漫谈大数据反欺诈技术架构
一年多以前,有朋友让我聊一下你们的大数据反欺诈架构是怎么实现的,以及我们途中踩了哪些坑,怎么做到从30min延迟优化到1s内完成实时反欺诈。当时呢第一是觉得不合适,第二也是觉得场景比较局限没什么分享的必要性。
时间也过了很久了,最近看到圈里一些东西,发现当时的这套架构并未落伍,依然具有很大的参考价值,所以今天跟大伙聊聊关于大数据反欺诈体系怎么搭建,主要来源是来自于我工作的时候的实践,以及跟行业里的很多大佬交流的实践,算是集小成的一个比较好的实践。
这套架构我做的时候主要领域是信贷行业的大数据反欺诈,后来也看过电商的架构,也看过金融大数据的架构,发现其实大家使用的其实也差不多是这个套路,只是在各个环节都有不同的细节。
大佬说的,能用图的,尽量不要打字,那我就打少点字,多做点图。其实大数据不外乎这么几个步骤。数据源开拓、数据抽取、数据存储、数据清洗和处理、数据应用,且听我一个一个说。
数据源

数据源是一个比较重要的点,毕竟如果连数据源都是垃圾,那么毫无疑问可以预见,最终产出的一定是垃圾,所以挑选数据源和对接数据源的时候都要关注,该机构产出的数据是不是都是质量比较高的数据。
比如人行征信数据就是一个质量非常非常高的数据,主要涉及信用卡、银行流水、老赖、失信、强制执行信息等,都非常核心,任何一个点都可能是一笔坏账的苗头。以及各种行政机构提供的付费机密数据。
比如运营商通讯数据、比如大型电商的行为数据、比如各种保险数据,以及各个机构贷款记录的互相沟通,这些数据源,都非常核心也都非常值钱,是现在反欺诈非常核心的数据。
当然也有更加粗暴更加高效的做法,就是直接购买外部的黑名单数据,这让反欺诈变得更加简单,遇到就直接拒,可以减少非常的人力物力成本去做其他的核查。
数据抽取
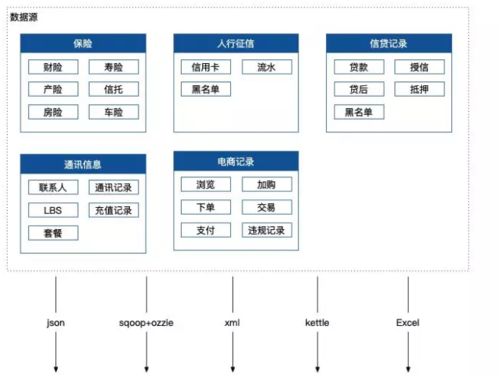
有了高质量的数据源后,当然就是怎么抽取的问题了,各个机构所提供的数据格式是多种多样的,其中包括 http 接口的json、xml,内部其他数据源的 etl、定时人工上报的 Excel,以及 sqoop+ozzie 这两个直接数据抽取通道,这个过程只需要保证通道稳定,数据服务幂等即可,没什么特殊的地方。
数据存储

