【DNN】DIEN算法原理
在阿里的DIN之后,随后推出了DIEN,发表于2018年,论文地址点击这里 。
重点:
- DIEN相比之前的DIN,主要的trick在于对于用户的长期兴趣和短期兴趣的刻画,引入了有监督的AUGRU网络,刻画的更加准确。
- 为了捕捉用户兴趣的演变,以及用户对目标ad的兴趣,又加了一层带attention的GRU网络。
- 带attention的GRU网络中,作者尝试了3种不同的形式,最后得到的结论是对update gate作加权效果最好,GRU结构中,update gate反应的是从当前时刻隐藏层和前一时刻隐藏层各继承多少信息。
论文精读
abstract
在ctr预估中,捕捉用户历史行为数据中的潜在兴趣是比较重要的一项工作。考虑到外部环境的内部认知的变化,用户兴趣也在动态的发生变化。有很多ctr方法对兴趣进行建模,这些方法直接将行为的表示视为兴趣,缺少对潜在兴趣的建模,对当前行为的深入挖掘。很少有方法考虑兴趣的变化,本文,提出DIEN,设计了interest extractor layer 从用户历史行为序列中捕捉当时的兴趣。在兴趣提取层我们多加入了一个loss,去监督每一步的兴趣提取情况。在电商领域,用户的兴趣是多种多样的,我们提出兴趣进化层(interest evolving layer )去捕捉兴趣随着目标item的进化过程。
Introduction
在大多数的非搜索场景下,用户没有表现出他们当前的意图。设计模型去捕捉用户的兴趣是ctr预估性能提升的一个方面。DIN指出用户的兴趣是多样性的,引入attention模型捕捉用户相对于target item的兴趣,得到自适应的兴趣表示。然而,DIN建模的兴趣是直接将行为视为了兴趣。我们知道,潜在的兴趣很难从显示的行为中反应出来。前面的方法忽略了从用户行为中挖掘用户的真实兴趣。用户的兴趣是持续变化的,从兴趣表示中捕捉兴趣的动态变化是非常重要的。
DIEN的两个主要创新:
1.从显示的行为中,提取潜在的当前兴趣。
2.对兴趣进化过程进行建模。
兴趣表示是对兴趣进化建模的重要基础。在兴趣提取层,DIEN使用GRU来建模行为之间的依赖。兴趣最终来源于连续的序列行为中,我们使用了额外的loss,用下一个行为来监督当前hidden state的学习。我们将这个hidden state作为兴趣状态,额外的监督信息有助于捕捉更多兴趣表示的语义信息,使用GRU的hidden state去表示兴趣。用户的兴趣是多样的,会存在兴趣漂移现象,比如,在近邻的一些访问中,用户的意图是非常不同的。一个用户的行为可能依赖于另一个停留时间比较久的行为。每一个兴趣都有自己的进化轨迹。用户对不同item的点击行为会受到兴趣的影响。兴趣进化层建模时,依赖于target item。从兴趣提取层获得兴趣序列,设计了带有AUGRU(attentional update gate )的GRU。用兴趣状态和target item的计算相关性,AUGRU增强了相关兴趣对兴趣进化的影响,弱化了不相关兴趣对结果的影响(避免了兴趣漂移现象,这个地方我的理解是,比如真实想买一个裙子,可能看到短裤后,点击,并且有过停留,但最终还是想要买裙子,此时会把短裤的行为认为是兴趣漂移)。
文章DIEN 主要贡献:
1.聚焦于电商系统的兴趣演化现象,提出新的网络给兴趣演化过程进行建模。
2.设计了兴趣提取层。GRU的hidden state对兴趣的表示缺少针对性,我们提出额外的loss,用连续的行为去监督hidden state的学习。是的hidden state充分的表示潜在兴趣。
3.设计了兴趣演化层,AUGRU增强了跟目标item的相关性,客服了兴趣的漂移。
related work
wide&deep和deepFM组合低阶和高阶特征去提升表达能力。PNN提出一个product层捕捉不同类别的交互形式。这些模型中,用户的历史行为通过embeding和pooling的方式转换为低阶向量,但是这并不能反映出隐藏在数据背后的用户兴趣。DIN通过引入attention机智,来激活跟给定target item相关的历史行为,捕捉用户行为的多样性,但是,DIN获取序列行为之间的关联时,能力较弱。
基于RNN的模型,可以通过item被购买的序列,得到每个用户的动态表示,也存在一些问题,比如,RNN将序列结构的hidden state直接作为潜在的兴趣,其实hidden state在表示兴趣时,缺少一定的监督。另一方面,现存的RNN模型一视同仁的处理近邻行为之间的依赖关系。用户的行为并不是严格依赖最近一段时间内的行为。每个用户的兴趣是多样的,每个兴趣有自己的演化轨迹,对于任意的target item,这些模型只能获得一个固定的演化轨迹,可能会被兴趣漂移所干扰。
为了使用序列结构的hidden state表示潜在兴趣,额外的监督行为引入了进来。DARNN引入ranking information,建模点击行为。还有人将ranking loss引入的ranking task中。类似的,本文提出了一个额外的loss用于学习用户的潜在兴趣。这个loss用连续点击的item,跟非点击的item对比,去监督兴趣表示的学习。
为了捕捉跟target item相关的兴趣演化进程,我们需要更加灵活的序列学习结构。在问答系统中,AGRU引入attention机制保持位置和输入的实际顺序的敏感度。在AGRU中,attention score替代了更新gate的vector,这个表示胡烈了不同维度update gate之间的区别,这些不同的维度中从先前的序列中提取出了丰富的信息。收到这个方法的启发,本文提出了AUGRU去激活在兴趣演化进程中跟target item相关的兴趣。跟AGRU不同的是,AUGRU的attention score从update gate中获取信息,使得演化过程更加敏感和精确。
Deep Interest Evolution Network
Review of BaseModel
Feature Representation
4中类别特征:用户画像,用户行为,Ad和context。每一个类别进行one hot,然后组成一个list。
The Structure of BaseModel
Embedding :将高维稀疏特征映射到低维dense特征的通用操作。在embeding层中,每一个field的特征尤其对应的embeding矩阵。
Multilayer Perceptron (MLP) :某一个类别的embeding向量,会进行一个pooling的操作,不同类别的embeding向量经过pooling之后的向量进行拼接concatenated。最后送入到mlp去预测最终结果。
Loss Function
交叉熵损失函数:
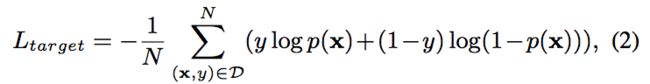
p(x)表示预测用户点击target item的概率。
模型整体框架
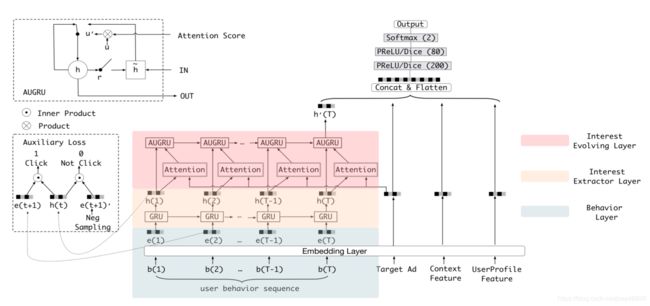
Deep Interest Evolution Network
DIEN通过对兴趣进化过程建模,捕捉用户兴趣。兴趣提取层从行为序列中提取兴趣序列,兴趣演化层留下了跟target item相近的兴趣演化轨迹。
Interest Extractor Layer