Spark-Streaming实时数据分析
1.Spark Streaming功能介绍
1)定义
Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams

2.NC服务安装并运行Spark Streaming
1)在线安装nc命令
- rpm –ivh nc-1.84-22.el6.x86_64.rpm(优先选择)
#安装
上传nc-1.84-22.el6.x86_64.rpm包到software目录,再安装
[kfk@bigdata-pro02 softwares]$ sudo rpm -ivh nc-1.84-22.el6.x86_64.rpm
Preparing... ########################################### [100%]
1:nc ########################################### [100%]
[kfk@bigdata-pro02 softwares]$ which nc
/usr/bin/n#启动
nc -lk 9999(类似于一个接收器)启动之后在下边可以进行数据输入,然后就能够从spark端进行词频统计(如2)所示)
- yum install -y nc
2)运行Spark Streaming 的WordCount
bin/run-example --master local[2] streaming.NetworkWordCount localhost 9999#数据输入
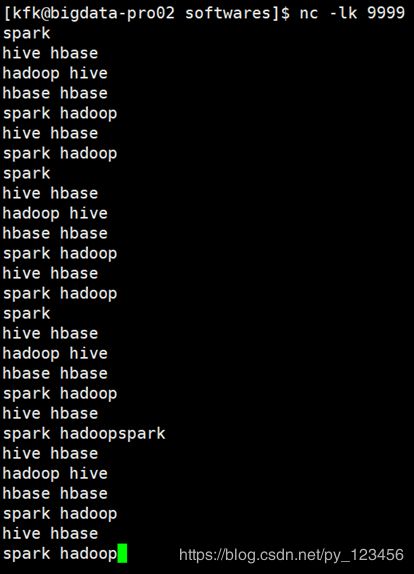
#结果统计
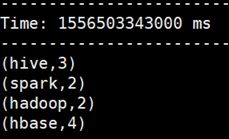
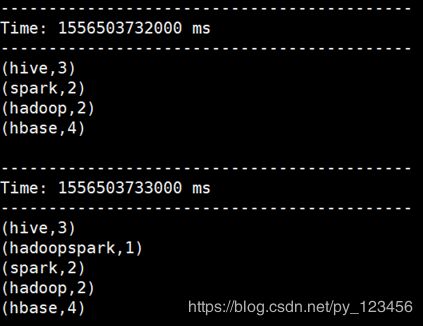
注:把日志级别调整为WARN才能出现以上效果,否则会被日志覆盖,影响观察
3)把文件通过管道作为nc的输入,然后观察spark Streaming计算结果
cat test.txt | nc -lk 9999文件具体内容
hadoop storm spark
hbase spark flume
spark dajiangtai spark
hdfs mapreduce spark
hive hdfs solr
