ElasticSearch学习与总结
ElasticSearch学习与总结
- ElasticSearch
- 1. 介绍
- 2. 入门操作
- 2.1 下载
- 2.2 安装可视化界面head
- 2.3 安装kibana
- 3. ES核心概念
- 4. IK分词器插件
- 4.1 下载安装
- 4.2 使用Kibana测试:
- 4.3 用户配置字典
- 5. Rest风格
- 5.1 简介
- 5.2 测试
- 5.3 数据类型
- 5.4 关于索引的基本操作
- 5.5 关于文档的基本操作(重点)
- 5.5.1 基本操作
- 5.5.2 复杂查询
- 6. 集成Springboot
- 6.1 集成Springboot
- 6.2 索引API操作
- 6.3 文档API操作
- 6.4 批量操作Bulk
- 6.5 搜索
ElasticSearch
1. 介绍
-
本笔记参考狂神说,版本为7.6.X
- https://www.bilibili.com/video/BV17a4y1x7zq?p=2
-
Lucene是一套信息检索工具包(jar包),不含搜索引擎系统
-
ElasticSearch是基于Lucene做了一些封装和增强
2. 入门操作
- JDK1.8以上,客户端,界面工具
- 版本对应。
2.1 下载
官网下载
windows下解压就可以使用
目录:
bin:启动文件
config:配置文件
log4j2 日志文件
jvm.options 虚拟机文件
elasticsearch.yml 配置文件 比如默认9200端口
lib:相关jar包
modules:功能模块
plugins:插件:比如ik插件
启动,然后localhost:9200访问
2.2 安装可视化界面head
-
es head插件,github上面下载
- https://github.com/mobz/elasticsearch-head
-
npm install npm run start #启动插件:localhost:9100 -
解决跨域问题:修改elasticsearch.yml文件
-
#解决跨域问题 http.cors.enabled: true http.cors.allow-origin: "*"
-
2.3 安装kibana
- ELK:日志分析架构栈
- 注意:下载版本与es一致;可以在配置文件中汉化
- 默认端口 localhost:5601
3. ES核心概念
-
es是面向文档的,一切都是JSON
-
对比
-
关系型数据库 Elasticsearch 数据库database 索引 indices(数据库) 表tables types (以后会被启用) 行rows documents (文档) 字段columns fields
-
-
物理设计
- 在后台把每个索引划分为多个分片,每片可以再集群中的不同服务器间迁移;
-
逻辑设计
- 文档:索引和搜索数据的最小单位是文档;
- 自我包含:key:value
- 层次型:一个文档中包含文档(json对象)
- 类型:文档的逻辑容器
- 索引:数据库
- 文档:索引和搜索数据的最小单位是文档;
-
倒排索引
- es使用倒排索引的结构,采用Lucene倒排索引作为底层。用于快速全文检索。
4. IK分词器插件
- 什么是IK分词器:
- 把一句话分词
- 如果使用中文:推荐IK分词器
- 两个分词算法:ik_smart(最少切分),ik_max_word(最细粒度划分)
4.1 下载安装
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
然后解压,放到elasticsearch的plugins中,建立“ik”文件夹,然后放入;
重启观察es:发现加载ik插件了
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ewUmG3or-1590485221083)(http://njpsz.xyz/images/ik.png)]
4.2 使用Kibana测试:
【ik_smart】测试:
输入:
GET _analyze
{
"analyzer": "ik_smart",
"text": "我是社会主义接班人"
}
输出:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "社会主义",
"start_offset" : 2,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "接班人",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 3
}
]
}
【ik_max_word】测试:
输入:
GET _analyze
{
"analyzer": "ik_max_word",
"text": "我是社会主义接班人"
}
输入:
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "社会主义",
"start_offset" : 2,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "社会",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "主义",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "接班人",
"start_offset" : 6,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "接班",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "人",
"start_offset" : 8,
"end_offset" : 9,
"type" : "CN_CHAR",
"position" : 7
}
]
}
4.3 用户配置字典
当一些特殊词(比如姓名)不能被识别切分时候,用户可以自定义字典:

重启es和kibana测试
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dNxpUIif-1590485221097)(http://njpsz.xyz/images/20200417150218.png)]
5. Rest风格
5.1 简介
RESTful是一种架构的规范与约束、原则,符合这种规范的架构就是RESTful架构。
操作
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9100/索引名称/类型名称/文档id | 创建文档(指定id) |
| POST | localhost:9100/索引名称/类型名称 | 创建文档(随机id) |
| POST | localhost:9100/索引名称/文档类型/文档id/_update | 修改文档 |
| DELETE | localhost:9100/索引名称/文档类型/文档id | 删除文档 |
| GET | localhost:9100/索引名称/文档类型/文档id | 查询文档通过文档id |
| POST | localhost:9100/索引名称/文档类型/_search | 查询所有文档 |
5.2 测试
- 1、创建一个索引
PUT /索引名/类型名/id - 默认是_doc
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DeUg5fjf-1590485221110)(http://njpsz.xyz/images/20200417153651.png)]

5.3 数据类型
