参考:《深度学习图像识别技术--基于TensorFlow Object Detection API 和 OpenVINO》
Estimators--是 TensorFlow 高级抽象API,它极大的简化了机器学习编程。Estimators 封装了下列功能:
训练(training)
评估(evaluation)
预测(prediction)
导出(export for serving)
让机器学习开发者可以专注于模型相关工作。
所有的 Estimators 无论是TensorFlow预先做好(pre-made)的还是用户自定义(custom)的,都是基于 tf.estimator.Estimator 类的类。
TensorFlow 提供了一些 pre-made Estimators 用于实现常规的机器学习算法,这些Pre-made Estimators有:DNNClassifier、 LinearClassifier、DNNLinearCombinedClassifier、DNNRegressor、 LinearRegressor、DNNLinearCombinedRegressor,如下图所示:
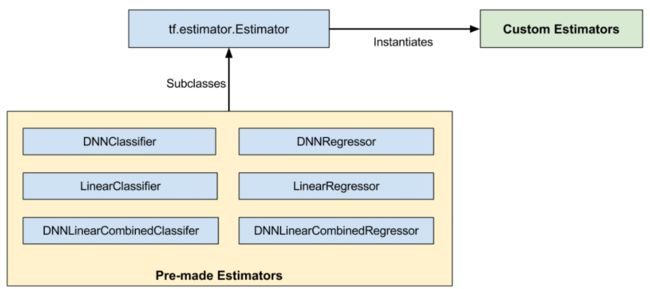
初学机器学习的时候,TensorFlow建议先使用 pre-made Estimators。在获得Estimator的相关专业知识和技能后,再用自己创建的自定义Estimator来优化模型。
基于pre-made Estimators类编写TensorFlow程序, 请依次实现下列功能:
1,创建一个或多个输入函数。
2,定义模型的特征列(feature columns)。
3,初始化Estimator, 指定特征列和各种必需的超参数(hyperparameters)。
4,调用Estimator对象上的方法,把相应的输入函数作为数据源传入。
下面本文依次讲述如何按照上面的步骤实现 Iris 分类
第一步:创建输入函数。
创建输入函数是为了训练、评估和预测工作提供数据。TensorFlow中,输入函数定义如下:
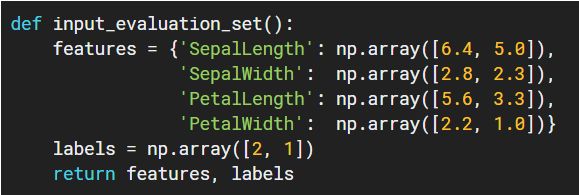
输入函数是一个返回类型为 tf.data.Dataset 对象,该对象输出一个包含特征值和标签的两元素元素(two-element tuple),例如:
为了便于后续模型使用数据,TensorFlow建议使用TensorFlow Dataset API创建输入函数TensorFlow Dataset类,包含TextLineDataset、TFRecordDataset和FixedLengthRecordDataset三个子类。Dataset类通过Iterator类实现数据的访问。
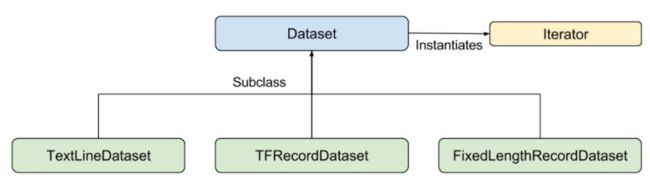
Dataset - 基类,包含创建和转换(transform) dataset的方法,允许你从内存中的数据初始化一个数据集(dataset)
TextLineDataset - 从文本文件(text file)中,按行读取数据
TFRecordDataset - 从TFRecord 文件(TFRecord files)中读取数据.
FixedLengthRecordDataset - 从二进制文件(binary files)中,读取固定长度的数据
Iterator - 提供一个每次访问数据集中一个元素的方法
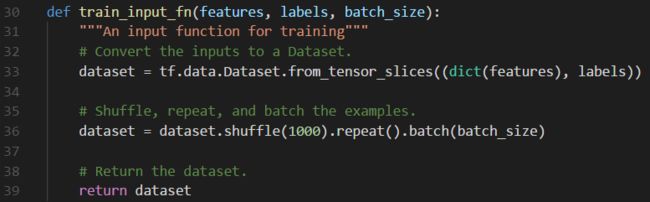
打开iris_data.py文件,可以看到一个使用dataset API编写的输入函数的范例,如下:
第二步,定义特征列(feature columns)
feature column 是一个用于描述模型如何从特征字典中使用原始输入数据的对象。当创建了一个Estimator模型后,接下来就要给模型传入一个特征列,这个特征列告诉模型如何使用特征。
对于 Iris 分类问题来说, 4个原始特征都是数值型的值,如下所示:
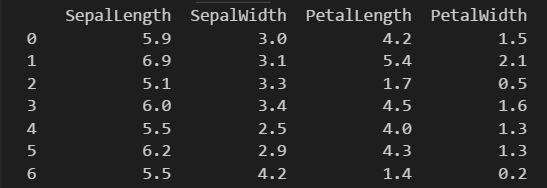
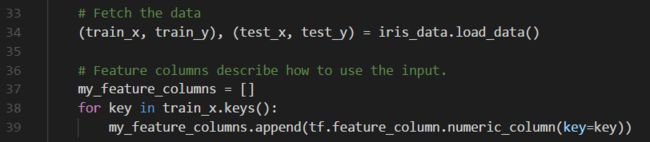
由此,我们创建一个特征列列表,告诉Estimator模型,特征由四个32位浮点数类型的数值组成,程序如下所示:
用print(my_feature_colunms)把my_feature_colunms信息打印出来,如下:

这就是即将传给Estimator的特征列信息
注意:train_x是一个DataFrame对象,对DataFrame概念和操作不熟悉的,请看《Pandas入门4 -- DataFrame类及创建》,《Pandas入门5 -- DataFrame基本操作1》和《Pandas入门6 -- DataFrame基本操作2》
第三步,初始化Estimator
鸢尾花(Iris)分类是一个经典的分类问题。幸运的是, TensorFlow 提供好几种预先做好的分类器,包括:
tf.estimator.DNNClassifier 用于辨识多种类型的深度模型分类器
tf.estimator.DNNLinearCombinedClassifier 用于宽度&深度模型分类器
tf.estimator.LinearClassifier 基于线性模型的分类器
对于鸢尾花(Iris)分类问题, tf.estimator.DNNClassifier 是最合适的,由此,初始化这个Estimator:

第四步,训练模型
通过调用Estimator的train方法实现模型训练,如下:

按照Estimator输入参数要求,用lambda表达式传入输入函数;steps参数告诉train方法,经过多少训练步骤后停下。
第五步,评估模型
通过调用Estimator的evaluate方法实现模型训练,如下:

评估模型只需要运行一个训练周期(Epoch),所以不需要输入训练步数。
第六步,用训练好的模型做预测
通过调用Estimator的predict方法实现模型训练,如下:
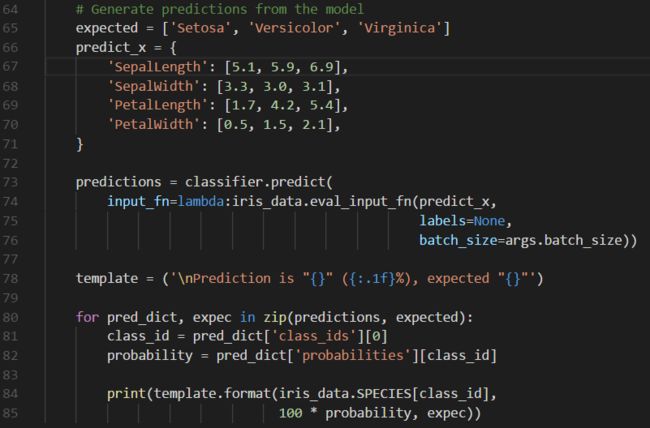
predict 方法会返回一个 Python字典(dictionary), 包含每个样本的预测结果predictions,如下所示:

"probabilities" 表示预测的概率值;“class_ids”表示预测类型的id。
总结:
使用TensorFlow自带的Estimators类编程是一个非常有效且快速的创建标准模型的方法。 进一步学习:
Checkpoints 学习如何保存和恢复模型
Datasets 学习如何向模型导入数据
Creating Custom Estimators 学习如何创建自定义的Esitmator.