spark flink storm
hbase storm es3.Spark Streaming工作原理
1)Spark Streaming数据流处理
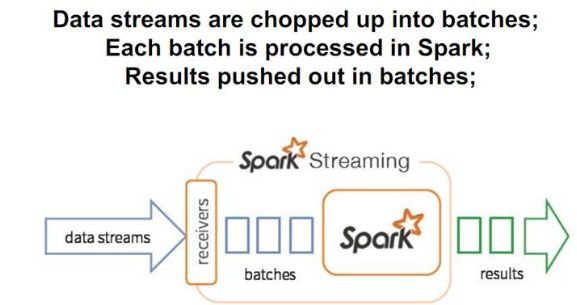
2)接收器工作原理
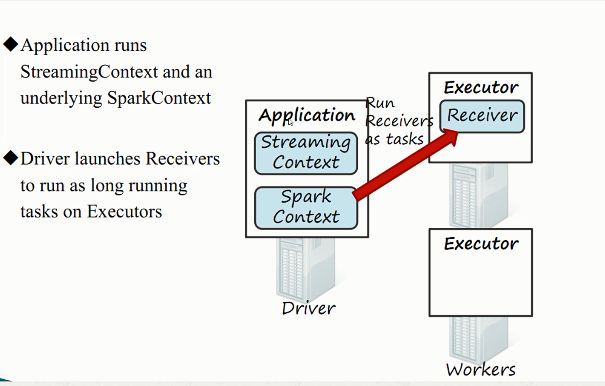
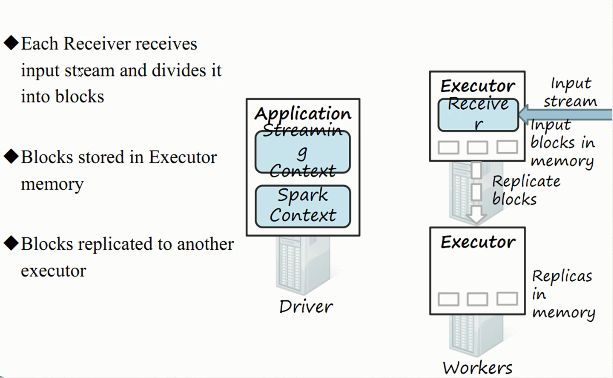

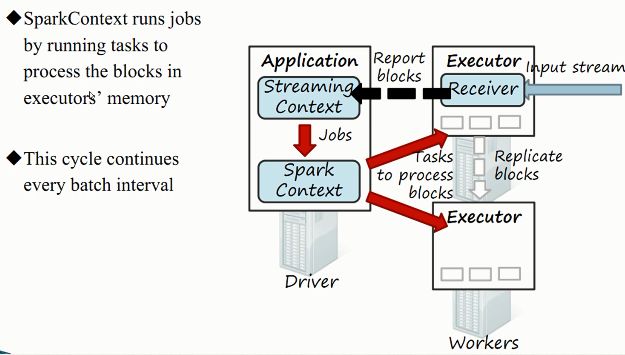
3)综合工作原理
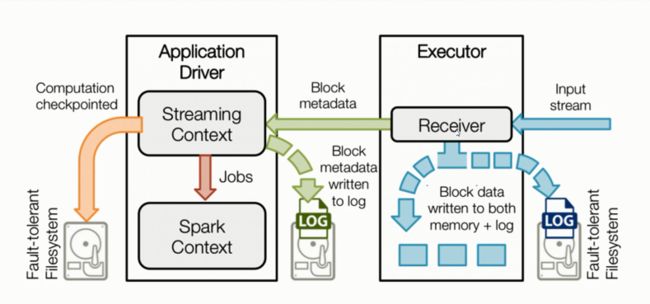
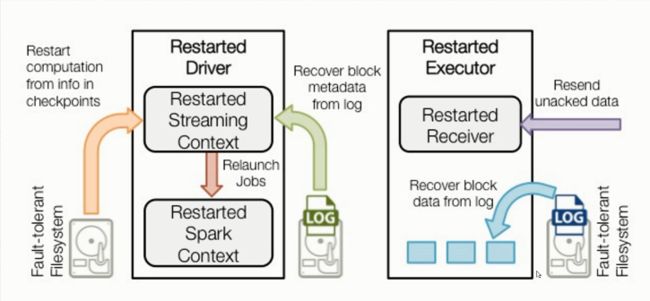
4.Spark Streaming编程模型
1)StreamingContext初始化的两种方式
#第一种
val ssc = new StreamingContext(sc, Seconds(5))#第二种
val conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount")
val ssc = new StreamingContext(conf, Seconds(1))2)集群测试
#启动spark
bin/spark-shell --master local[2]
scala> :paste
// Entering paste mode (ctrl-D to finish)
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
val ssc = new StreamingContext(sc, Seconds(5))
val lines = ssc.socketTextStream("localhost", 9999)
val words = lines.flatMap(_.split(" "))
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
wordCounts.print()
ssc.start()
ssc.awaitTermination()
// Exiting paste mode, now interpreting.
