论文笔记8【Re-ID】Masked Graph Attention Network for Person Re-identification
Paper: Masked Graph Attention Network for Person Re-identification
Code(暂无)
Abstract
主流的人再识别方法(ReID)主要关注个体样本图像与标签之间的对应关系,而忽略了整个样本集中丰富的全局互信息。为此,我们提出了一种掩码图注意网络(MGAT)方法。MGAT利用所提取的特征信息构建完整的图,节点在标签信息的引导下以掩模矩阵的形式定向地关注其他节点的特征。利用MGAT模块,将之前忽略的全局互信息转化为具有更强鉴别能力的优化特征空间。同时,我们建议将MGAT模块学习到的优化信息反馈到特征嵌入网络中,以增强映射的可扩展性,从而避免测试阶段大规模图数据处理的困难。为了评价我们的方法,我们在三个常用的reid数据集上进行了实验。结果表明,我们的方法优于大多数主流方法,并与最先进的方法具有很强的可比性。
Introduction
人再识别(ReID)的目标是匹配来自多个非重叠摄像机的不同轨迹的行人。由于其在监测[29]、活动分析[19]和跟踪[38]等方面的重要应用,近年来受到越来越多的关注。尽管这个任务很重要,但它仍然是一个具有挑战性的问题,因为在摄像机视点、人类姿势、光线、遮挡和背景混乱方面存在复杂的变化。
然而,如图1所示,目前主流的方法学习特征嵌入网络时,都是对单个特征的类标签进行独立估计,而忽略了特征之间丰富的相互信息驻留在所有特征构造的整个图特征。换句话说,他们只注意特性的分类特征表示的特性在多大程度上对应正确的标签,而集群的特征特性未能得到尽可能多的关注,这表明大大同一个类的特点是如何聚集和不同阶层的特点是分离。判别分析表明,判别特征越多,聚类特征越好,而现有的聚类方法很少考虑这一点。
这里有几种现有的方法试图克服这一缺陷,如流形学习[3,18]和重新排序[44,9,35]。它们都能利用互信息来改善特征空间的聚类特性。但是正如Yantao等人在[23]中总结的那样,它们都有两个主要的局限性“:一是大多数的人工学习和重新排序方法都是弱监督或无监督的,不能充分利用提供的训练标签到学习过程中。另一种是这两种方法不涉及训练过程,对特征学习没有好处。
新兴的图数据注意网络(GATs)[26]显示了它**利用节点间相互信息来改进聚类特性的潜力,**因为它具有从其他节点特征中聚集信息的内在能力。GATs成功地将注意力机制引入到图神经网络(GNNs)[21]中,通过这种机制,节点能够关注其邻域特征,并为邻域内的不同节点指定不同的权重。更重要的是,它不需要计算密集型的矩阵运算。然而,传统的GATs只利用没有标签信息的节点的相对重要性,虽然可以聚集相似的节点,但是很难直接分离不同类别的节点。
我们提出了一种新的GATs扩展,称为掩码图注意网络(MGAT),以利用特征之间丰富的互信息。MGAT的核心在于创新的节点更新掩蔽注意机制,这与传统的GATs不同,后者仅通过注意矩阵聚集相似的节点。具体来说,我们首先将特征嵌入网络学习到的特征转化为一个完整的图。然后我们的MGAT使用一个注意矩阵来提供更新的权值,并使用一个带标签信息的掩模矩阵来决定更新的方向(例如,将同一个类的节点拉近或推不同类的节点)。因此,这些特征最后得到了一个改进的聚类特征。
通过识别损失直接监督MGAT的优化输出特征,保证分类特征。此外,从MGAT得到的优化信息进一步反馈到损失的原始特征和优化反馈。其目的是增强特征嵌入网络的映射能力,避免重新排序等任何后端或非端端过程。
Related work
person reid
graph convolution network
许多计算机视觉任务所涉及的数据无法用通常使用的网格状结构(如图形)表示。在[21]中引入GNNs是作为递归神经网络的推广,它可以直接处理更一般的图。
