redis高可用的几种实现方式
redis高可用的几种实现方式
- 阅读提示
- 利用主从复制的方式实现高可用
- 什么是主从复制
- 主从复制的原理
- 主从复制的几大优缺点
- 主从复制的构建过程
- 利用哨兵的方式实现高可用
- 什么是哨兵
- 哨兵的原理
- 哨兵的几大优缺点
- 哨兵的构建流程
- 利用集群的方式实现高可用
- 什么是集群
- 集群的原理
- 集群的几大优缺点
- 集群的构建流程
阅读提示
以下的文章都是我对redis高可用的理解,并不能保证理解正确,只是为了做笔记,来记录当前我对redis的理解,希望以后在工作的时候,去真正去看redis的源码理解相应的实现,并且对以下的知识进行改正和完善。–文章会持续的修改
利用主从复制的方式实现高可用
什么是主从复制
主从复制:是由两种服务器组成,主服务器、从服务器,其实对于我们来说,其实都是一个服务器,只是相对来说状态不同而已。
主从复制的原理
先让我们看下一个主从复制的流程图吧,然后我们在一起去探讨下流程图的每一个步骤。
1. 从服务器向主服务器进行主从复制操作
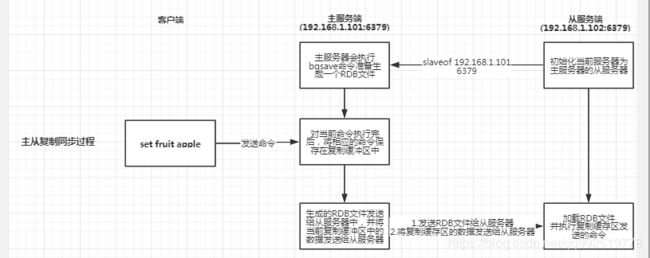
2. 从服务器向主服务器发送PING命令去保证正常连接
从服务器发送PING命令存在着几种情况:
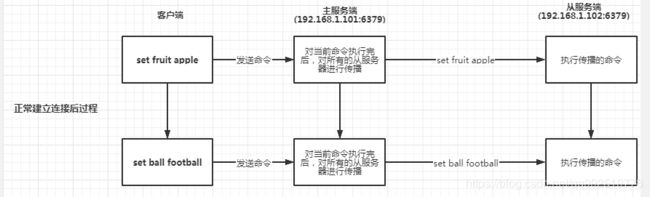
第一种情况:从服务器收到了主服务器的PONG命令,然后认为主服务器与从服务器的连接时有效的,那么他们就会进行以下正常的命令同步
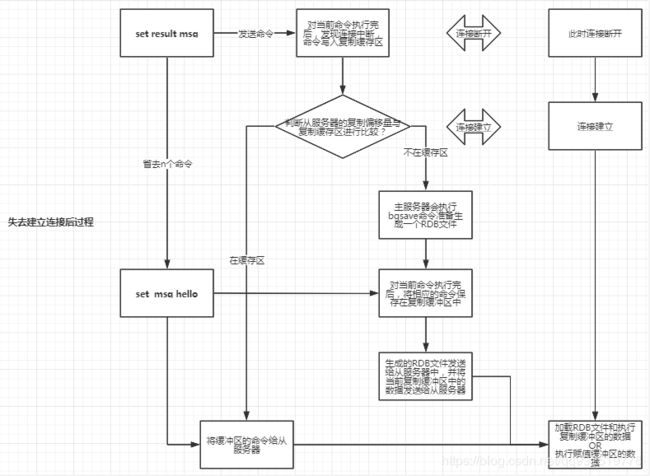
第二种情况:从服务器没收到主服务器的PONG命令或者是接受到了主服务器的错误报告,则从服务器则会进行重新与主服务器进行连接,此时主服务器认为与从服务器断开了连接。则在建立连接的过程中接受的命令,将会写入复制缓冲区中。
** 3.由上面说的第二种情况,从服务器断开连接,然后有命令往主服务器中写,所以我们主从服务器则需要进行补偿的措施。在建立与主服务器重新建立连接的时候,会判断从服务器的复制偏移量是否在复制缓冲区中。同样会存在两种情况:
第一种:不在复制缓存区中,主服务器则会执行bgsave命令生成RDB文件,并在bgsave命令执行过程中的所有的写命令会保存在缓冲区中。然后发送给从服务器。–被抽象成SYNC命令
第二种:在复制缓存区中,将当前缓存区中数据发送给从服务器。–被抽象成PSYNC
问题:就是在从服务器断开连接的时间段内,有着大量的写操作,缓存区中的缓存不够怎么办?