#在nc服务器端输入数据
spark
hive hbase
hadoop hive
hbase hbase
spark hadoop
hive hbase
spark Hadoop#结果统计

5.Spark Streaming读取Socket流数据
1)spark-shell运行Streaming程序,要么线程数大于1,要么基于集群。
bin/spark-shell --master local[2]
bin/spark-shell --master spark://bigdata-pro01.kfk.com:70772)spark 运行模式

3)Spark Streaming读取Socket流数据
a)编写测试代码,并本地运行

TestStreaming.scala
package com.zimo.spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
*
* @author Zimo
* @date 2019/4/29
*
*/
object TestStreaming {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.master("local[2]")
.appName("streaming")
.getOrCreate()
val sc = spark.sparkContext
//监听网络端口,参数一:hostname 参数二:port 参数三:存储级别,创建了lines流
val ssc = new StreamingContext(spark.sparkContext, Seconds(5))
val lines = ssc.socketTextStream("bigdata-pro02.kfk.com", 9999)
val words = lines.flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
words.print()
ssc.start()
ssc.awaitTermination()
}
}b)启动nc服务发送数据
nc -lk 9999
spark hadoop
spark hadoop
hive hbase
spark hadoop6.Spark Streaming保存数据到外部系统
1)保存到mysql数据库
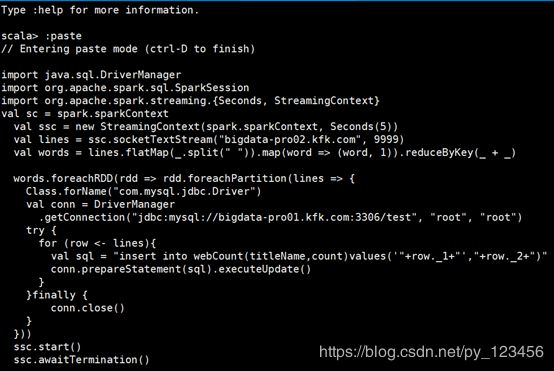
import java.sql.DriverManager
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.{Seconds, StreamingContext}
val sc = spark.sparkContext
val ssc = new StreamingContext(spark.sparkContext, Seconds(5))
val lines = ssc.socketTextStream("bigdata-pro02.kfk.com", 9999)
val words = lines.flatMap(_.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
words.foreachRDD(rdd => rdd.foreachPartition(lines => {
Class.forName("com.mysql.jdbc.Driver")
val conn = DriverManager
.getConnection("jdbc:mysql://bigdata-pro01.kfk.com:3306/test", "root", "root")
try {
for (row <- lines){
val sql = "insert into webCount(titleName,count)values('"+row._1+"',"+row._2+")"
conn.prepareStatement(sql).executeUpdate()
}
}finally {
conn.close()
}
}))
ssc.start()
ssc.awaitTermination()然后在nc服务器端输入数据,统计结果则会写入数据库内的webCount表中。
mysql> select * from webCount;
+-----------+-------+
| titleName | count |
+-----------+-------+
| hive | 4 |
| spark | 4 |
| hadoop | 4 |
| hbase | 5 |
+-----------+-------+
4 rows in set (0.00 sec2)保存到hdfs
这种方法相比于写入数据库则更简单了,感兴趣的请参考下面代码自行测试一下。
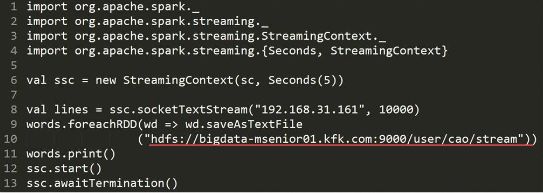
特别说明:每次执行,HDFS文件内容都会被重置覆盖!
