大白话解读2020CVPR-GhostNet论文以及相关代码: 超越MobileNetV3的轻量级网络
大白话解读2020CVPR-GhostNet论文以及相关代码: 超越MobileNetV3的轻量级网络
华为源码
源码
为了减少神经网络的计算消耗,论文提出Ghost模块来构建高效的网络结果。该模块将原始的卷积层分成两部分,先使用更少的卷积核来生成少量内在特征图,然后通过简单的线性变化操作来进一步高效地生成ghost特征图。从实验来看,对比其它模型,GhostNet的压缩效果最好,且准确率保持也很不错,论文思想十分值得参考与学习。
论文主要有两个贡献:
(1)提出能用更少参数提取更多特征的Ghost模块,首先使用输出很少的原始卷积操作(非卷积层操作)进行输出,再对输出使用一系列简单的线性操作来生成更多的特征。这样,不用改变其输出的特征图,Ghost模块的整体的参数量和计算量就已经降低了
(2)基于Ghost模块提出GhostNet,将原始的卷积层替换为Ghost模块
为什么有这个想法?
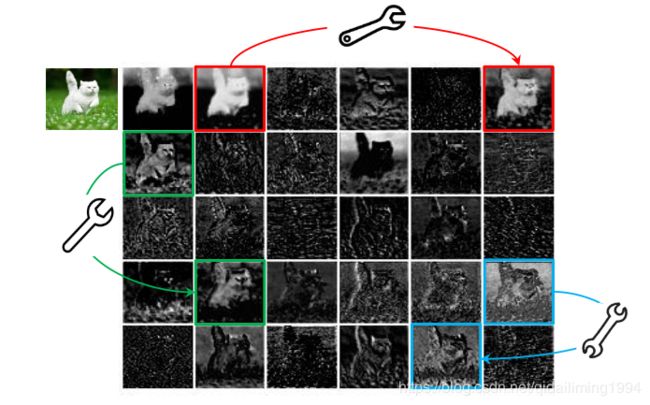
如上图所示,ResNet-50中,将经过第一个残差块处理后的特征图,会有出现很多相似的“特征图对”——它们用相同颜色的框注释。
这样操作,虽然能实现较好的性能,但要更多的计算资源驱动大量的卷积层,来处理这些特征图。
“特征图对”中的一个特征图,可以通过廉价操作(上图中的扳手)将另一特征图变换而获得,则可以认为其中一个特征图是另一个的“幻影”。
这是不是意味着,并非所有特征图都要用卷积操作来得到?“幻影”特征图,也可以用更廉价的操作来生成?
于是就有GhostNet的基础——Ghost模块,用更少的参数,生成与普通卷积层相同数量的特征图,其需要的算力资源,要比普通卷积层要低,集成到现有设计好的神经网络结构中,则能够降低计算成本。
1.Ghost模块
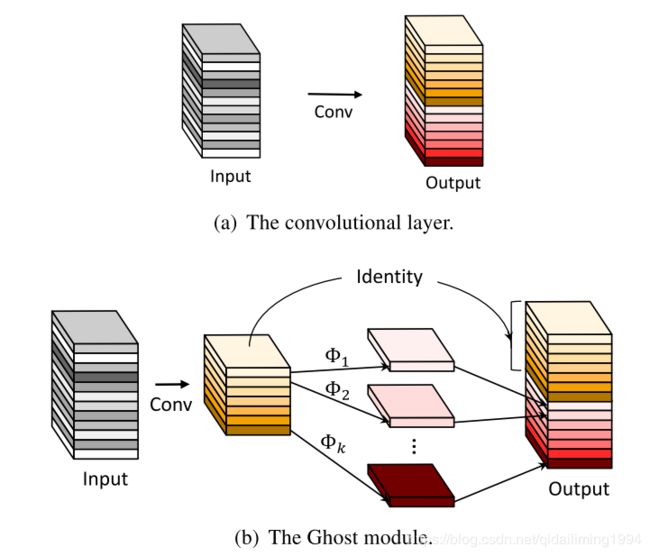
与普通卷积神经网络相比,在不更改输出特征图大小的情况下,其所需的参数总数和计算复杂度均已降低,而且即插即用。此外,而且出于效率考虑,Ghost模块中的初始卷积是点卷积(Pointwise Convolution)。
此模块对应代码:
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio) # 参考论文m = n/s
new_channels = init_channels*(ratio-1) # n(s-1)/s
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
primary_conv是预先卷积,他的输出通道数为 output_channel / ratio,然后是简单的线性变换cheap_operation,他是对预先卷积模块的每张特征图都做一遍卷积,因此他的groups就是init_channels,他输出通道数是new_channels。
这两个模块加在一起生成的通道数就是init方法里面定义的self.oup。前向传播部分就是先对输入张量预先卷积,然后对特征图做变换,最后concat到一起输出
2.与目前主流的卷积操作对比,Ghost模块有以下不同点:
对比Mobilenet、Squeezenet和Shufflenet中大量使用 pointwise卷积,Ghost模块的原始卷积可以自定义卷积核数量
目前大多数方法都是先做pointwise卷积降维,再用depthwise卷积进行特征提取,而Ghost则是先做原始卷积,再用简单的线性变换来获取更多特征
目前的方法中处理每个特征图大都使用depthwise卷积或shift操作,而Ghost模块使用线性变换,可以有很大的多样性
Ghost模块同时使用identity mapping来保持原有特征。
3.Ghost Bottleneck

Ghost Bottleneck(G-bneck)与residual block类似,主要由两个Ghost模块堆叠二次,第一个模块用于增加特征维度,增大的比例称为expansion ration,而第二个模块则用于减少特征维度,使其与shortcut一致。G-bneck包含stride=1和stride=2版本,对于stride=2,shortcut路径使用下采样层,并在Ghost模块中间插入stride=2的depthwise卷积。为了加速,Ghost模块的原始卷积均采用pointwise卷积
这里借鉴了MobileNetV2中的思路:第二个Ghost模块之后不使用ReLU,其他层在每层之后都应用了批量归一化(BN)和ReLU非线性激活。此外,而且出于效率考虑,Ghost模块中的初始卷积是点卷积(Pointwise Convolution)。
class GhostBottleneck(nn.Module):
def __init__(self, inp, hidden_dim, oup, kernel_size, stride, use_se):
super(GhostBottleneck, self).__init__()
assert stride in [1, 2]
self.conv = nn.Sequential(
# pw
GhostModule(inp, hidden_dim, kernel_size=1, relu=True),
# dw
depthwise_conv(hidden_dim, hidden_dim, kernel_size, stride, relu=False) if stride==2 else nn.Sequential(),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# pw-linear
GhostModule(hidden_dim, oup, kernel_size=1, relu=False),
)
if stride == 1 and inp == oup:
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
depthwise_conv(inp, inp, 3, stride, relu=True),
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
return self.conv(x) + self.shortcut(x)
4.GhostNet网络

基于Ghost bottleneck,GhostNet的结构如图7所示,将MobileNetV3的bottleneck block替换Ghost bottleneck,部分Ghost模块加入了SE模块。与MobileNetV3相比,这里用ReLU换掉了Hard-swish激活函数。