
- 以 _time 结尾
- 以 timestamp 开头
- modified or date
- False 不解析日期
- [str] 指定要解析为日期的列名
data6 = {"create_time": {"a" : 1111111111, "b" : 1111111112}, "B": {"a" : 10, "b" : 20}}
pd.read_json(json.dumps(data6))

7. keep_default_dates
- True 默认值 只有当convert_dates也为True时才会尝试自动解析日期列
- False 即使convert_dates为True也不会自动推断解析日期, 但如果指定具体的解析列依然会正常解析
8. numpy
- True 直接解析为数组, 仅支持纯数字的数据, 会将所有数据转为整型
9. precise_float 解析浮点型
- True 使用更高精度的(strtod) 函数解析 double 数据类型
- False 默认 使用内置函数解析
10. date_unit 解析时间戳的单位
- 默认自动推断
- 也可指定 s, ms, us, ns
11. encoding 编码
12. lines
13. chunksize
14. compression 压缩
- infer 根据文件后缀名自动推断
- {‘gzip’, ‘bz2’, ‘zip’, ‘xz’, None}