7.Structured Streaming 编程模型
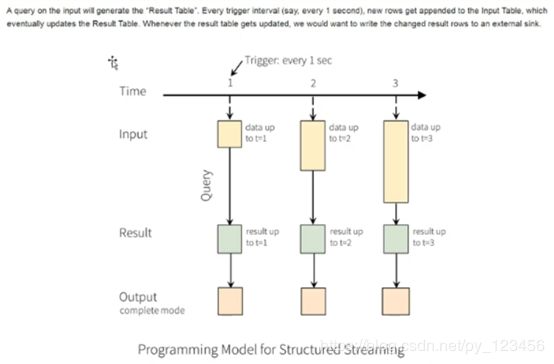

1)complete输出模式
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
import spark.implicits._
val lines = spark.readStream
.format("socket")
.option("host", "bigdata-pro02.kfk.com")
.option("port", 9999)
.load()
val words = lines.as[String].flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
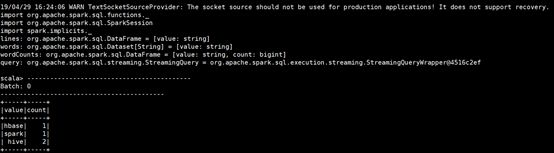
val query = wordCounts.writeStream.outputMode("complete").format("console").start()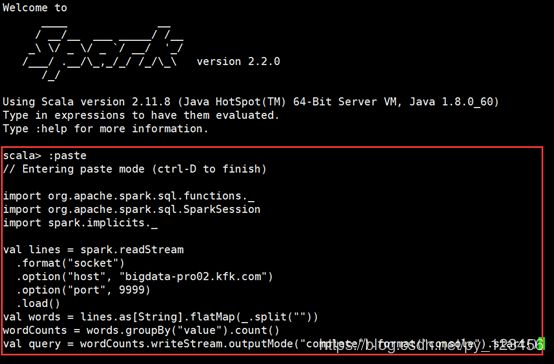

2)update输出模式
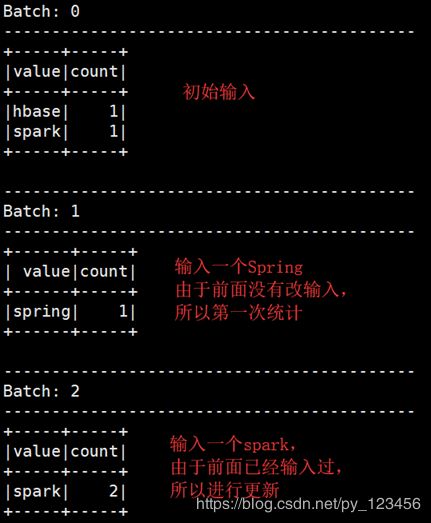
这种模式下你在nc服务器端继续输入,则会一直统计刚才输入及历史输入的值,而如果把outputMod修改为“update”,则会根据历史输入进行统计更新,并且只显示出最近一次输入value值更新后的统计结果。
3)append输出模式
把outputMod修改为“append”的话代码也要有一点小小的修改
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
import spark.implicits._
val lines = spark.readStream
.format("socket")
.option("host", "bigdata-pro02.kfk.com")
.option("port", 9999)
.load()
val words = lines.as[String].flatMap(_.split(" ")).map(x => (x, 1))
val query = words.writeStream.outputMode("append").format("console").start()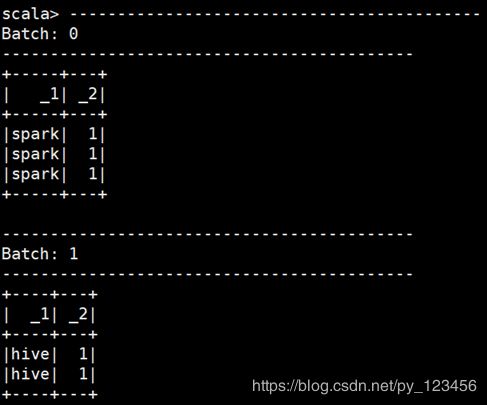
可以看出,这种模式只是把每次输入进行简单追加而已。
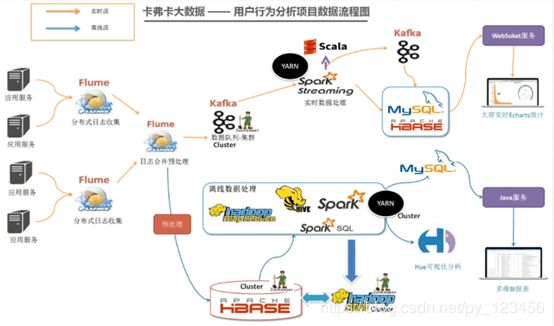
8.实时数据处理业务分析
9.Spark Streaming与Kafka集成
1)准备工作
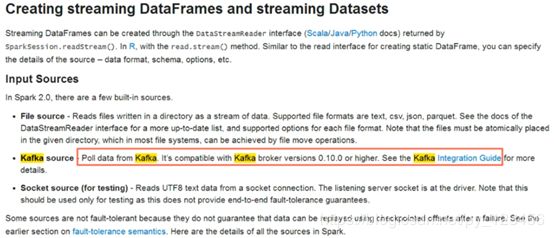
根据官网要求,我们之前的kafka的版本低了,需要下载一个至少0.10.0版本的。
下载地址 http://kafka.apache.org/downloads
修改配置很简单,只需要把我们原来配置的/config文件夹复制过来替换即可,并按照原来的配置新建kafka-logs和logs文件夹。然后,将配置文件夹中路径修改掉即可。
2)编写测试代码并启动运行
我们把包上传上来(3个节点都这样做)
启动spark-shell
把代码拷贝进来
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "bigdata-pro01.kfk.com:9092")
.option("subscribe", "weblogs")
.load()
import spark.implicits._
val lines= df.selectExpr("CAST(value AS STRING)").as[String]
val words = lines.flatMap(_.split(" "))
