Kafka的原理和应用分析及和RabbitMQ的对比
1. kafka是什么
Kafka 是一个分布式消息流处理平台,原本开发自 LinkedIn,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。现在它已被多家公司作为多种类型的数据管道和消息系统使用1 2。
作为一个消息处理平台,kafka主要有以下功能2:
- 发布和订阅数据流,类似于消息队列或企业级的消息分发系统
- 以容错、持久化的方式存储数据流
- 对数据流进行实时处理
- 在多个系统或应用之间建立实时的数据流管道
- 建立实时数据流应用,来对数据流传输和响应
kafka的功能示意图如图所示。

1.1 Topics
topics是一个分类,或者叫数据供给中心(feed),发布者生产数据到topics,消费者从topics消费数据。kafka的topics总是有多个消费者,即0个,1个,或多个。
kafka的功能示意图如图所示。
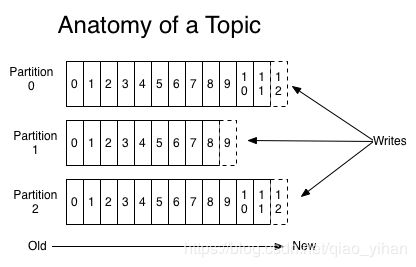
一个topic有多个分片(partition),每个分片是一个有序的数据序列,而且分片是持续增长的。分片中的每一条记录(record)有一个序号(offset),用来唯一标识该记录在分片中的位置。
Kafka集群使用一个可配置的时间周期来保存所有发布的记录,无论它们是否已经被消费。举个例子,如果保留策略设置的是两天,在数据记录发布后的两天内,它是可以被消费的,但两天后,它就会被丢弃以释放空间。
1.2 Producers 和 Consumers
生产者自己选择发布数据到相应的topics。生产者发布数据到Kafka集群的服务器(broker),一般来说,Kafka集群有多个broker,用来做负载均衡3。生产者发布数据也可以采取简单的循环方式进行负载均衡,也可以依据一定的分区策略(比如基于record中的key)。
由于broker本身是无状态的,所以需要Zookeeper来维护服务器的状态。Apache ZooKeeper是Apache软件基金会的一个软件项目,他为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册(naming)4。Kafka提供默认、简单的Zookeeper配置文件用于启动一个本地的Zookeeper实例5。Zookeeper通知生产者和消费者Kafka集群中新的服务器(broker)的出现或者某个服务器的失败。
在Kafka里把消费者按标签分成消费者组(consumer group),每一条发布到topic的记录被发送到一个消费者实例。消费者实例可以在不同的进程或不同的机器上。如果所有的消费者实例都在相同的组中,那么数据记录会以负载均衡的方式分配给消费者实例。如果消费者实例处在不同的组别中,每一个记录会被广播到所有的消费者组中的一个实例上2。如图所示。