答:对于这个问题,我们建议根据需要去调整复制积压缓冲区的大小(redis.conf:repl-backlog-size),保证在从服务器的断开连接的时候,从服务器的复制偏移量在复制缓存区中存在,减少生成和发送RDB文件的系统资源的损耗。
问题遗留
问题1:生成RDB文件的时候,我们往往将RDB文件写入磁盘中,然后通过RDB文件发送到从服务器,磁盘IO非常慢的时候,有什么解决方法吗??
答:无盘复制,感兴趣的自己去了解下。
主从复制的几大优缺点
优点:利用主从复制的方式可以实现读写分离。Slave同样可以接受其它Slaves的连接和同步请求,这样可以有效的分载Master的同步压力。
缺点:Redis不具备自动容错和恢复功能,主机或者从机的宕机都会导致部分读写请求失败,需要等待机器重启才能恢复。
主机宕机,宕机前有部分数据未能及时同步到从机,还会引入数据不一致的问题,降低了系统的可用性。
Redis较难支持在线扩容,通过进行逻辑分区的方式进行扩容的方式。在集群容量达到上限时在线扩容会变得很复杂。
主从复制的构建过程
通过发送以下命令发送给从服务器,那么从服务器将会与主服务器建立主从复制
slaveof 192.168.1.1 6379
利用哨兵的方式实现高可用
什么是哨兵
通过几个哨兵服务器去监控实际提供业务的服务器,监控服务器的是否下线,去主动去进行故障转移操作,提供更高的可用性,同时提供更高的扩展性。
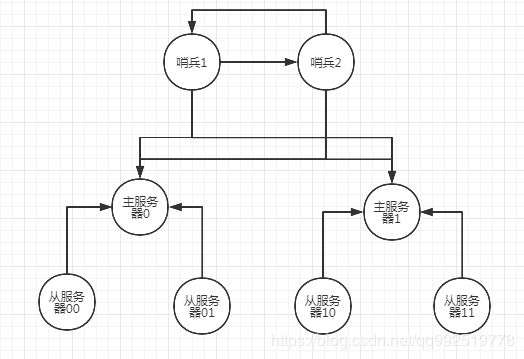
哨兵的原理
-
建立哨兵和主服务器的连接
前提条件:主服务器已经与从服务器建立了主从连接信息,建立主从看前面的文章逻辑。
1)由于在sentinel.conf配置文件中有配置其主服务器的ip和端口,那么哨兵服务器则会根据所有主服务器的ip和端口默认10秒一次发送INFO给所有的主服务器,并且主服务器会返回其当前主服务信息ip和端口等信息,以及所有从服务器的ip和端口等信息。
2)根据主服务器返回的所有从服务器的ip和端口等信息,建立与从服务器的联系,并默认10秒一次发送INFO给所有的从服务器。
3)从服务端返回当前服务器的ip和端口等信息
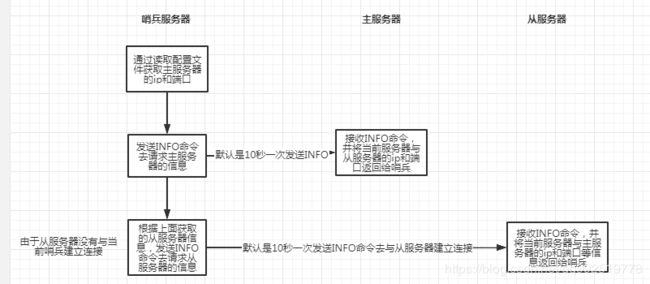
问题:为什么要10s一次去通过INFO命令去获取所有的主服务器和从服务器的ip和端口等信息呢?