数据存储其实就是建立一个数据仓库和一个实时仓库,数据仓库用于存储来自各大数据源的原始数据,实时仓库用于业务系统的核心作业,数据仓库的数据量一般都以 T 为单位,实时仓库以 M 和 G 为单位。
离线计算实时计算
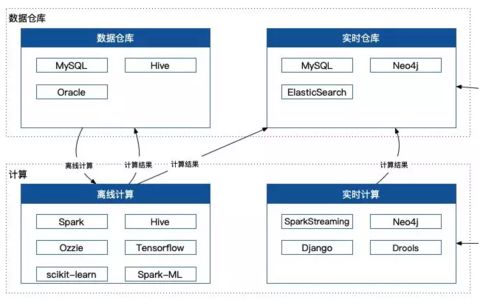
数据保证了,那么计算就是这套架构的核心之处,从大的角度来看可以分成离线计算和实时计算。
离线计算主要会做两件事情。Hive 、Spark 数据整合与清洗和离线数据建模。Hive 数据整合主要做的事情就是把各个数据库里面的东西,进行清洗和过滤,最终写到我们定义的标准表里边,提供给下游的计算使用。如果是非常复杂的数据清洗,我们会使用 Spark 写程序来做,毕竟有一些操作不是 Hive 这种标准 SQL 能解决的。离线数据建模,就是对于这批数据进行建模,以便后续用于实时计算和应用中,算法嘛,精通两个基本就稳了,LogisticRegression 决策树,不要问我为什么。
实时计算又会做些什么事情?SparkStreaming和Flink用于实时流计算,主要是用于一些统计类的事情,以及多个数据流的 join 操作。在这里我们希望做到什么事情呢?就是希望服务可以准实时,什么叫准实时呢?就是在一个可以接受的范围内,我允许你有一定的延迟,这块我们一开始的任务延迟是 30 min。
我们踩过哪些坑呢?
一开始我们希望使用流批次计算来实现实时计算,实践下来准实时跟实时还是区别很大的,一个业务通常是允许不了分钟级别的延迟的,然而 Spark 的 GraphX 必然有分钟级别的延迟,只适合离线计算。
Hive + Ozzie 处理离线批量处理是一个非常大的利器,很多人都以为Hive数据清洗不就写写几行 SQL?几百张乃至几千张表背后的复杂的数据清洗规则,任务依赖,任务重跑,数据质量,数据血缘关系维护。相信我,要是没有细心和工具,这些能把你搞崩溃。
ElasticSearch 集群多个机器的负载吞吐量,比单台机器高性能的要高,毕竟网络卡在那。
我们趟了很多的坑,摸了很多的时候,最终决定把所有的实时操作都架构在 ElasticSearch 和 Neo4j 上,因为我们不仅仅需要实时的全文本全字段社交关系生成,更是需要实时搜索多维度多层社交关系并反欺诈分析,而这个关系可能是百万级别的,根据六度理论,决定了我们选取的层次不能太多,所以最终我们只抽取其中三层社交关系。最终确定这个架构,这很核心地确定了我们的响应时间,并最终决定了我们服务的可用性。
很多地方产生的结果数据只是整个决策链上的一个细节,所以我们还需要 Drools 这类规则引擎帮助做一个最终决策。
业务应用
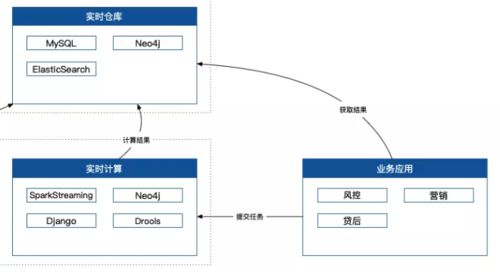
最终业务系统应该怎么使用,怎么对外提供服务?这也是一个非常核心的问题,因为这部分要求非常非常稳定,以及非常非常高效,一般来说不允许有太高的延迟,同时还要求非常高的并发量。这就要求了我们第一要尽量提高计算效率,第二要求我们对于系统的架构要有非常高的保障。
计算效率要高效,有什么技巧呢,保证各个系统之间的交互都是聚合、加工、计算后的结果,而不是原始数据,毕竟网络传输是需要很高成本的在目标数据量非常大的场景下。比如一次性要加载几十万条数据,那全部拉回来再重新计算是不是就显得很蠢了?为什么不在目标系统里以数据服务的形式提供呢?
技术架构保障,其实大部分都是基础架构的事情了,比如动态负载均衡、一主多从、异地多机房容灾、断网演练、上游服务故障预案等等。
建模之社交网络
很久以前就已经介绍了各种社区发现算法,这里就不再赘述,有兴趣的自己点进去细致了解一下。
这里聊聊一个知识图谱的标准建立过程。
1、主体确认
2、关系建立。
3、逻辑推理建立。
4、图谱检索
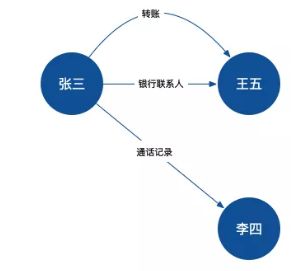
主体确认,从图的角度来看就是确认各个顶点,这些顶点有自己的属性,代表着网络里的一个个个体。
关系建立,从其他资料关系得来,也可以根据第三步的逻辑推理得来,从图的角度来看就是确认各个边,这些边有起点有终点也有自己的属性,代表着网络里各个个体的关联。
逻辑推理建立,这是非常重要的一个部分,比如姚明的老婆的母亲,就是姚明的岳母,这种先验知识的推理可以在图谱的帮助下,为我们解决很多的实际问题。
图谱检索,有了图谱我们就开始使用,我们有四件套,主体属性搜索,关系属性搜索,广度优先搜索,宽度优先搜索。我们一般的使用策略都是,优先确定一个顶点比如目标人物,然后向外扩散,直到找到所有符合条件的个体。
这里我们踩了什么坑做了什么优化呢?我们一开始是把整个搜索结果拉到本地再进行计算,而图谱搜索后的结果总是很大,毕竟我们找了很多维的关系,所以总是卡在网络这块。经过探索和咨询,最终确认了 Neo4j 这种图数据库不仅仅提供数据查询服务,还做了基于定制化的社交网络分析的插件化开发,把我们的反欺诈服务以插件化的形式部署到服务器中,这就减少了非常多的网络开销,保障了我们服务的秒级响应。
完整架构图

从数据来源、获取、存储、加工、应用,一步到位,万一有点帮助那就更好了,如果还心存疑虑,这篇文章从下往上,再看一遍。