- 基本数据类型
- 字符串 text, keyword
- 数据类型 long, integer,short,byte,double,float,half_float,scaled_float
- 日期 date
- 布尔 boolean
- 二进制 binary
- 制定数据类型
输入:创建规则
PUT /test2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"birthday": {
"type": "date"
}
}
}
}
输出:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test2"
}
如果不指定具体类型,es会默认配置类型
5.4 关于索引的基本操作
-
查看索引信息:
GET test2
-
查看es信息
get _cat/
-
修改
-
之前的办法:直接put
-
现在的办法:
POST /test3/_doc/1/_update
{
“doc”: {
“name”: “庞世宗”
}
} -
-
删除索引
DELETE test1
5.5 关于文档的基本操作(重点)
5.5.1 基本操作
1、添加数据
PUT /psz/user/1
{
"name": "psz",
"age": 22,
"desc": "偶像派程序员",
"tags": ["暖","帅"]
}
2、获取数据
GEt psz/user/1
===============输出===========
{
"_index" : "psz",
"_type" : "user",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "psz",
"age" : 22,
"desc" : "偶像派程序员",
"tags" : [
"暖",
"帅"
]
}
}
3、 更新数据PUT
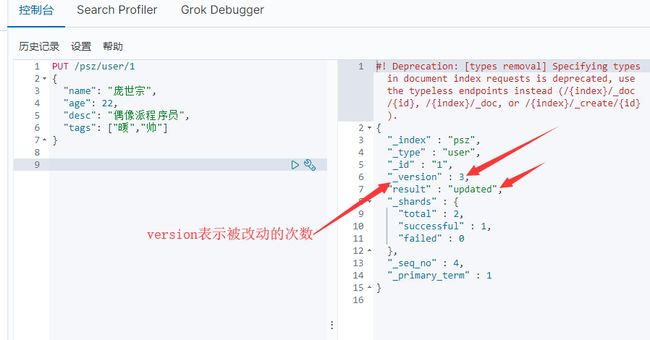
4、更新数据,推荐POST _update
- 不推荐
POST psz/user/1
{
"doc":{
"name": "庞庞胖" #后面信息会没有
}
}
- 推荐!
POST psz/user/1/_update
{
"doc":{
"name": "庞庞胖" #后面信息存在
}
}
5、简单搜索 GET
GET psz/user/1
简答的条件查询:根据默认映射规则产生基本的查询
GET psz/user/_search?q=name:庞世宗
5.5.2 复杂查询
1、查询,参数使用JSON体
GET psz/user/_search
{
"query": {
"match": {
"name": "庞世宗" //根据name匹配
}
},
"_source": ["name","age"], //结果的过滤,只显示name和age
"sort": [
{
"age": {
"order": "desc" //根据年龄降序
}
}
],
"from": 0, //分页:起始值,从0还是
"size": 1 //返回多少条数据
}
- 之后只用java操作es时候,所有的对象和方法就是这里面的key
- 分页前端 /search/{current}/{pagesize}
2 、布尔值查询
- must(对应mysql中的and) ,所有条件都要符合
GET psz/user/_search
{
"query": {
"bool": {
"must": [ //相当于and
{
"match": {
"name": "庞世宗"
}
},
{
"match": {
"age": 22
}
}
]
}
}
}
- shoule(对应mysql中的or)
GET psz/user/_search
{
"query": {
"bool": {
"should": [ //should相当于or
{
"match": {
"name": "庞世宗"
}
},
{
"match": {
"age": 22
}
}
]
}
}
}
-
must_not (对应mysql中的not)
-
过滤器
GET psz/user/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "庞世宗"
}
}
],
"filter": [
{
"range": {
"age": {
"gt": 20 //过滤年龄大于20的
}
}
}
]
}
}
}
3、精确查询
- trem查询是直接通过倒排索引指定的词条进行精确的查找的。
关于分词:
trem,直接查询精确地
match,会使用分词器解析
关于类型:
text: 分词器会解析
keywords: 不会被拆分
4、高亮查询
GET psz/user/_search
{
"query": {
"match": {
"name": "庞世宗"
}
},
"_source": ["name","age"],
"sort": [
{
"age": {
"order": "desc"
}
}
],
"highlight": //高亮
{
"pre_tags": ""
, //自定义高亮
"post_tags": "",
"fields": {
"name":{} //自定义高亮区域
}
}
}
6. 集成Springboot
6.1 集成Springboot
官方文档:https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/index.html
1、找到原生的依赖
<dependency>
<groupId>org.elasticsearch.clientgroupId>
<artifactId>elasticsearch-rest-high-level-clientartifactId>
<version>7.6.2version>
dependency>
<properties>
<java.version>1.8java.version>
<elasticsearch.version>7.6.1elasticsearch.version>
properties>
2、找对象
Initialization
A RestHighLevelClient instance needs a REST low-level client builder to be built as follows:
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
The high-level client will internally create the low-level client used to perform requests based on the provided builder. That low-level client maintains a pool of connections and starts some threads so you should close the high-level client when you are well and truly done with it and it will in turn close the internal low-level client to free those resources. This can be done through the close:
client.close();
In the rest of this documentation about the Java High Level Client, the RestHighLevelClient instance will be referenced as client.