2. Kafka的架构
下图展示了Kafka的整体架构。生产者发布消息到topic,每个topic又分成多个partition,每台服务器(broker)拥有0个或多个topic的partition。每个partition是一个有读写顺序的log文件,存储在硬盘上6。
相比于传统的 发布/订阅 系统,Kafka中的消费者可以看做是一组合作的进程。topic中的每个partition传送给消费者组中的一个消费者。因此,partition的个数是topic的并行个数,也决定了消费者的并行程度。而且,由于每个partition都有一个对应的消费者实例,消费者进程就可以被动的记下它读取的位置(根据partition中的offset),不需要在读到信息的同时就去标记它们的位置,这对于性能的提供有很大的帮助。
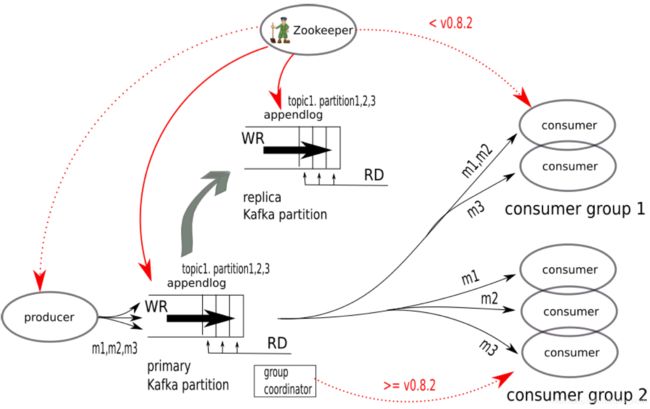
值得一提的是,在0.8.2以后的版本,Kafka的消费者摆脱了对Zookeeper的依赖,取而代之的是在broker内部的协调器。仍依赖ZooKeeper的是控制器和集群的管理、topic和partition的管理、同步数据复制(in-sync data replication)和一些静态配置(配额、ACLs)7。详细信息如下:
Kafka uses Zookeeper for the following:
- Electing a controller. The controller is one of the brokers and is responsible for maintaining the leader/follower relationship for all
the partitions. When a node shuts down, it is the controller that
tells other replicas to become partition leaders to replace the
partition leaders on the node that is going away. Zookeeper is used to
elect a controller, make sure there is only one and elect a new one it
if it crashes.- Cluster membership - which brokers are alive and part of the cluster? this is also managed through ZooKeeper.
- Topic configuration - which topics exist, how many partitions each has, where are the replicas, who is the preferred leader, what
configuration overrides are set for each topic- (0.9.0) - Quotas - how much data is each client allowed to read and write
- (0.9.0) - ACLs - who is allowed to read and write to which topic
- (old high level consumer) - Which consumer groups exist, who are their members and what is the latest offset each group got from each
partition.
3. Kafka的应用场景6 5 3
- 发布/订阅消息(Pub/Sub Messaging) 在两个条件下,使用Kafka作为发布/订阅系统比较合适:1)路由逻辑比较简单,Kafka的topic就可以处理;2)每个topic的吞吐量超过了RabbitMQ可以处理的量;
- 可扩展的数据聚合系统(Scalable Ingestion System) 许多大数据处理平台要求高吞吐量,在许多场景,如何高效加载数据到这些平台是主要的瓶颈。Kafka为这些场景提供了一个可扩展的解决方案。而且,像 Apache Spark 和 Apache Flink 等平台已经把Kafka集成在内了。
- 数据层基础设施(Data-Layer Infrastructure) 由于它的持久化和高效率的多播,Kafka可以作为底层的数据基础设施,用于连接流服务和应用。
- 捕获变化源(Capturing Change Feeds) 变化源是一系列更新事件,它捕获作用于初始状态的所有变化(如数据表或数据表中某一列的变化)。
- 流处理(Stream Processing) 流处理开始于Kafka的0.10.0版本,它是一个轻量级的数据流处理库。对于数据产生快、实时性强的数据流(股市分析、用户行为、气象监测等)可以实现在线的计算和分析。Apache Samza是一个开源的数据流处理平台,就是基于Kafka的。
典型案例:
- Twitter:用Kafka作为流处理设施。
- LinkedIn:用于活动流和运营数据。这些数据被用于新闻推送、离线分析系统等产品。
- Yahho!: Yahho的媒体分析组用作实时数据分析。
- Netflix: 作为数据收集网关,该应用每天收集十亿级别的消息。
4. 和RabbitMQ的对比
4.1 RabbitMQ架构
RabbitMQ实现和扩展了AMQP协议,默认支持AMQP 0.9.1,可以通过插件支持到AMQP 1.0。如AMQP的架构图所示,AMQP采用了模块化的方案6:
- 交换器(Exchange)。本质上是一个路由,接受消息,按照一定的规则决定把消息路由到哪个消息队列。
- 消息队列(Message Queue)。消息队列存储消息并把消息发送到消费者。

把交换器和消息队列联系起来的是绑定键(binding),它指定了交换器如何路由消息。对于一个AMQP连接,通道(channel)可以用来对消息流进行隔离。在一个多线程的环境里,一般给各个线程分配独立的channel。
4.2 使用场景对比
在第3节对Kafka的使用场景作了介绍。这里说一下RabbitMQ的最佳使用场景。
- 发布/订阅系统(Pub/Sub Messaging)。由于这就是为什么RabbitMQ被创建出来的原因,所以它满足大部分的使用需求。
- 请求-响应消息系统(Request-Response Messaging)。RabbitMQ借助 correlation id 和 reply-to 特性来实现 RPC(Remote procedure call) 形式的通信。下图可帮助理解这个过程,具体用法参考8。

- 运营数据跟踪(Operational Metrics Tracking)。RabbitMQ也是用于实时数据处理不错的选择,特别是RabbitMQ可以提供更为复杂的数据过滤和分类策略。
- 物联网应用平台的底层服务(Underlying Layer for IoT Applications Platform)。
4.3 不同的特性
4.3.1 Kafka独有的特性
- 长时间的消息存储。Kafka存储消息到硬盘上。当在配置的周期过后,或消息存储量超过topic的硬盘配额,消息才会被清除。
- 消息回放(Message Replay)。由于Kafka的消费者是无状态的,而且消息可以存储较长时间,在需要的时候,消费者可以很容易的回放消息。这对于下游的系统的容错是一个非常有用的特性。
- Kafka Connect。Kafka Connect是一个用于在Kafka和其他系统之间支持可扩展和可靠的数据流的框架。它为Kafka和其它系统创建规模可扩展的、可信赖的流数据提供了一个简单的模型,通过connectors可以将大数据从其它系统导入到Kafka中,也可以从Kafka中导出到其它系统。Kafka 0.9提供了这一特性9。下图展示了这一框架的作用。

