HtmlUnit java爬虫入门 真实案例讲解 爬取电商网站数据
最近利用空闲时间帮朋友做了个爬取几个电商网站的数据的小程序 使用的是htmlUnit 自我感觉htmlUnit爬取的速度和稳定性还是很不错的 所以写一篇博文介绍下htmlUnit的使用相关 也算记录一下
这是该网站的主页面
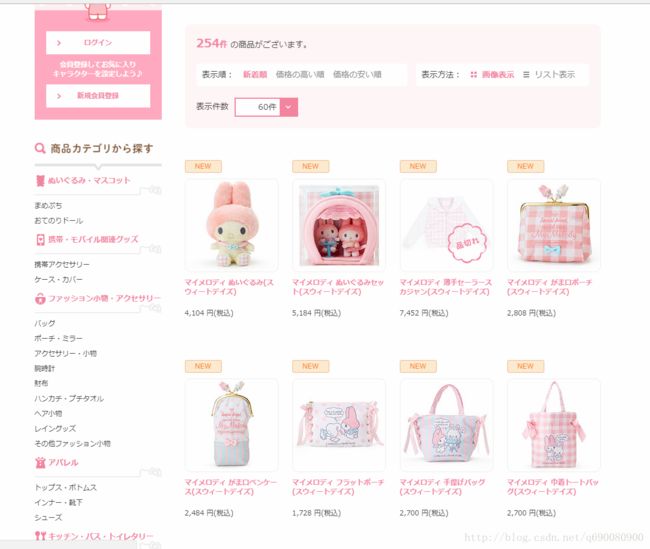
具体的思路是 获取商品所在的div 通过div获取每个商品的标签的href 进入该网址 爬取该商品的数据 然后导出EXCEL表 实现自动翻译等功能
1.首先 我们需要获取主页面的数据
WebClient webClient = new WebClient(BrowserVersion.CHROME );//模拟创建打开一个谷歌浏览器窗口
webClient.getOptions().setTimeout(15000);//设置网页响应时间
webClient.getOptions().setUseInsecureSSL(true);//是否
webClient.getOptions().setRedirectEnabled(true);//是否自动加载重定向
webClient.getOptions().setThrowExceptionOnScriptError(false);//是否抛出页面javascript错误
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//是否抛出response的错误
webClient.getOptions().setJavaScriptEnabled(false);// HtmlUnit对JavaScript的支持不好,关闭之
webClient.getOptions().setCssEnabled(false);// HtmlUnit对CSS的支持不好,关闭之
String url = "https://shop.sanrio.co.jp/products/list.php?product_status=1";
HtmlPage page = webClient.getPage(url);//通过url获取整个页面
通过查看page对象的方法 能发现 它可以像在写JS一样的操作页面上的元素
2.查看页面源代码 获取商品对应的div中的A标签 (缩放过的图片 可以右键查看原图)
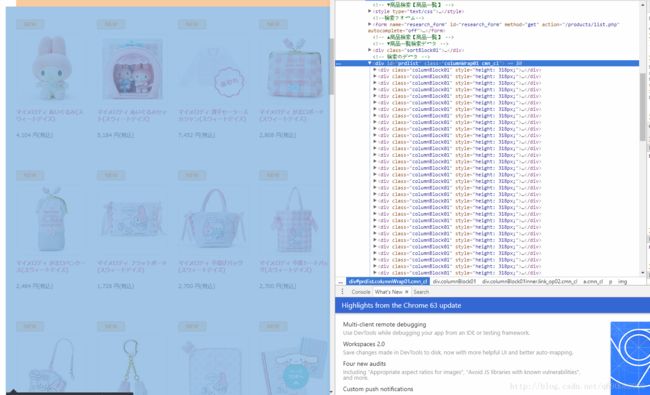
由此可发现 商品均是嵌套在一个 id="prdlist" 的div中 那么我们可以通过
// 获取A标签的div
HtmlDivision element = (HtmlDivision) page.getHtmlElementById("prdlist"); 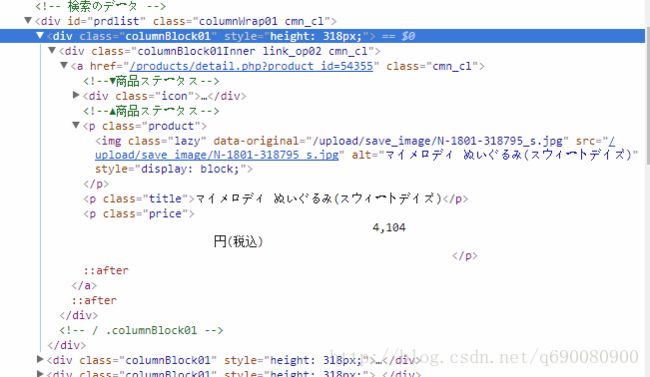
这就是每个独立的商品div 所对应的源码了 我们能看到 每个商品的div中 只有一个A标签 那么 我们只要获取到该A标签就Ok
DomNodeList list = element.getElementsByTagName("a"); // 获取页面上的所有A连接(商品标签)
out2: for (HtmlElement htmlElement : list) {
HtmlPage click = htmlElement.click(); // 进入商品页面
HtmlDivision div3 = (HtmlDivision) click.getByXPath("//div[@class='box_right_summary']").get(0); // 获得名字的div
}
htmlunit 中自带的基本包含了所有html的标签 如 HtmlInput HtmlTable HtmlSpan 等等等等 读者可以下载一个jar自己试试
另外XPath的语法使用可以参照这篇文章 Xpath语法
另外htmlunit还可以模拟表单的提交 就使用htmlElement的click()方法 获取表单的输入框 然后设置值 模拟点击事件
// 获取首页
final HtmlPage page1 = (HtmlPage) webClient.getPage("http://htmlunit.sourceforge.net");
// 根据form的名字获取页面表单,也可以通过索引来获取:page.getForms().get(0)
final HtmlForm form = page1.getFormByName("myform");
final HtmlSubmitInput button