答:因为从服务器与主服务器存在新增从服务器与主服务器的主从复制,这个时候可以动态的去获取主服务器和从服务器的ip和端口等信息。而且可以去获取所有的服务器的复制偏移量信息以及从服务器优先级信息等等。 -
建立哨兵和哨兵之间的连接
前提条件:每个哨兵服务器都会配置相应的主服务器信息,即会建立一个哨兵和所有主服务器和从服务器的连接信息。每个哨兵服务器都会默认定时2秒一次往每个主服务器和从服务器发送一条_sentinel__:hello事件的订阅信息且同时会订阅所有主服务器和从服务器的_sentinel__:hello事件的信息。
1)哨兵服务器02会收到哨兵服务器01的发布的信息,即哨兵服务器01发送的信息是当前服务器的ip和端口等其他信息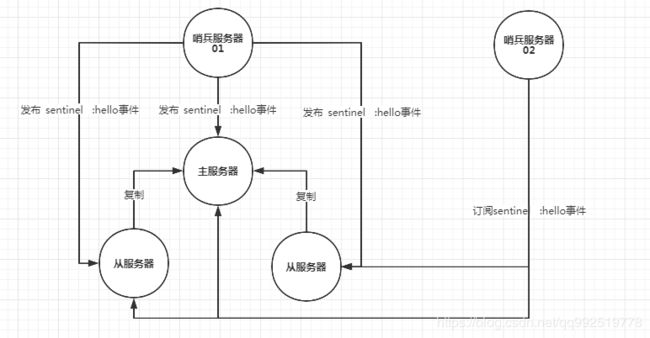
2)哨兵服务器02会收到哨兵服务器01发布的消息,然后创建与哨兵服务器01的命令连接。
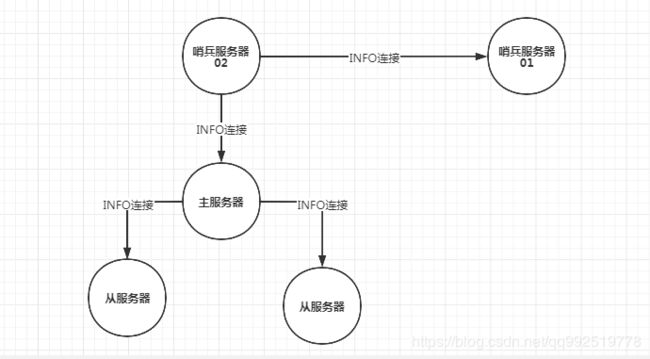
-
服务器出现故障,进行故障转移
此处就不画图了。。。
首先怎么判定主服务器出现了故障呢?
默认是1秒一次的频率通过发送PING命令的方式去检测(心跳检测)
1)上面检测的时候,主服务器在配置的down-after-milliseconds时间长度内没有返回响应,则认为主观下线。
2)然后向同样监视当前主服务器的哨兵服务器询问,看他们是否也以为此主服务器同样是主观下线呢?当收到了仲裁数目的节点数目的同样观点,那么认为是客观下线。
3)由流程2知道,由于足够数量的哨兵认为主服务器客观下线了,这个哨兵服务器对各个哨兵进行协商,选举出领头哨兵。
4)选举出领头哨兵(每个哨兵都会发送一个命令给所有的哨兵,说选我为领头羊,那么就是先到先得的方式获取投票),然后该哨兵去进行故障转移操作。
4.1)主服务器下面的从服务器中选举出来一个服务器当做主服务器
4.2)将其他所有的从服务器当做新主服务器的从服务器
4.3)将原来的主服务器当做此新主服务器的从服务器
4.客户端访问哨兵组成的服务器
我们通过springboot的配置来去做访问逻辑的描述
#配置所有哨兵的节点
spring.redis.sentinel.nodes=192.168.1.112:26379,192.168.1.112:26479,192.168.1.112:26579
#配置当前服务器需要关注的那个集群的主服务器
spring.redis.sentinel.master=mymaster
疑问:为什么在哨兵启动的时候会存在两个主服务器呢?