3、分析类中的方法
一定要版本一致!默认es是6.8.1,要改成与本地一致的。
<properties>
<java.version>1.8java.version>
<elasticsearch.version>7.6.1elasticsearch.version>
properties>
Java配置类
@Configuration //xml
public class EsConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"))); //妈的被这个端口搞了
return client;
}
}
6.2 索引API操作
1、创建索引
@SpringBootTest
class EsApplicationTests {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient restHighLevelClient;
//创建索引的创建 Request
@Test
void testCreateIndex() throws IOException {
//1.创建索引请求
CreateIndexRequest request = new CreateIndexRequest("索引名");
//2.执行创建请求 indices 请求后获得响应
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
}
2、获取索引
@Test
void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("索引名");
boolean exist =restHighLevelClient.indices().exists(request,RequestOptions.DEFAULT);
System.out.println(exist);
}
3、删除索引
@Test
void deleteIndex() throws IOException{
DeleteIndexRequest requset = new DeleteIndexRequest("索引名");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(requset, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
6.3 文档API操作
1、测试添加文档
//测试添加文档
@Test
void testAddDocument() throws IOException {
//创建对象
User user = new User("psz", 22);
IndexRequest request = new IndexRequest("ppp");
//规则 PUT /ppp/_doc/1
request.id("1");
request.timeout(timeValueSeconds(1));
//数据放入请求
IndexRequest source = request.source(JSON.toJSONString(user), XContentType.JSON);
//客户端发送请求,获取响应结果
IndexResponse indexResponse = restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status());
}
2、获取文档
//获取文档,判断是否存在 GET /index/doc/1
@Test
void testIsExists() throws IOException {
GetRequest getRequest = new GetRequest("ppp", "1");
//过滤,不放回_source上下文
getRequest.fetchSourceContext(new FetchSourceContext(false));
getRequest.storedFields("_none_");
boolean exists = restHighLevelClient.exists(getRequest, RequestOptions.DEFAULT);
System.out.println(exists);
}
3、获取文档信息
//获取文档信息
@Test
void getDocument() throws IOException {
GetRequest getRequest = new GetRequest("ppp", "1");
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());
System.out.println(getResponse);
}
==============输出==========================
{"age":22,"name":"psz"}
{"_index":"ppp","_type":"_doc","_id":"1","_version":2,"_seq_no":1,"_primary_term":1,"found":true,"_source":{"age":22,"name":"psz"}}
4、更新文档信息
//更新文档信息
@Test
void updateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("ppp","1");
updateRequest.timeout("1s");
//json格式传入对象
User user=new User("新名字",21);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
//请求,得到响应
UpdateResponse updateResponse = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse);
}
5、删除文档信息
//删除文档信息
@Test
void deleteDocument() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("ppp","1");
deleteRequest.timeout("1s");
DeleteResponse deleteResponse = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
System.out.println(deleteResponse);
}
6.4 批量操作Bulk
- 真实项目中,肯定用到大批量查询
@Test
void testBulkRequest() throws IOException{
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");//数据量大的时候,秒数可以增加
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("psz",11));
userList.add(new User("psz2",12));
userList.add(new User("psz3",13));
userList.add(new User("psz4",14));
userList.add(new User("psz5",15));
for (int i = 0; i < userList.size(); i++) {
bulkRequest.add(
new IndexRequest("ppp")
.id(""+(i+1))
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
//请求+获得响应
BulkResponse bulkResponse = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulkResponse.hasFailures());//返回false:成功
}
6.5 搜索
/*
查询:
搜索请求:SearchRequest
条件构造:SearchSourceBuilder
*/
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("ppp");
//构建搜索条件
SearchSourceBuilder searchSourceBuilderBuilder = new SearchSourceBuilder();
// 查询条件QueryBuilders工具
// :比如:精确查询
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "psz");
searchSourceBuilderBuilder.query(termQueryBuilder);
//设置查询时间
searchSourceBuilderBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
//设置高亮
//searchSourceBuilderBuilder.highlighter()
searchRequest.source(searchSourceBuilderBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
}