= (HtmlSubmitInput) form.getInputByName("submitbutton");
final HtmlTextInput textField
= (HtmlTextInput) form.getInputByName("userid");
// 设置表单域的值
textField.setValueAttribute("root");
// 提交表单,返回提交表单后跳转的页面
final HtmlPage page2 = (HtmlPage) button.click();3.接下来进入到商品详情页面 获取商品信息
 这就是商品详情页面 我们需要获取到它的名称 尺寸 图片 价格 简介等
这就是商品详情页面 我们需要获取到它的名称 尺寸 图片 价格 简介等
然后观察源码
 这个div可以获得到名称 价格
这个div可以获得到名称 价格
HtmlDivision div3 = (HtmlDivision) click.getByXPath(
"//div[@class='box_right_summary']").get(0); // 获得名字的div
String name = div3.getElementsByTagName("h2").get(0).asText();
excels.setJname(name); // 设置日本名字 (这是自己创建的导出EXCEL的实体类)
// 获取商品的价格信息
HtmlSpan span = (HtmlSpan) click.getByXPath("//span[@class='priceSelect']").get(0);
String cname = getCname(name); // 通过百度翻译接口获取中文名字
excels.setCname(cname);

如图 可发现
// 获取商品的详细信息
HtmlDivision div2 = (HtmlDivision) click.getByXPath(
"//div[@class='productSummary accordionBlock01']").get(
0);
DomNodeList ths = div2.getElementsByTagName("tr");
for (HtmlElement th : ths) {
if (th.getElementsByTagName("th").get(0).asText().equals("サイズ")) {
String sizeString = th.getElementsByTagName("td")
.get(0).asText();
// 设置商品尺寸
excels.setSize(sizeString);
}
if (th.getElementsByTagName("th").get(0).asText().equals("商品コード")) {
// 商品编号
String nums2 = th.getElementsByTagName("td").get(0)
.asText();
// 设置商品编号
excels.setNums2(nums2);
}
} 接下来是获取商品的图片信息
HtmlDivision div = (HtmlDivision) click.getByXPath(
"//div[@class='box_pic']").get(0);
// System.out.println(div.asXml());
DomNodeList imgs = div.getElementsByTagName("img");
// 遍历 下载图片到本地
for (HtmlElement img : imgs) {
download(SANLIOU + img.getAttribute("src"), DOWNDS
+ filename + "/");//这是自己封装的下载图片的方法
} 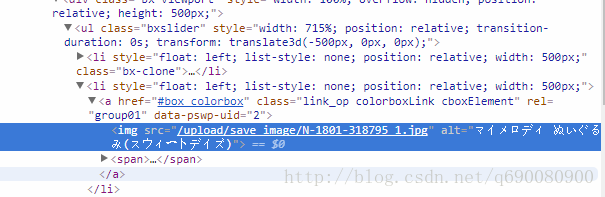 这是商品的图片img src就不是完整的
这是商品的图片img src就不是完整的
而该网页的地址是 :https://shop.sanrio.co.jp/products/detail.php?product_id=54355
我们就截取 https://shop.sanrio.co.jp 这就是该网站的根路径 再加上/upload/save_image/N-1801-318795_1.jpg 就组成了图片的真实路径
至此大致的爬取内容就完成了 详细的项目案例我上传到了我的CSDN上 大家可以去下载看看 案例下载
其实htmlunit是一个很简单的小框架 很好学 只要有前端页面的基础 很容易就能入门实现自己想要的功能