答:当然,哨兵不只会监听一个主服务器的,但是我们访问的时候只能去访问一个主服务器。这个是不是有点绕,就是说,两个主服务器是不能共通的,但是哨兵可以监视的。
哨兵的几大优缺点
优点:实现了自动的故障转移,具有高可用的特性。
缺点:Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
哨兵的构建流程
- 搭建哨兵服务器
方法一:redis-sentinel /path/to/sentinel.conf
方法二:redis-server /path/to/sentinel.conf --sentinel
- 配置主服务器
##配置监听的主服务器的ip和端口、仲裁数目(用于实现故障转移的时候,认同某个主服务器下线的哨兵数目,用于哨兵选举出leader进行故障转移)
sentinel monitor mymaster 127.0.0.1 6379 2
##配置认为主观下线的时长为60s
sentinel down-after-milliseconds mymaster 60000
##执行故障转移操作的超时时间180s
sentinel failover-timeout mymaster 180000
##设置故障转移的时候,进行复制新主服务器的从服务器的数目
sentinel parallel-syncs mymaster 1
##另一个主服务器
sentinel monitor resque 192.168.1.3 6380 4
sentinel down-after-milliseconds resque 10000
sentinel failover-timeout resque 180000
sentinel parallel-syncs resque 5
利用集群的方式实现高可用
什么是集群
集群是通过分片来进行数据共享,并提供复制和故障转移功能。
集群的原理
集群是由多个节点组合而成。每个节点分配了16384个槽,只有16384个槽全部分配完成,则此集群则为上线状态,否则为下线状态。
问题:为什么是16384个槽呢?
答:https://www.cnblogs.com/rjzheng/p/11430592.html
1.槽分配的方式
1)通过命令的方式分配槽
cluster addslots [slot …]
cluster addslots 1 2 3 … 5000
2)通过ruby和redis-trib.rb去分配槽
大佬们去网上查询资料,有很多
2.计算键指示的是哪个槽
通过CRC16(key)语句用于计算键key的CRC-16校验和,而&16383语句则算出一个0~16383中的某一个槽
3.在集群中执行命令
判断当前槽是否是由我负责的节点,如果是由我负责的节点,则返回相应的数据。如果不是由我负责的节点,则将这个槽负责的节点的ip和端口号给客户端,
并返回MOVED错误,此时客户端会根据返回的MOVE命令,重新发送原来的命令给特定的客户端,则返回相应的响应结果。
问题:同样我们思考下,数据库服务怎么实现的?
答:集群的节点只能使用0号数据库,而单机可以创建任何数量的数据库。我们上面说了,每个服务端都存储着自己的槽节点负责的服务器和其他节点的槽节点负责的服务器。且每个节点的服务器都保存了多个从节点的信息,同时每个服务器都存在着槽和所负责的key的映射关系(跳跃表)
4.重新分片
1)准备需要分配给其他节点槽对应的键数据
2)然后按照一定数量的槽节点的键数据发送到目的节点 ,直到所有的槽节点的数据发送给目的节点
3)然后通过发送指派新的槽信息发送至整个集群
问题:如果发送到另一个节点,槽节点的数据发送期间,当前节点服务器怎么处理?
存在两种情况,槽的键在当前节点,还没有移到目的节点或者在移动到目的节点中,此时怎么处理?槽的键已经移到目的节点,此时怎么处理?