- 日志压缩(Log Compaction)。日志压缩至少保留单个主题分区的每个记录键的最后已知值。压缩日志对于在崩溃或系统故障后恢复状态非常有用10。
4.3.2 RabbitMQ独有的特性
(1)标准协议。RabbitMQ使用了AMQP这一标准协议,这就决定了它可以很容易和其他兼容AMQP的系统一起工作,甚至比较容易替换。
(2)多协议支持。RabbitMQ支持一些工业界其他标准协议,只要有MQTT(IoT领域用的比较多)和STOMP。
(3)分布式拓扑模型(Distributed Topology Modes)。federation是rabbitmq官方提供的插件,federation插件允许我们针对exchange和queue做federation,从而形成federated exchange或者federated queue。federation插件可以在brokers或者cluster之间传输消息,连接的双方可以使用不同的users和virtual hosts,或者双方的rabbitmq和erlang的版本不一致,federation插件使用AMQP协议通讯,可以接受不连续的传输11。federation如何使用在这里12。而且,RabbitMQ也提供了另一个插件Shovel,可以方便的把brokers或clusters连接起来13。
(4)非常好用的管理和监控工具。RabbitMQ提供了好用的UI来管理和监控RabbitMQ的方方面面:(i) connections, (ii) queues, (iii) exchanges, (iv) clustering, federation and shoveling, (v) packet tracing, (vi) resource consumption6.
(5)多用户和隔离性(Multi-tenancy and Isolation)。RabbitMQ实现了AMQP的Virtual Hosts的概念,使得单个服务器可以有多个隔离的环境。
(6)跟踪消费者的状态。对于队列来说,RabbitMQ保存消费者的状态,确切的必到哪个消费者在什么时候消费了什么消息。
(7)硬盘空间的低使用量。如果不需要持久化的话,RabbitMQ不需要使用硬盘空间来路由分发数据包。这对于嵌入式的应用和资源有限制的环境来说是一个很好的选择。RabbitMQ也成功的部署在了树莓派上14。
(8)流量控制(Flow Control)。RabbitMQ 使用了一种基于 credit 的算法来限制 message 被 publish 的速率15。
(9)Message TTL. 消息可以设置一个生存时间(Time To Live),如果它超出了生存时间,将不会被发送给消费者。
4.4 Kafka和RabbitMQ的结合使用
有一些使用场合,单独使用Kafka或RabbitMQ的话不能应付,那么可以考虑把它们两个结合起来使用。
(1)RabbitMQ --> Kafka. RabbitMQ在前,Kafka在后。RabbitMQ在前可以保证低延迟性,同时以较细粒度来选择需要长时间存储的消息。
(2)Kafka -->RabbitMQ . Kafka在前,RabbitMQ在后。如果整个系统的吞吐量比较高,而对于每个topic的吞吐量需求,一个RabbitMQ的服务器又是可以处理,这样的需求可以选择这个方案。 Kafka在前,保证吞吐量,RabbitMQ在后,处理复杂的路由逻辑。
AMQP-Kafka Bridge可以实现Kafka和RabbitMQ之间的交互。
参考:
Apache kafka 工作原理介.https://www.ibm.com/developerworks/cn/opensource/os-cn-kafka/index.html ↩︎
Introduction. https://kafka.apache.org/intro ↩︎ ↩︎ ↩︎
Hiraman B R, Abhijeet C K. A Study of Apache Kafka in Big Data Stream Processing[C]//2018 International Conference on Information, Communication, Engineering and Technology (ICICET). IEEE, 2018: 1-3. ↩︎ ↩︎
Apache ZooKeeper. https://zh.wikipedia.org/wiki/Apache_ZooKeeper ↩︎
Thein K M M. Apache kafka: Next generation distributed messaging system[J]. International Journal of Scientific Engineering and Technology Research, 2014, 3(47): 9478-9483. ↩︎ ↩︎
Dobbelaere P, Esmaili K S. Kafka versus RabbitMQ: A comparative study of two industry reference publish/subscribe implementations: Industry Paper[C]//Proceedings of the 11th ACM International Conference on Distributed and Event-based Systems. ACM, 2017: 227-238. ↩︎ ↩︎ ↩︎ ↩︎
https://www.quora.com/What-is-the-actual-role-of-Zookeeper-in-Kafka-What-benefits-will-I-miss-out-on-if-I-don’t-use-Zookeeper-and-Kafka-together ↩︎
Remote procedure call (RPC). https://www.rabbitmq.com/tutorials/tutorial-six-java.html ↩︎
Kafka Connect简介. https://colobu.com/2016/02/24/kafka-connect/ ↩︎
Kafka Architecture: Log Compaction. http://cloudurable.com/blog/kafka-architecture-log-compaction/index.html ↩︎
Rabbitmq学习之路4-Federation. https://my.oschina.net/guol/blog/186436 ↩︎
Federation Plugin. https://www.rabbitmq.com/federation.html ↩︎
Shovel Plugin. https://www.rabbitmq.com/shovel.html ↩︎
T. Abarbanell. Benchmarking RabbitMQ on Raspberry Pi, 2015. URL http://blog.abarbanell.de/raspberry/2015/05/17/benchmarking-rabbitmq-on-raspberry/. ↩︎
RabbitMQ-流量控制. https://www.good21.com/2015/12/02/rabbitmq-flowcontrol/ ↩︎