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream
.outputMode("update")
.format("console")
.start()
query.awaitTermination()这个时候一定要保持kafka和生产者是开启的:
bin/kafka-console-producer.sh --broker-list bigdata-pro01.kfk.com:9092 --topic weblog在生产者这边输入几个单词
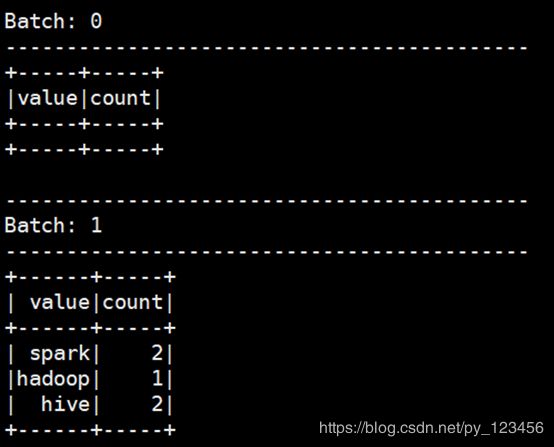
回到spark-shell界面可以看到统计结果
10. 基于结构化流完成数据实时分析
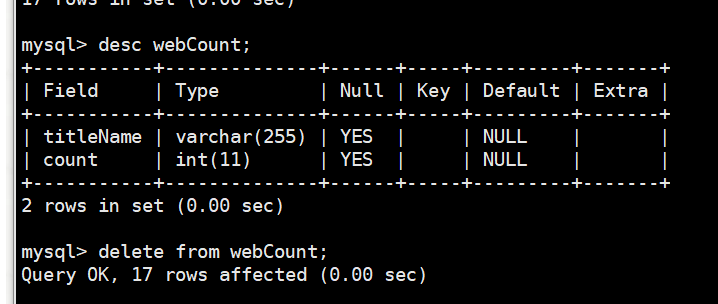
我们先把mysqld的test数据库的webCount的表的内容清除
打开idea,我们编写两个程序
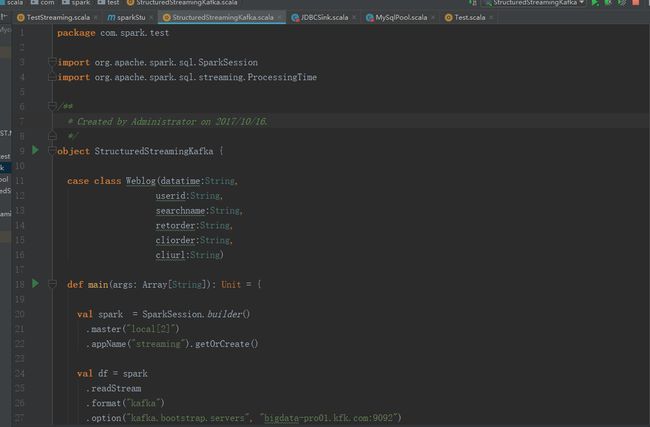

package com.spark.test
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.ProcessingTime
/**
* Created by Zimo on 2017/10/16.
*/
object StructuredStreamingKafka {
case class Weblog(datatime:String,
userid:String,
searchname:String,
retorder:String,
cliorder:String,
cliurl:String)
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.master("local[2]")
.appName("streaming").getOrCreate()
val df = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "bigdata-pro01.kfk.com:9092")
.option("subscribe", "weblogs")
.load()
import spark.implicits._
val lines = df.selectExpr("CAST(value AS STRING)").as[String]
val weblog = lines.map(_.split(","))
.map(x => Weblog(x(0), x(1), x(2),x(3),x(4),x(5)))
val titleCount = weblog
.groupBy("searchname").count().toDF("titleName","count")
val url ="jdbc:mysql://bigdata-pro01.kfk.com:3306/test"
val username="root"
val password="root"
val writer = new JDBCSink(url,username,password)
val query = titleCount.writeStream
.foreach(writer)
.outputMode("update")
//.format("console")
.trigger(ProcessingTime("5 seconds"))
.start()
query.awaitTermination()
}
}package com.spark.test
import java.sql._
import java.sql.{Connection, DriverManager}
import org.apache.spark.sql.{ForeachWriter, Row}
/**
* Created by Zimo on 2017/10/17.