其实上面两种情况,服务器都会进行去判断当前槽是否是否属于当前节点的槽,如果否,则回复MOVE命令,并将ip和端口返回;是,则判断当前的key是否存在,存在,则判断当前节点是否在进行重新分片,如果在进行重新分片,那么判断当前的key是否找到,找到了话,则返回,没找到的话,则返回ASK错误,返回ip和端口。客户端则同样会对ASK进行隐藏,则会发送相同的命令给相应的ip和端口。
5.故障转移
判断一个主节点是否故障,每个节点都会给所有的节点发送ping命令,来判断某个节点是否在指定时间内收到响应,如果在指定时间内未收到响应,则标记该节点为疑似下线。集群中的节点都会相互发送消息的方式来交换集群中的节点状态信息。半数以上负责处理槽的主节点认为该主节点为疑似下线,那么将这个主节点标记为已下线。并且向集群中广播,说当前节点已经下线了,接到当前命令的节点,将会把当前节点标记为已下线。那么需要进行故障转移操作,从原来主节点中的从节点中进行选举(主节点拥有选举权),选举出来一个主节点,然后其他从节点当做当前主节点的从节点。并且发送消息发送给集群,声明当前节点替换原来的主节点。
集群的几大优缺点
参考于:https://stor.51cto.com/art/201910/604653.htm
优点:
数据按照 slot 存储分布在多个节点,节点间数据共享,可动态调整数据分布;
可扩展性:可线性扩展到 1000 多个节点,节点可动态添加或删除;
高可用性:部分节点不可用时,集群仍可用。通过增加 Slave 做 standby 数据副本,能够实现故障自动 failover,节点之间通过 gossip 协议交换状态信息,用投票机制完成 Slave 到 Master 的角色提升;
降低运维成本:提高系统的扩展性和可用性。
缺点:
Client 实现复杂,驱动要求实现 Smart Client,缓存 slots mapping 信息并及时更新,提高了开发难度,客户端的不成熟影响业务的稳定性。目前仅 JedisCluster 相对成熟,异常处理部分还不完善,比如常见的“max redirect exception”。
节点会因为某些原因发生阻塞(阻塞时间大于 clutser-node-timeout),被判断下线,这种 failover 是没有必要的。
数据通过异步复制,不保证数据的强一致性。
多个业务使用同一套集群时,无法根据统计区分冷热数据,资源隔离性较差,容易出现相互影响的情况。
Slave 在集群中充当“冷备”,不能缓解读压力,当然可以通过 SDK 的合理设计来提高 Slave 资源的利用率。
Key 批量操作限制,如使用 mset、mget 目前只支持具有相同 slot 值的 Key 执行批量操作。对于映射为不同 slot 值的 Key 由于 Keys 不支持跨 slot 查询,所以执行 mset、mget、sunion 等操作支持不友好。
Key 事务操作支持有限,只支持多 key 在同一节点上的事务操作,当多个 Key 分布于不同的节点上时无法使用事务功能。
Key 作为数据分区的最小粒度,不能将一个很大的键值对象如 hash、list 等映射到不同的节点。
不支持多数据库空间,单机下的 redis 可以支持到 16 个数据库,集群模式下只能使用 1 个数据库空间,即 db 0。
复制结构只支持一层,从节点只能复制主节点,不支持嵌套树状复制结构。
避免产生 hot-key,导致主库节点成为系统的短板。
避免产生 big-key,导致网卡撑爆、慢查询等。
重试时间应该大于 cluster-node-time 时间。
Redis Cluster 不建议使用 pipeline 和 multi-keys 操作,减少 max redirect 产生的场景。
集群的构建流程
1.搭建集群
1.首先要开启集群
修改redis.conf文件的 cluster-enable yes去开启集群的模式
2.然后启动节点,修改redis.conf的port端口为7000
redis-server redis.conf
3.通过发送命令:
127.0.0.1:7000>cluster meet 127.0.0.1 7001 #将服务器的7001添加到7000的集群中
127.0.0.1:7000>cluster meet 127.0.0.1 7002 #强服务器的7002添加到7000的集群中
127.0.0.1:7000> cluster nodes ##查询当前的集群中所有节点
29c895f205b15e83ee27abbc15b601174d81bb5e 127.0.0.1:7001@17001 master - 0 1586774373662 1 connected 164 1890 2765 2964 3386 3954 4980 6168 6204 7307 9842 10333 10335 11149 12291 12539 13711 15018
d8ce276604e250b2cbbea17661c0746decb7a1f3 127.0.0.1:7000@17000 myself,slave 29c895f205b15e83ee27abbc15b601174d81bb5e 0 1586774372000 0 connected
e45f1104516c1106cb23dded1d272b57426e8893 127.0.0.1:7002@17002 slave 29c895f205b15e83ee27abbc15b601174d81bb5e 0 1586774372660 1 connected
4.此时7000/7001/7002中还没有分配槽,所以需要进行槽指派操作,并将所有的16384个槽指派给7000/7001/7002服务器
127.0.0.1:7000>cluster addslots 1 2 3 .... 5000
127.0.0.1:7001>cluster addslots 5001 5002 5003 .... 10000
127.0.0.1:7001>cluster addslots 10001 10002 10003 .... 16384