Petar Velickovic等人在[26]中引入了一种基于注意力的体系结构,名为Graph Attention Net- works (GATs),它直接作用于图,利用掩蔽的自我注意力层来解决先前基于图卷积或其近似的方法的缺点。通过堆叠层,其中的节点能够关注它们的邻域特征,从而可以在不需要任何计算密集型矩阵操作或预先了解图形结构的情况下,对一个邻域内的不同节点随意指定不同的权重。
Method
在本节中,我们将介绍与之集成的MGAT
用于ReID任务的ResNet50[10]基线。我们首先描述了整个网络的架构,然后详细阐述了MGAT模块的设计和损耗
Overview
管道如图2中左边所示。该框架主要由三个部分组成,第一部分是特征提取,接下来是基于该框架的特征操作优化。利用损失将倾斜的优化信息反馈给CNN(特征嵌入网络)。
 对于一小批图像,我们首先用CNN提取一组特征X,其中每个特征都唯一地反映了对应图像的视觉信息。将特征集视为节点集,构造一个完整的图,图上的每个边字符表示连接节点(包括自连接)之间的相似性。受[30]的启发,相似函数可以用多种方法实现。
对于一小批图像,我们首先用CNN提取一组特征X,其中每个特征都唯一地反映了对应图像的视觉信息。将特征集视为节点集,构造一个完整的图,图上的每个边字符表示连接节点(包括自连接)之间的相似性。受[30]的启发,相似函数可以用多种方法实现。
然后将构建的图输入到提出的MGAT中进行优化。需要注意的是,MGAT的输出特征X '直接受到识别损失的监督,以保证分类的特性。
同时引入损失的概念来约束输出特征与原始特征之间的差异。将MGAT学习到的优化信息反馈到特征嵌入网络中,使特征嵌入网络无需在测试阶段使用MGAT或任何后处理方法即可直接生成优化的特征。探查集和图库集总是非常大,将它们作为图直接处理是低效的甚至不可能的。
总体而言,整个网络架构的原则是利用所提出的MGAT所获得的优化信息,增强特征嵌入网络的学习能力,从而为ReID任务找到更有鉴别能力的特征空间。
Mask GAN
MGAT的设计是为了解决人员重新识别的场景,该场景忽略了大量有价值的相互信息,从而获得最优的聚类特征。MGAT的注意结构与[26]中的注意结构类似,也遵循了Bahdanau等人[2]的注意结构,但注意机制不同。我们首先描述了MGAT的输入和输出,然后重点构建了有趣的掩蔽注意机制。
MGAT的输入是CNN提取的一组特征(即我们实现中的ResNet50)
X = {~ X 1,~ X 2,···,~ X N},~ X i∈R d,其中N为特征数,d为单个特征的维数。提出的MGAT生成一组新的优化特征X = {~ X 1,~ X 2,···,~ X N},~ X i R d作为输出。
从而利用优化后的特征对原始数据进行进一步的监督特征。
我们指定输出的维数与输入的维数相同,即d ’ = d。
MGAT对数据进行图形化处理。将输入特征集X作为节点集,任意两个节点之间的距离作为边集E,构造一个完备图G(X,E)。在我们的实现中,我们使用欧氏距离来确定两个节点~ xi和~ xj之间的边e。
MGAT的核心在于其创新的掩蔽注意机制。在边缘上进行了专门的设计,以达到提高聚类特性的目的,即基于注意的方式对同类节点进行聚集,对不同类节点进行分离。具体来说,我们的掩码注意机制包括两个主要组件,即注意矩阵A和掩码矩阵M,如图2所示。
Attention M
注意机制通常用来揭示两个特征之间的相对重要性。在我们的图中,由于两个节点之间的关系是由边唯一决定的,我们可以简单地定义一个注意函数f: R→R来将边映射到注意。在实践中,我们将注意力定义为
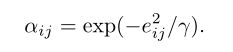 在上面的αij指定第j节点的相对重要性的第i个节点, 和γ是一个超参数,有助于地图的关注在一个小范围内接近于零。