*/
class JDBCSink(url:String, username:String,password:String) extends ForeachWriter[Row]{
var statement : Statement =_
var resultSet : ResultSet =_
var connection : Connection=_
override def open(partitionId: Long, version: Long): Boolean = {
Class.forName("com.mysql.jdbc.Driver")
// connection = new MySqlPool(url,username,password).getJdbcConn();
connection = DriverManager.getConnection(url,username,password);
statement = connection.createStatement()
return true
}
override def process(value: Row): Unit = {
val titleName = value.getAs[String]("titleName").replaceAll("[\\[\\]]","")
val count = value.getAs[Long]("count");
val querySql = "select 1 from webCount " +
"where titleName = '"+titleName+"'"
val updateSql = "update webCount set " +
"count = "+count+" where titleName = '"+titleName+"'"
val insertSql = "insert into webCount(titleName,count)" +
"values('"+titleName+"',"+count+")"
try{
var resultSet = statement.executeQuery(querySql)
if(resultSet.next()){
statement.executeUpdate(updateSql)
}else{
statement.execute(insertSql)
}
}catch {
case ex: SQLException => {
println("SQLException")
}
case ex: Exception => {
println("Exception")
}
case ex: RuntimeException => {
println("RuntimeException")
}
case ex: Throwable => {
println("Throwable")
}
}
}
override def close(errorOrNull: Throwable): Unit = {
// if(resultSet.wasNull()){
// resultSet.close()
// }
if(statement==null){
statement.close()
}
if(connection==null){
connection.close()
}
}
}
在pom.xml文件里添加这个依赖包
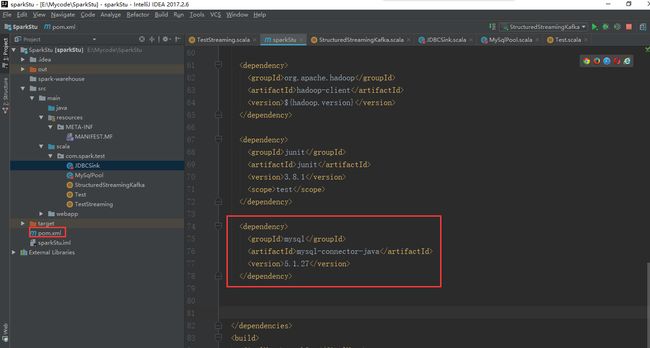
mysql
mysql-connector-java
5.1.27
我在这里说一下这个依赖包版本的选择上最好要跟你集群里面的依赖包版本一样,不然可能会报错的,可以参考hive里的Lib路径下的版本。
保持集群的dfs,hbase,yarn,zookeeper,都是启动的状态

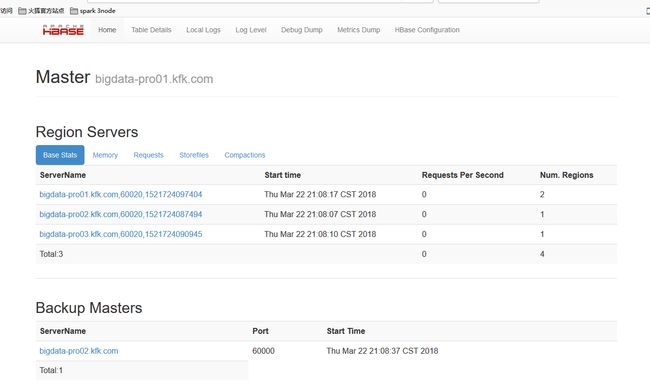
启动我们节点1和节点2的flume,在启动之前我们先修改一下flume的配置,因为我们把jdk版本和kafka版本后面更换了,所以我们要修改配置文件(3个节点的都改)
