KafkaConsumer使用介绍、参数配置
文章目录
- 前言
- Consumer概要
- Consumer程序开发
- Consumer常用参数说明
- 消息解序列化
- 多线程处理
- 总结
前言
KafkaProducer作为生产者发送消息到Kafka,那么自然也就需要从kafka读取消息,这就是KafkaConsumer,通过和Producer使用相同的topic约定来消费指定数据,使用kakfa就是缓冲消息,消费端才是处理消息的中心,数据处理的业务逻辑都在消费者,下面就来看Consumer是如何设计以及消费数据的
Consumer概要
首先我们需要明确consumer中的几个关键术语
消费者(consumer):从kafka中拉取数据并进行处理
消费者组(consumer group):一个消费者组由一个或者多个consumer实例组成
位移(offset):记录当前分区消费数据的位置
位移提交(offset commit):将消费完成的消息的最大offset提交确认
位移topic(_consumer_offset):保存消费位移的topic
消费过程图解
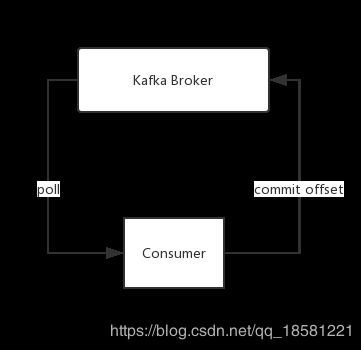
Consumer从Kafka Broker上拉取(poll)数据,然后再提交位移信息(Commit Offset)
Consumer程序开发
构建Consumer
Consumer有三种消费交付语义
1、至少一次:消息不会丢失,但可能被重复处理(实现简单)
2、最多一次:消息可能丢失可能会被处理,但最多只会被处理一次(实现简单)
3、精确一次:消息被处理并且只会被处理一次(比较难实现)
提交位移方式
- 自动提交 :实现最简单,只需要在参数 enable.auto.commit 设置为 true,既可能重复消费,也可能丢失数据
package com.huawei.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
* @author: [email protected]
* @date: 2019/4/26 13:08
* @description:
*/
public class AutoCommitConsumer {
private static Properties props = new Properties();
static {
props.put("bootstrap.servers", "192.168.142.139:9092");
props.put("group.id", "Test");
props.put("enable.auto.commit", true);//设置是否为自动提交
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
}
final KafkaConsumer<String, String> consumer;
private volatile boolean isRunning = true;
public AutoCommitConsumer(String topicName) {
consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topicName));
}
public void printReceiveMsg() {
try {
while (isRunning) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println("TopicName: " + consumerRecord.topic() + " Partition:" +
consumerRecord.partition() + " Offset:" + consumerRecord.offset() + "" +
" Msg:" + consumerRecord.value());
//进行逻辑处理
}
}
}
}catch (Exception e){
//处理异常
}
finally {
close();
}
}
public void close() {
isRunning = false;
if (consumer != null) {
consumer.close();
}
}
}
- 手动提交
手动提交又分为两种提交方式(同步提交和异步提交)
(1)同步提交
package com.huawei.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
* @author: [email protected]
* @date: 2019/4/27 13:13
* @description:
*/
public class SyncCommitConsumer {
private static Properties props = new Properties();
static {
props.put("bootstrap.servers", "192.168.142.139:9092");
props.put("group.id", "Test");
props.put("enable.auto.commit", false);//注意这里设置为手动提交方式
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
}
final KafkaConsumer<String, String> consumer;
private volatile boolean isRunning = true;
public SyncCommitConsumer(String topicName) {
consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topicName));
}
public void printReceiveMsg() {
try {
while (isRunning) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println("TopicName: " + consumerRecord.topic() + " Partition:" +
consumerRecord.partition() + " Offset:" + consumerRecord.offset() + "" +
" Msg:" + consumerRecord.value());
//进行逻辑处理
}
consumer.commitSync();//同步提交
}
}
}catch (Exception e){
//处理异常
}
finally {
consumer.commitSync();
close();
}
}
public void close() {
isRunning = false;
if (consumer != null) {
consumer.close();
}
}
}
(2)异步提交
package com.huawei.kafka.consumer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
* @author: [email protected]
* @date: 2019/4/27 13:16
* @description:
*/
public class AsyncCommitConsumer {
private static Properties props = new Properties();
static {
props.put("bootstrap.servers", "192.168.142.139:9092");
props.put("group.id", "Test");
props.put("enable.auto.commit", false);//注意这里设置为手动提交方式
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
}
final KafkaConsumer<String, String> consumer;
private volatile boolean isRunning = true;
public AsyncCommitConsumer(String topicName) {
consumer = new KafkaConsumer<String, String>(props);
consumer.subscribe(Arrays.asList(topicName));
}
public void printReceiveMsg() {
try {
while (isRunning) {
ConsumerRecords<String, String> consumerRecords = consumer.poll(Duration.ofSeconds(1));
if (!consumerRecords.isEmpty()) {
for (ConsumerRecord<String, String> consumerRecord : consumerRecords) {
System.out.println("TopicName: " + consumerRecord.topic() + " Partition:" +
consumerRecord.partition() + " Offset:" + consumerRecord.offset() + "" +
" Msg:" + consumerRecord.value());
//进行逻辑处理
}
consumer.commitAsync();//异步提交
}
}
}catch (Exception e){
//处理异常
}
finally {
consumer.commitAsync();
close();
}
}
public void close() {
isRunning = false;
if (consumer != null) {
consumer.close();
}
}
}
Consumer常用参数说明
bootstrap.servers:Kafka群集信息列表,用于连接kafka集群,如果集群中机器数很多,只需要指定部分的机器主机的信息即可,不管指定多少台
group. id:标识一个consumer组的名称
key.deserializer:消息key反序列化器
value.deserializer:消息value反序列化器
session .timeout.ms:消费者和群组协调器的最大心跳时间,如果超过该时间则认为该消费者已经死亡或者故障,需要提出消费者组
max.poll.interval .ms:一次poll间隔最大时间
auto.offset.reset:当消费者读取偏移量无效的情况下,需要重置消费起始位置,默认为latest(从消费者启动后生成的记录),另外一个选项值是 earliest,将从有效的最小位移位置开始消费
enable.auto.commit:consumer提交方式设置
fetch.max.bytes:consumer端一次拉取数据的最大字节数
max.poll.records:consumer端一次拉取数据的最大条数
connections.max.idle .ms:consumer默认和kafka broker建立长连接,当连接空闲时间超过该参数设置的值,那么将连接断开,当使用时,在进行重新连接
消息解序列化
consumer消息解序列化与producer消息序列化是一个操作对,在producer使用什么方式序列化,consumer端就要使用对应的解序列化方式进行消息反解
- 默认解序列化
- 自定义解序列化:可以通过org.apache.kafka.common.serialization.Serializer来自定义序列化器
多线程处理
consumer并不是线程安全的类,如果在多线程下使用将抛出异常,可以在单线程中使用consumer,具体的消费逻辑委托到多线程中进行执行
总结
该文档主要介绍了consumer的简单使用以及参数介绍,kafka consumer具有很高的吞吐量,不适合消费耗时很长的逻辑,会严重影响消费性能。