在上面的αij指定第j节点的相对重要性的第i个节点, 和γ是一个超参数,有助于地图的关注在一个小范围内接近于零。
我们可以观察到,越短的边缘,越高的注意。注意,在许多GCNs实现中,为了集成图数据结构,节点通常考虑相邻一阶域内节点的影响。然而,由于我们构造的图是一个完整的图,它只包含一小批特征,因此我们可以计算每个节点与所有其他节点的注意力,以捕获全局信息,而不必担心计算复杂性。为了使不同节点之间的关系更加密切,我们对节点进行L1归一化处理。
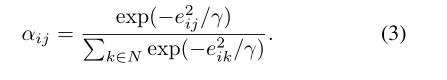 对于一个包含N张图像的小批处理,我们可以得到一个行标准化的N×N注意矩阵a,其中第i个节点对所有节点的注意值作为第i行。
对于一个包含N张图像的小批处理,我们可以得到一个行标准化的N×N注意矩阵a,其中第i个节点对所有节点的注意值作为第i行。
Mask Matrix
注意矩阵代表了图表信息的相互重要性,传统算法和GATs利用这个信息来更新节点,因为他们假设图中连接的节点可能共享相同的标签[13]。然而,这种假设可能会限制建模能力,因为它只考虑了相似性,而忽略了差异性。它不能处理硬样本。
为了解决这个问题,我们单独使用注意矩阵,引入一个掩码矩阵来决定我们将节点聚合到哪个方向(以缩短或延长边缘)。例如,我们用相同的标签缩短节点之间的边,而用另一种传统的方式延长边。更具体地说,我们使用的N-size迷你批处理包含M个人员身份,每个身份有K个图像,其中的标签分布具有以下结构:

 掩码矩阵的作用是作为一个注意掩码,当元素明智地与注意矩阵相乘时,它确保同类节点之间的注意值是正的,而来自不同类的节点之间的注意值是负的。这样,同一类的节点间的相似度增加(短边),而不同类的节点间的相似度减少(长边)。简而言之,掩码矩阵将节点标签所携带的信息转化为注意监督,从而达到优化的聚类特性。
掩码矩阵的作用是作为一个注意掩码,当元素明智地与注意矩阵相乘时,它确保同类节点之间的注意值是正的,而来自不同类的节点之间的注意值是负的。这样,同一类的节点间的相似度增加(短边),而不同类的节点间的相似度减少(长边)。简而言之,掩码矩阵将节点标签所携带的信息转化为注意监督,从而达到优化的聚类特性。
有一个疑问,负掩模会破坏归一化结果,但实际上归一化在这里的作用是使注意值具有可比性,而这样的操作也有权值衰减的效果。
节点更新
将特征集X和X表示为X, X表示为矩阵形式。更新时,回顾传统的GATs仅利用注意矩阵A,通过线性组合得到节点的输出特征。
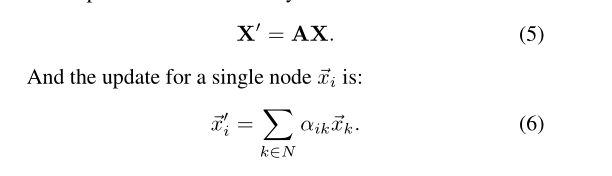
在我们的工作中,通过引入一个额外的掩码ma- trix M,我们得到了标签监督定向信息来处理节点特征的聚类特性。输出的表达式如下:
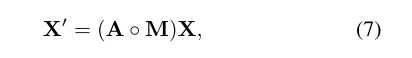 同样,单个节点的更新为:
同样,单个节点的更新为:
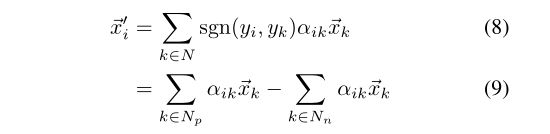
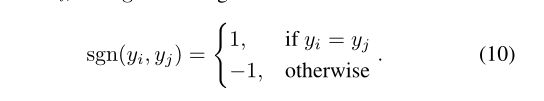
MGAT与传统GATs的节点更新过程如图3所示。请注意,卷积GATs使用注意值来计算相应节点特征的线性组合作为最终的输出节点特征,而不涉及标签监督来直接分离不同类别的节点。作为比较,给定掩模矩阵的掩模信息,我们的MGAT对不同类别的节点应用不同的注意处理。
OFLoss
正如3.1节所提到的,在测试阶段将探测集和图库集作为图来处理总是不好的。我们提出利用损耗的方法使CNN能够直接生成最优的特征。我们采用最简单的实现方法,即使用均方误差(MSE)损失来约束MGAT的输出特性与原始有限元之间的差异。

需要注意的是,损耗是MGAT增强CNN学习的一个辅助组件,为了避免在测试阶段进行大量的图形构建工作,所以我们没有独立研究损耗对最终结果的影响。