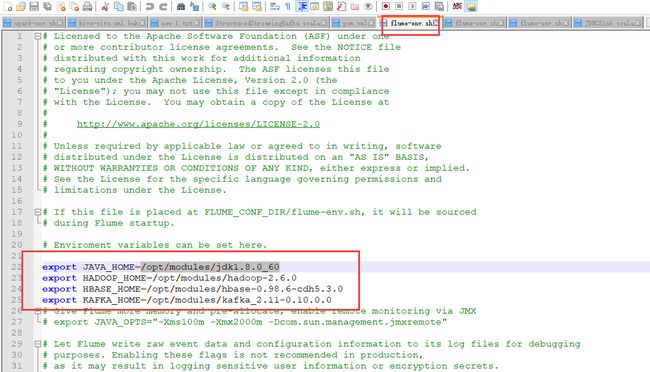
启动节点1的flume
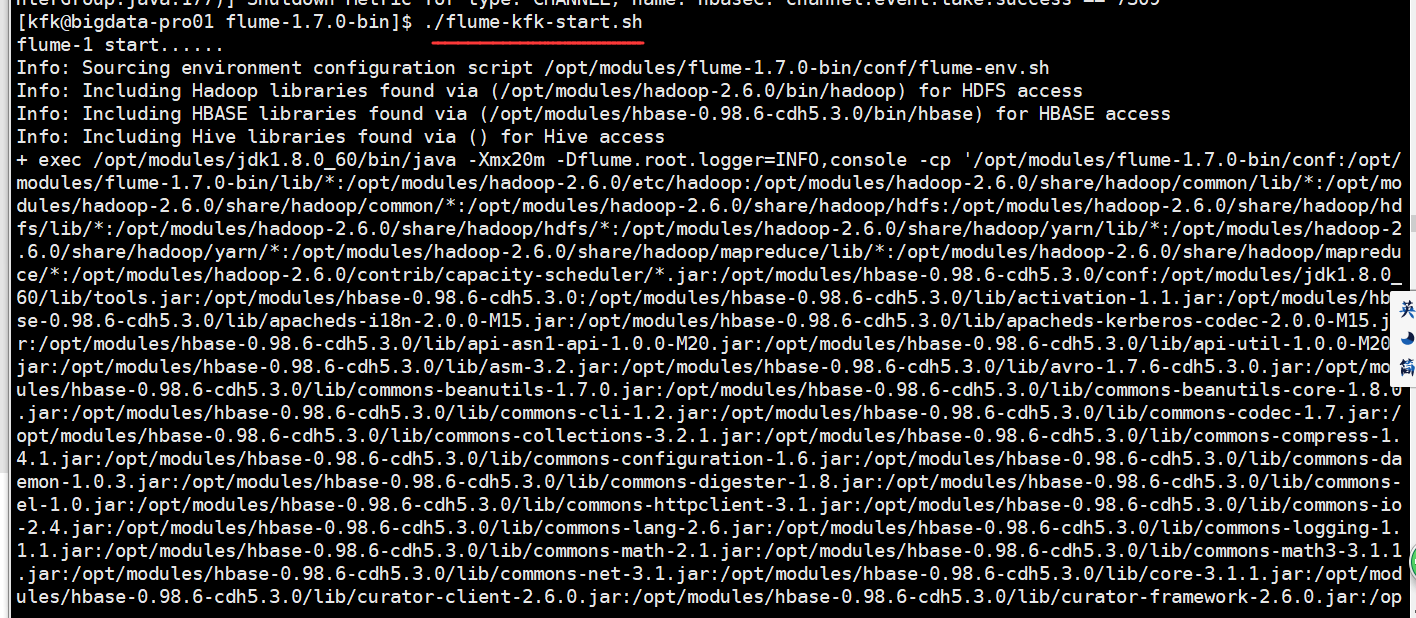
启动节点1的kafka
bin/kafka-server-start.sh config/server.properties
启动节点2的flume
在节点2上把数据启动起来,实时产生数据
回到idea我们把程序运行一下
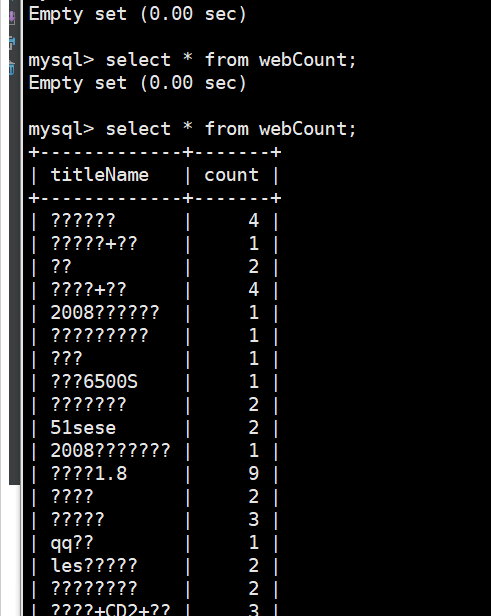
回到mysql里面查看webCount表,已经有数据进来了
我们把配置文件修改如下


[client]
socket=/var/lib/mysql/mysql.sock
default-character-set=utf8
[mysqld]
character-set-server=utf8
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
[mysql]
default-character-set=utf8
[mysqld_safe]
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
把表删除了

重新创建表
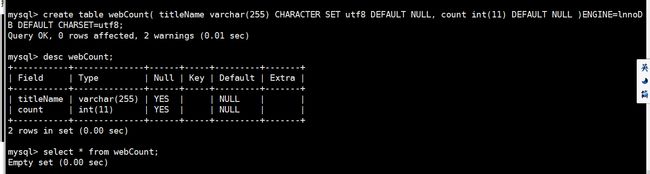
create table webCount( titleName varchar(255) CHARACTER SET utf8 DEFAULT NULL, count int(11) DEFAULT NULL )ENGINE=lnnoDB DEFAULT CHARSET=utf8;重新在运行一次程序

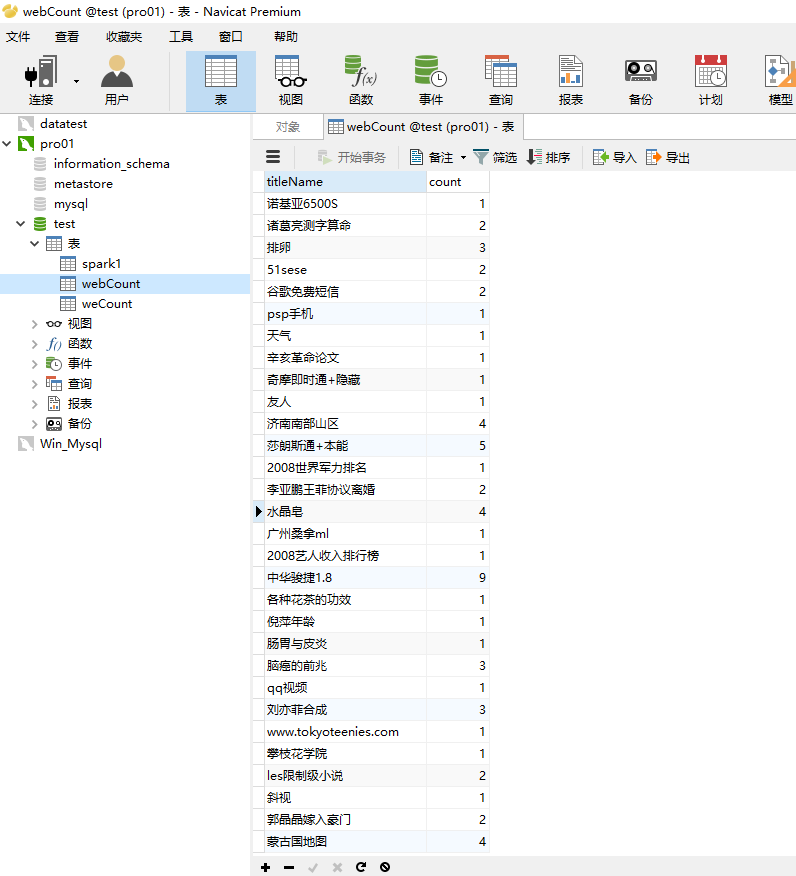
可以看到没有中文乱码了,同时我们也可以通过可视化工具连接mysql查看
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!同时也欢迎转载,但必须在博文明显位置标注原文地址,解释权归博主所有!